今天就跟大家聊聊有关如何理解Java虚拟机及JVM体系结构是什么,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
JVM(Java 虚拟机)
Java虚拟机,java源文件(.java)通过编译器生成字节码文件(.class),字节码文件(.class)通过JVM(Java虚拟机)中的解释器再翻译成特定机器上的机器码。
编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。
每一种平台的解释器是不同的,但是实现的虚拟机是相同的。
Java源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。
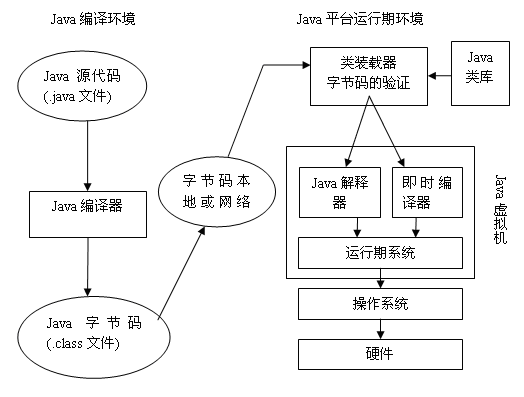

JVM体系结构
JVM都有两种机制,一个是装载具有合适名称的类(类或是接口),叫做类装载子系统;另外的一个负责执行包含在已装载的类或接口中的指令,叫做运行引擎。每个JVM又包括方法区、堆、Java栈、程序计数器和本地方法栈这五个部分,这几个部分和类装载机制与运行引擎机制一起组成的体系结构图为:
JVM的每个实例都有一个它自己的方法域和一个堆,运行于JVM内的所有的线程都共享这些区域;当虚拟机装载类文件的时候,它解析其中的二进制数据所包含的类信息,并把它们放到方法域中;当程序运行的时候,JVM把程序初始化的所有对象置于堆上;而每个线程创建的时候,都会拥有自己的程序计数器和Java栈,其中程序计数器中的值指向下一条即将被执行的指令,线程的Java栈则存储为该线程调用Java方法的状态;本地方法调用的状态被存储在本地方法栈,该方法栈依赖于具体的实现。
(1)类装载子系统
装载 连接 初始化
(2)方法区。被所有线程共享。垃圾收集也会清理方法区中的无用类型对象。
a. 类型信息。类加载器加载类时,从类文件中提取出来。
类的完整有效名
父类的完整有效名(interface and java.lang.Object 除外,因为无父类)
类型的修饰符
类型直接接口列表
b. 常量池。存储了一个类型所使用的常量所有类型、域和方法的符号引用。
c. 域信息。jvm必须在方法区中保存类型的所有域的相关信息以及域的声明顺序, 域的相关信息包括: 域名 域类型 域修饰符(public private protected static final volatile transient…)
d.方法信息。
方法名
方法返回类型
方法参数
方法的修饰符
方法的字节码(abstract and native 除外)(被PC寄存器指向)
操作数栈和方法栈帧的局部变量区的大小
异常表
e. 类的静态变量(所有对象共享一分拷贝)
f. 类的被声明为final的类变量(所有对象共享一分拷贝)
g. 加载一个类的类加载器的引用
h. Class类的引用
i. 方法表。
j. 一个例子:
Class Lava { private int speed = 5; void flow(); } Class Volcano { public static void main(String[] args) { Lava lava = new Lava(); lava.flow(); } }下面我们描述一下main()方法的***条指令的字节码是如何被执行 的。不同的jvm实现的差别很大,这里只是其中之一。
为了运行这个程序,你以某种方式把“Volcano"传给了jvm。有了 这个名字,jvm找到了这个类文件(Volcano.class)并读入,它从 类文件提取了类型信息并放在了方法区中,通过解析存在方法区中的 字节码,jvm激活了main()方法,在执行时,jvm保持了一个指向当前 类(Volcano)常量池的指针。
注意jvm在还没有加载Lava类的时候就已经开始执行了。正像大多数的 jvm一样,不会等所有类都加载了以后才开始执行,它只会在需要的时候 才加载。
main()的***条指令告知jvm为列在常量池***项的类分配足够的内存。 jvm使用指向Volcano常量池的指针找到***项,发现是一个对Lava类 的符号引用,然后它就检查方法区看lava是否已经被加载了。
这个符号引用仅仅是类lava的完整有效名”lava“。这里我们看到为了jvm 能尽快从一个名称找到一个类,一个良好的数据结构是多么重要。这里jvm 的实现者可以采用各种方法,如hash表,查找树等等。同样的算法可以用于 Class类的forName()的实现。
当jvm发现还没有加载过一个称为"Lava"的类,它就开始查找并加载类 文件"Lava.class"。它从类文件中抽取类型信息并放在了方法区中。
jvm于是以一个直接指向方法区lava类的指针替换了常量池***项的符号 引用。以后就可以用这个指针快速的找到lava类了。而这个替换过程称为 常量池解析(constant pool resolution)。在这里我们替换的是一个 native指针。
jvm终于开始为新的lava对象分配空间了。这次,jvm仍然需要方法区中 的信息。它使用指向lava数据的指针(刚才指向volcano常量池***项的指针) 找到一个lava对象究竟需要多少空间。
一旦jvm知道了一个Lava对象所要的空间,它就在堆上分配这个空间并把这个实例的变量speed初始化为缺省值0。假如lava的父对象也有实例变量,则也会初始化。
当把新生成的lava对象的引用压到栈中,***条指令也结束了。下面的指令利用这个引用激活java代码把speed变量设为初始值,5。另外一条指令会用这个引用激活 Lava对象的flow()方法。
(3)堆。存放运行时所有 对象 和 数组。
(4)栈。每次启动一个新的线程,就会被分配一个栈。
(5)PC 寄存器(程序计数器)总是指向该线程下一步要执行的指令。指令的位置放在方法区的方法字节码中。内容是相 对于***个指令的偏移量。
看完上述内容,你们对如何理解Java虚拟机及JVM体系结构是什么有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





