JavaеҶ…еӯҳжЁЎеһӢзҡ„еҺҹзҗҶжҳҜд»Җд№Ҳ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іJavaеҶ…еӯҳжЁЎеһӢзҡ„еҺҹзҗҶжҳҜд»Җд№ҲпјҢж–Үз« еҶ…е®№иҙЁйҮҸиҫғй«ҳпјҢеӣ жӯӨе°Ҹзј–еҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҜ№зӣёе…ізҹҘиҜҶжңүдёҖе®ҡзҡ„дәҶи§ЈгҖӮ
жүҖжңүзҡ„зј–зЁӢиҜӯиЁҖдёӯйғҪжңүеҶ…еӯҳжЁЎеһӢиҝҷдёӘжҰӮеҝөпјҢеҢәеҲ«дәҺеҫ®жһ¶жһ„зҡ„еҶ…еӯҳжЁЎеһӢпјҢй«ҳзә§иҜӯиЁҖзҡ„еҶ…еӯҳжЁЎеһӢеҢ…жӢ¬дәҶзј–иҜ‘еҷЁе’Ңеҫ®жһ¶жһ„дёӨйғЁеҲҶгҖӮжҲ‘иҜ•еӣҫдәҶи§ЈдәҶJavaгҖҒC#е’ҢGoиҜӯиЁҖзҡ„еҶ…еӯҳжЁЎеһӢпјҢеҸ‘зҺ°еҶ…е®№еҹәжң¬еӨ§еҗҢе°ҸејӮпјҢеҸӘжҳҜиҝҷдәӣиҜӯиЁҖеңЁе…·дҪ“е®һзҺ°зҡ„ж—¶еҖҷз•ҘжңүдёҚеҗҢгҖӮ
жҲ‘们жқҘзңӢзңӢJavaеҶ…еӯҳжЁЎеһӢеҗ§пјҢжҸҗеҲ°JavaеҶ…еӯҳжЁЎеһӢеӨ§е®¶еҜ№иҝҷдёӘеӣҫдёҖе®ҡйқһеёёзҶҹжӮүпјҡ
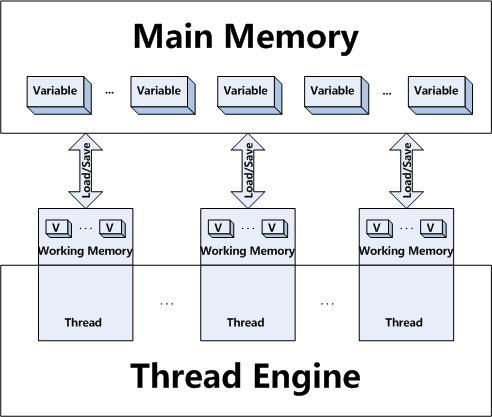
иҝҷеј еӣҫе‘ҠиҜүжҲ‘们еңЁзәҝзЁӢиҝҗиЎҢзҡ„ж—¶еҖҷжңүдёҖдёӘеҶ…еӯҳдё“з”Ёзҡ„дёҖе°Ҹеқ—еҶ…еӯҳпјҢеҪ“JavaзЁӢеәҸдјҡе°ҶеҸҳйҮҸеҗҢжӯҘеҲ°зәҝзЁӢжүҖеңЁзҡ„еҶ…еӯҳпјҢиҝҷж—¶еҖҷдјҡж“ҚдҪңе·ҘдҪңеҶ…еӯҳдёӯзҡ„еҸҳйҮҸпјҢиҖҢзәҝзЁӢ дёӯеҸҳйҮҸзҡ„еҖјдҪ•ж—¶еҗҢжӯҘеӣһдё»еҶ…еӯҳжҳҜдёҚеҸҜйў„жңҹзҡ„гҖӮдҪҶеҗҢж—¶JavaеҶ…еӯҳжЁЎеһӢеҸҲе‘ҠиҜүжҲ‘们йҖҡиҝҮдҪҝз”Ёе…ій”®иҜҚвҖңsynchronizedвҖқжҲ–вҖңvolatileвҖқеҸҜд»Ҙи®© JavaдҝқиҜҒжҹҗдәӣзәҰжқҹпјҡ
вҖңvolatileвҖқ — дҝқиҜҒиҜ»еҶҷзҡ„йғҪжҳҜдё»еҶ…еӯҳзҡ„еҸҳйҮҸ
вҖңsynchronizedвҖқ — дҝқиҜҒеңЁеқ—ејҖе§Ӣж—¶йғҪеҗҢжӯҘдё»еҶ…еӯҳзҡ„еҖјеҲ°е·ҘдҪңеҶ…еӯҳпјҢиҖҢеқ—з»“жқҹж—¶е°ҶеҸҳйҮҸеҗҢжӯҘеӣһдё»еҶ…еӯҳ
йҖҡиҝҮд»ҘдёҠжҸҸиҝ°жҲ‘们е°ұеҸҜд»ҘеҶҷеҮәзәҝзЁӢе®үе…Ёзҡ„JavaзЁӢеәҸпјҢJDKд№ҹеҗҢж—¶её®жҲ‘们еұҸи”ҪдәҶеҫҲеӨҡеә•еұӮзҡ„дёңиҘҝгҖӮ
дҪҶеҪ“дҪ ж·ұе…ҘдәҶи§ЈJVMзҡ„ж—¶еҖҷдҪ дјҡеҸ‘зҺ°ж №жң¬е°ұжІЎжңүе·ҘдҪңеҶ…еӯҳиҝҷдёӘдёңиҘҝпјҢеҚіеҶ…еӯҳдёӯж №жң¬дёҚдјҡеҲҶй…Қиҝҷд№ҲдёҖеқ—з©әй—ҙжқҘиҝҗиЎҢдҪ зҡ„JavaзЁӢеәҸпјҢйӮЈд№Ҳе·ҘдҪңеҶ…еӯҳеҲ°еә•жҳҜд»Җд№ҲдёңиҘҝе‘ўпјҹ
иҝҷдёӘй—®йўҳд№ҹжӣҫз»Ҹеӣ°жү°дәҶжҲ‘еҫҲй•ҝж—¶й—ҙпјҢеӣ дёәжҲ‘д»ҺжқҘжІЎжңүд»ҺJVMзҡ„е®һзҺ°дёӯжүҫеҲ°иҝҮе’Ңдё»еҶ…еӯҳеҗҢжӯҘзҡ„д»Јз ҒпјҢеӣ дёәеҪ“дҪҝз”ЁвҖңvolatileвҖқж—¶жҲ‘д»…д»…иғҪд»Һжәҗд»Јз Ғдёӯи°ғз”ЁдәҶиҝҷиЎҢиҜӯеҸҘпјҡ
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");иҖҢиҝҷдёӘжҢҮд»ӨеңЁйғЁеҲҶеҫ®жһ¶жһ„дёҠзҡ„дё»иҰҒеҠҹиғҪе°ұжҳҜйҳІжӯўжҢҮд»ӨйҮҚжҺ’пјҢеҚіиҝҷжқЎжҢҮд»ӨеүҚеҗҺзҡ„е…¶е®ғжҢҮд»ӨдёҚдјҡи¶ҠиҝҮиҝҷдёӘз•Ңйҷҗжү§иЎҢ[жіЁ1]гҖӮ
еңЁзҺ°еңЁзҡ„x86/x64еҫ®жһ¶жһ„дёӯиҜ»еҶҷеҶ…еӯҳзҡ„дёҖиҮҙжҖ§йғҪжҳҜйҖҡиҝҮMESIпјҲIntelдҪҝз”ЁMESI-FпјҢAMDдҪҝз”ЁMOESIпјүеҚҸи®®дҝқиҜҒ[жіЁ2]пјҢMESIзҡ„зҠ¶жҖҒиҪ¬жҚўеӣҫеҰӮдёӢпјҡ
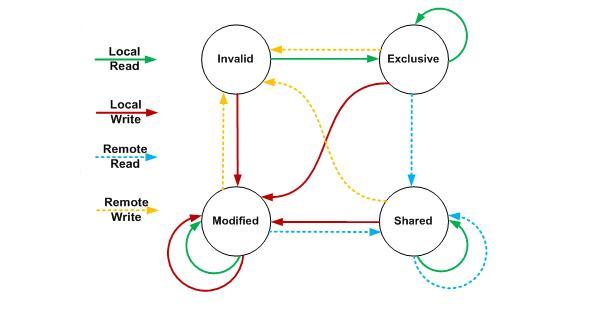
жӣҙиҜҰз»Ҷзҡ„дёӯж–Үж–ҮжЎЈжҸҸиҝ°еҸҜд»ҘжҹҘзңӢиҝҷдёӘж–ҮжЎЈпјҡhttp://blog.csdn.net/zhuliting/article/details/6210921
йӮЈJavaеҶ…еӯҳжЁЎеһӢдёӯжүҖиҜҙзҡ„е·ҘдҪңеҶ…еӯҳжҳҜд»Җд№Ҳе‘ўпјҹ
жҲ‘зҡ„зҗҶи§ЈжҳҜпјҢйҰ–е…ҲвҖңе·ҘдҪңеҶ…еӯҳвҖқжҳҜдёҖдёӘиҷҡжӢҹзҡ„жҰӮеҝөпјҢиҖҢжүҝиҪҪиҝҷдёӘжҰӮеҝөдё»иҰҒжҳҜдёӨйғЁеҲҶпјҡ
1. зј–иҜ‘еҷЁ
2. еҫ®жһ¶жһ„
дҪңдёәзј–иҜ‘еҷЁиӮҜе®ҡжҳҜжү§иЎҢйҖҹеәҰи¶Ҡеҝ«и¶ҠеҘҪпјҢжүҖд»ҘдҪңдёәзј–иҜ‘еҷЁеә”еҪ“е°ҪйҮҸеҮҸе°‘д»ҺеҶ…еӯҳиҜ»ж•°жҚ®пјҢеҰӮжһңдёҖдёӘж•°жҚ®еңЁеҜ„еӯҳеҷЁдёӯпјҢйӮЈд№ҲзӣҙжҺҘдҪҝз”ЁеҜ„еӯҳеҷЁдёӯзҡ„еҖјж— з–‘жҖ§иғҪжҳҜ*** зҡ„пјҢдҪҶеҗҢж—¶иҝҷд№ҹдјҡеҜјиҮҙеҸҜиғҪиҜ»дёҚеҲ°***зҡ„еҖјпјҢиҝҷйҮҢжҲ‘们йҖҡиҝҮеңЁJavaиҜӯиЁҖдёӯдёәеҸҳйҮҸеҠ дёҠвҖңvolatileвҖқејәеҲ¶е‘ҠиҜүзј–иҜ‘еҷЁиҝҷдёӘеҸҳйҮҸдёҖе®ҡиҰҒд»ҺеҶ…еӯҳиҺ·еҫ—пјҢиҝҷж—¶зј– иҜ‘еҷЁеҚідёҚдјҡеҒҡжӯӨзұ»дјҳеҢ–гҖҗжЎҲдҫӢи§ҒеҸӮиҖғиө„ж–ҷ5пјҲжҳҜдёҖдёӘ.Netзҡ„дҫӢеӯҗпјүгҖ‘гҖӮ
еҜ№дәҺеҫ®жһ¶жһ„жқҘиҜҙпјҢеңЁx86/x64дёӢпјҢCPUдјҡеңЁжү§иЎҢжҢҮд»Өж—¶еҒҡжҢҮд»ӨйҮҚжҺ’пјҢеҚізј–иҜ‘еҷЁз”ҹжҲҗзҡ„жҢҮд»ӨйЎәеәҸе’ҢзңҹжӯЈеңЁCPUжү§иЎҢзҡ„йЎәеәҸеҸҜиғҪжҳҜдёҚдёҖиҮҙзҡ„гҖӮеҪ“жҲ‘们用дёҖдёӘеҸҳйҮҸеҒҡдҝЎеҸ·зҡ„ж—¶еҖҷиҝҷз§ҚжҢҮд»ӨйҮҚжҺ’дјҡеёҰжқҘжӮІеү§пјҢеҚіеҰӮжһңжңүеҰӮдёӢд»Јз Ғпјҡ
x = 0; y = 0; i = 0; j = 0; // thread A y = 1; x = 1; // thread B i = x; j = y;
дёҠйқўзҡ„д»Јз Ғiе’Ңjзҡ„еҖјдјҡжҳҜеӨҡе°‘е‘ўпјҹзӯ”жЎҲжҳҜпјҡвҖң00пјҢ 01пјҢ 10пјҢ 11вҖқйғҪжҳҜжңүеҸҜиғҪзҡ„гҖӮ
еҜ№дәҺиҝҷз§Қжғ…еҶөпјҢеҰӮжһңжҲ‘们жғіеҫ—еҲ°зЎ®е®ҡзҡ„з»“жһңеҲҷйңҖиҰҒйҖҡиҝҮвҖңsynchronizedвҖқпјҲжҲ–иҖ…j.c.u.locksпјүжқҘеҒҡзәҝзЁӢй—ҙеҗҢжӯҘгҖӮ
жүҖд»ҘпјҢжҲ‘дёӘдәәеҜ№JavaеҶ…еӯҳжЁЎеһӢзҡ„зҗҶи§ЈжҳҜпјҡеңЁзј–иҜ‘еҷЁеҗ„з§ҚдјҳеҢ–еҸҠеӨҡз§Қзұ»еһӢзҡ„еҫ®жһ¶жһ„е№іеҸ°дёҠпјҢJavaиҜӯиЁҖ规иҢғеҲ¶е®ҡиҖ…иҜ•еӣҫеҲӣе»әдёҖдёӘиҷҡжӢҹзҡ„жҰӮеҝөе№¶дј йҖ’еҲ° JavaзЁӢеәҸе‘ҳпјҢ让他们иғҪеӨҹеңЁиҝҷдёӘиҷҡжӢҹзҡ„жҰӮеҝөдёҠеҶҷеҮәзәҝзЁӢе®үе…Ёзҡ„зЁӢеәҸжқҘпјҢиҖҢзј–иҜ‘еҷЁе®һзҺ°иҖ…дјҡж №жҚ®JavaиҜӯиЁҖ规иҢғдёӯзҡ„еҗ„з§ҚзәҰжқҹеңЁдёҚеҗҢзҡ„е№іеҸ°дёҠиҫҫеҲ°JavaзЁӢеәҸ е‘ҳжүҖйңҖиҰҒзҡ„зәҝзЁӢе®үе…ЁиҝҷдёӘзӣ®зҡ„гҖӮ
е…ідәҺJavaеҶ…еӯҳжЁЎеһӢзҡ„еҺҹзҗҶжҳҜд»Җд№Ҳе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





