本篇内容介绍了“VS项目整体重命名工具是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
VS项目整体重命名工具
不再为项目重命名和修改命名空间而烦恼,简单几个字,但是开发加上测试大量项目,前前后后竟然跨越了1个月,汗。。。不过真正的开发时间可能2-3天的样子。
一.介绍
1.虽然说我们平常不会经常出现项目重命名的情况,但是一旦出现,修改起来还是一项比较大的工程,并且还不一定修改完整。
2.当团队发展到一定程度的时候,基本上都有了自己固定的一些WEB/Winform开发框架和通用项目模版,这样就会出现修改项目名称,命名空间等结构的情况。
3.哒哒哒哒哒哒,不说第三了。亲,没了。@_@
二.功能
1.自动重命名关联的各种文件,并且支持自定义扩展。
2.自动检测文件编码格式,处理读取不同编码格式时出现的乱码问题。(当项目内包含中文的时候)
3.自动修改sln和csproj文件中的引用关系,并且根据文件名称修改文件夹名称。
4.清理BIN目录和OBJ目录,已经项目产生的不必要的垃圾文件,可单独使用。
5.每个csproj都是执行单独修改,然后更新关联引用,并记住修改过的引用。
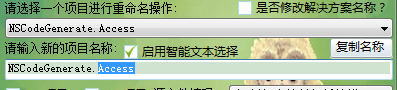
6.输入项目新名词的文本框加入了选词功能(文本框本身双击内容是全选的效果)。
7.自己试一下把。+_+
三.演示与截图
1.VS的观察
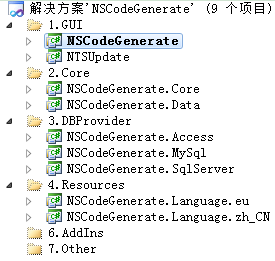
更新前的VS项目解决方案
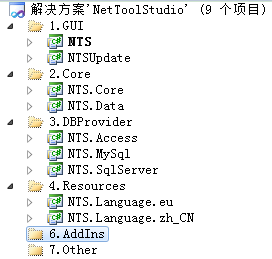
更新后的VS项目解决方案
2.系统资源管理器的观察

更新前的文件夹结构
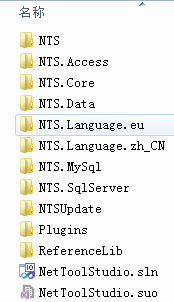
更新后的文件夹结构
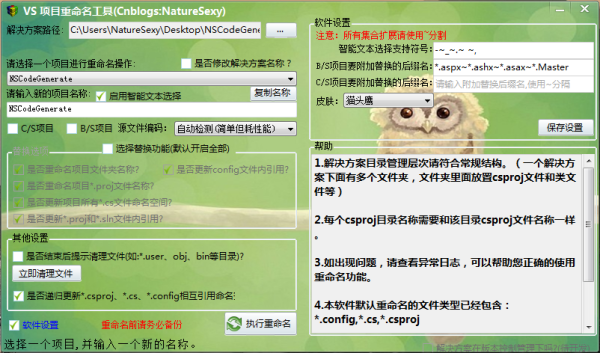
3.软件使用截图
1.打开软件显示很简单的打开解决方案的视图。

2.选择解决方案打开后,会自动加载该目下所有的csproj文件。
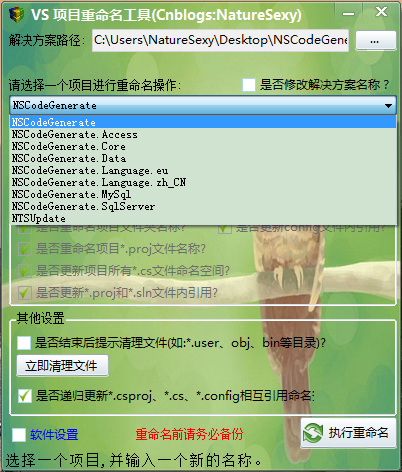
3.点击【软件设置】会出现其他需要修改关联的文件后缀名,你也可以直接写文件全名。
你也可以给输入新名称的文本框添加选词分隔符,以达到你所需要的自动选词效果。
四.代码和思路
1.文本框智能选词功能的实现。
public delegate void AutoSelectTextBoxDoubleclick(object sender, MouseEventArgs e); /// <summary> /// 智能选择文本控件,亲,这个类copy走就可以使用哟 /// </summary> public class AutoSelectTextBox : TextBox { const int WM_LBUTTONDBLCLK = 0x0203; MouseEventArgs e; /// <summary> /// 是否启用智能选择 /// </summary> [System.ComponentModel.Description("是否启用智能选择")] public bool EnableAutoSelect { get; set; } private List<char> splitChar; /// <summary> /// 选择判断分隔符,默认 . 号 /// </summary> [System.ComponentModel.Description("判断选择分隔符,默认 . 号")] [System.ComponentModel.Browsable(false)] public List<char> SplitChar { get { return splitChar; } set { splitChar = value; } } /// <summary> /// 智能选择文本框双击事件 /// </summary> public event AutoSelectTextBoxDoubleclick AutoSelectTextMouseDoubleclick; protected override void WndProc(ref Message m) { if (EnableAutoSelect && m.Msg == WM_LBUTTONDBLCLK) { Point p = this.PointToClient(MousePosition); e = new MouseEventArgs(MouseButtons.Left, 2, p.X, p.Y, 0); if (AutoSelectTextMouseDoubleclick != null) { AutoSelectTextMouseDoubleclick(this, e); } else { MouseDoubleClickAutoSelect(e); } return; } else { base.WndProc(ref m); } } /// <summary> /// 智能选择实现 /// </summary> private void MouseDoubleClickAutoSelect(MouseEventArgs e) { if (this.Text != "") { int pint = this.GetCharIndexFromPosition(e.Location); int len = this.Text.Length; int left = pint, right = pint; while (left >= 0) { char lchar = this.Text[left]; if (CheckSpiltChar(lchar)) { break; } left--; } while (right <= len - 1) { char rchar = this.Text[right]; if (CheckSpiltChar(rchar)) { break; } right++; } //必须有字符可选 if (right - (left + 1) > 0) { this.Select(left + 1, right - (left + 1)); } } } /// <summary> /// 检查 /// </summary> /// <param name="source"></param> /// <returns></returns> private bool CheckSpiltChar(char source) { if (SplitChar != null) { foreach (char c in SplitChar) { if (char.Equals(source, c)) { return true; } } return false; } else { return char.Equals(source, '.'); } } }解释:该自动完成选词功能需要重写文本框的消息机制,其中 WM_LBUTTONDBLCLK = 0x0203 为鼠标双击消息,然后重写WndProc该事件。
为什么我重新写双击消息,而不是用文本框本身的双击事件,是因为本身的双击事件会处理一些其他内容,并且会出现先选中全部内容然后再自动选词的闪烁问题,
有兴趣的同学可以试一下就知道了。
2.老调重弹自动识别文件编码问题,大部分的解决方案都不太理想,基本都是读取文件2-4位,判断字节大小,来决定文件编码类型。
这样的思路只是其中之一,当我郁闷至极的时候突然想到ITextSharp控件(重量级语言高亮编辑器),找到源码,发现了一块编码自动识别的功能。
下面代码是ITextSharp控件中文件编码识别的源码,这个我发现比百度和google出来的效果好很多,基本上无识别错误情况,基本100%识别正确。
但是带来的后果是要检查一段内容前面很大一段内容,用性能换编码识别精度。
public static StreamReader OpenStream(Stream fs, Encoding defaultEncoding) { if (fs == null) throw new ArgumentNullException("fs"); if (fs.Length >= 2) { // the autodetection of StreamReader is not capable of detecting the difference // between ISO-8859-1 and UTF-8 without BOM. int firstByte = fs.ReadByte(); int secondByte = fs.ReadByte(); switch ((firstByte << 8) | secondByte) { case 0x0000: // either UTF-32 Big Endian or a binary file; use StreamReader case 0xfffe: // Unicode BOM (UTF-16 LE or UTF-32 LE) case 0xfeff: // UTF-16 BE BOM case 0xefbb: // start of UTF-8 BOM // StreamReader autodetection works fs.Position = 0; return new StreamReader(fs); default: return AutoDetect(fs, (byte)firstByte, (byte)secondByte, defaultEncoding); } } else { if (defaultEncoding != null) { return new StreamReader(fs, defaultEncoding); } else { return new StreamReader(fs); } } } static StreamReader AutoDetect(Stream fs, byte firstByte, byte secondByte, Encoding defaultEncoding) { int max = (int)Math.Min(fs.Length, 500000); // look at max. 500 KB const int ASCII = 0; const int Error = 1; const int UTF8 = 2; const int UTF8Sequence = 3; int state = ASCII; int sequenceLength = 0; byte b; for (int i = 0; i < max; i++) { if (i == 0) { b = firstByte; } else if (i == 1) { b = secondByte; } else { b = (byte)fs.ReadByte(); } if (b < 0x80) { // normal ASCII character if (state == UTF8Sequence) { state = Error; break; } } else if (b < 0xc0) { // 10xxxxxx : continues UTF8 byte sequence if (state == UTF8Sequence) { --sequenceLength; if (sequenceLength < 0) { state = Error; break; } else if (sequenceLength == 0) { state = UTF8; } } else { state = Error; break; } } else if (b >= 0xc2 && b < 0xf5) { // beginning of byte sequence if (state == UTF8 || state == ASCII) { state = UTF8Sequence; if (b < 0xe0) { sequenceLength = 1; // one more byte following } else if (b < 0xf0) { sequenceLength = 2; // two more bytes following } else { sequenceLength = 3; // three more bytes following } } else { state = Error; break; } } else { // 0xc0, 0xc1, 0xf5 to 0xff are invalid in UTF-8 (see RFC 3629) state = Error; break; } } fs.Position = 0; switch (state) { case ASCII: case Error: // when the file seems to be ASCII or non-UTF8, // we read it using the user-specified encoding so it is saved again // using that encoding. if (IsUnicode(defaultEncoding)) { // the file is not Unicode, so don't read it using Unicode even if the // user has choosen Unicode as the default encoding. // If we don't do this, SD will end up always adding a Byte Order Mark // to ASCII files. defaultEncoding = Encoding.Default; // use system encoding instead } return new StreamReader(fs, defaultEncoding); default: return new StreamReader(fs); } }ITextSharp文件识别基本思路:
1.传入需要读取文件流,并且传入一个你认为合适的编码方式,当然你可以传入NULL。
2.读取文件前面2个字节(这个是大部分解析编码需要做的事情),读取进来的字节向左移8位,然后与第二个字节进行 | 运算,主要用途是检测StreamReader是否在iso - 8859 - 1和utf - 8之间的编码范围,并且不包含BOM。
忘记了C#这些运算的可以看看,http://www.cnblogs.com/NatureSex/archive/2011/04/21/2023768.html
3.当位移出来的结果等于0x0000,0xfffe,0xfeff,0xefbb时,是StreamReader可以进行自动读取范围内的。如果不在范围内时再进行读取偏移检测,具体怎么检测的,这个有点难度,本人也只是看懂了一点点,主要是系统编码知识欠缺。
五.下载
下载地址:VS重命名工具 喜欢的朋友记得推荐一下哟
源码就不放了,文件没有混淆也没有加密,自己反编译统统都有。
“VS项目整体重命名工具是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



