GoиҜӯиЁҖзҡ„GCжөҒзЁӢи§Јжһҗ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңGoиҜӯиЁҖзҡ„GCжөҒзЁӢи§ЈжһҗвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁGoиҜӯиЁҖзҡ„GCжөҒзЁӢи§Јжһҗй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқGoиҜӯиЁҖзҡ„GCжөҒзЁӢи§ЈжһҗвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
дёүиүІж Үи®°еҺҹзҗҶ
жҲ‘们йҰ–е…ҲзңӢдёҖеј еӣҫпјҢеӨ§жҰӮе°ұдјҡеҜ№ дёүиүІж Үи®°жі• жңүдёҖдёӘеӨ§иҮҙзҡ„дәҶи§Јпјҡ
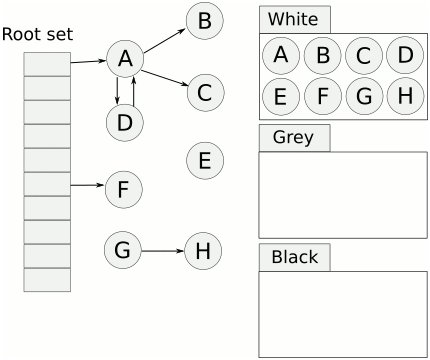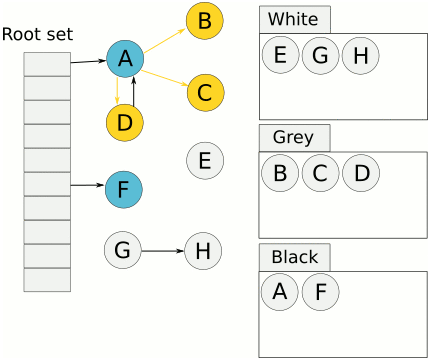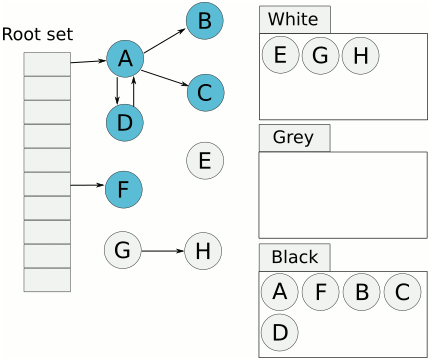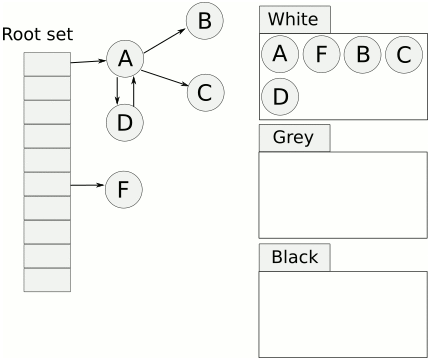
еҺҹзҗҶпјҡ
йёҝи’ҷе®ҳж–№жҲҳз•ҘеҗҲдҪңе…ұе»әвҖ”вҖ”HarmonyOSжҠҖжңҜзӨҫеҢә
йҰ–е…ҲжҠҠжүҖжңүзҡ„еҜ№иұЎйғҪж”ҫеҲ°зҷҪиүІзҡ„йӣҶеҗҲдёӯ
д»Һж №иҠӮзӮ№ејҖе§ӢйҒҚеҺҶеҜ№иұЎпјҢйҒҚеҺҶеҲ°зҡ„зҷҪиүІеҜ№иұЎд»ҺзҷҪиүІйӣҶеҗҲдёӯж”ҫеҲ°зҒ°иүІйӣҶеҗҲдёӯ
йҒҚеҺҶзҒ°иүІйӣҶеҗҲдёӯзҡ„еҜ№иұЎпјҢжҠҠзҒ°иүІеҜ№иұЎеј•з”Ёзҡ„зҷҪиүІйӣҶеҗҲзҡ„еҜ№иұЎж”ҫе…ҘеҲ°зҒ°иүІйӣҶеҗҲдёӯпјҢеҗҢж—¶жҠҠйҒҚеҺҶиҝҮзҡ„зҒ°иүІйӣҶеҗҲдёӯзҡ„еҜ№иұЎж”ҫеҲ°й»‘иүІзҡ„йӣҶеҗҲдёӯ
еҫӘзҺҜжӯҘйӘӨ3пјҢзҹҘйҒ“зҒ°иүІйӣҶеҗҲдёӯжІЎжңүеҜ№иұЎ
жӯҘйӘӨ4з»“жқҹеҗҺпјҢзҷҪиүІйӣҶеҗҲдёӯзҡ„еҜ№иұЎе°ұжҳҜдёҚеҸҜиҫҫеҜ№иұЎпјҢд№ҹе°ұжҳҜеһғеңҫпјҢиҝӣиЎҢеӣһ收
еҶҷеұҸйҡң
GoеңЁиҝӣиЎҢдёүиүІж Үи®°зҡ„ж—¶еҖҷ并没жңүSTWпјҢд№ҹе°ұжҳҜиҜҙпјҢжӯӨж—¶зҡ„еҜ№иұЎиҝҳжҳҜеҸҜд»ҘиҝӣиЎҢдҝ®ж”№
йӮЈд№ҲжҲ‘们иҖғиҷ‘дёҖдёӢпјҢдёӢйқўзҡ„жғ…еҶө
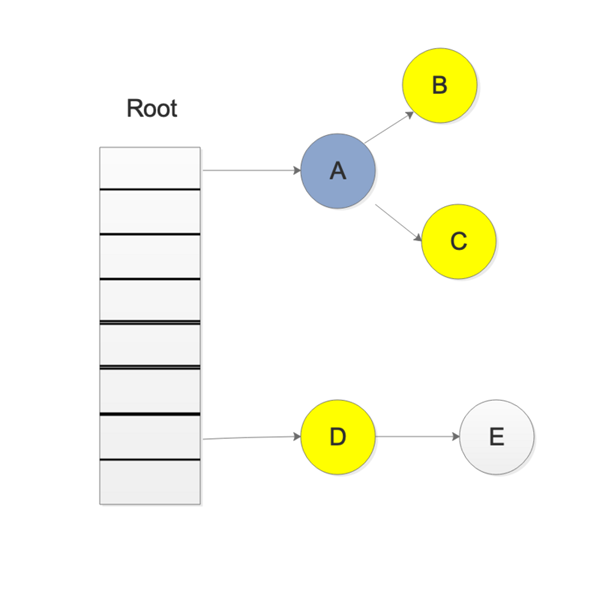
жҲ‘们еңЁиҝӣиЎҢдёүиүІж Үи®°дёӯжү«жҸҸзҒ°иүІйӣҶеҗҲдёӯпјҢжү«жҸҸеҲ°дәҶеҜ№иұЎAпјҢ并ж Үи®°дәҶеҜ№иұЎAзҡ„жүҖжңүеј•з”ЁпјҢиҝҷж—¶еҖҷпјҢејҖе§Ӣжү«жҸҸеҜ№иұЎDзҡ„еј•з”ЁпјҢиҖҢжӯӨж—¶пјҢеҸҰдёҖдёӘgoroutineдҝ®ж”№дәҶD->Eзҡ„еј•з”ЁпјҢеҸҳжҲҗдәҶеҰӮдёӢеӣҫжүҖзӨә
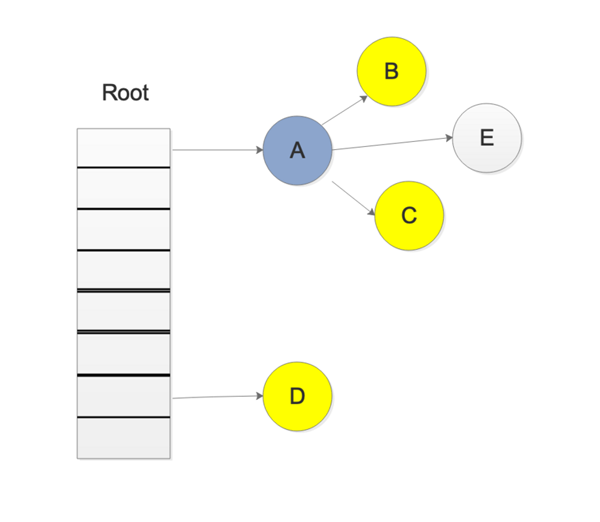
иҝҷж ·дјҡдёҚдјҡеҜјиҮҙEеҜ№иұЎе°ұжү«жҸҸдёҚеҲ°дәҶпјҢиҖҢиў«иҜҜи®Өдёә дёәзҷҪиүІеҜ№иұЎпјҢд№ҹе°ұжҳҜеһғеңҫ
еҶҷеұҸйҡңе°ұжҳҜдёәдәҶи§ЈеҶіиҝҷж ·зҡ„й—®йўҳпјҢеј•е…ҘеҶҷеұҸйҡңеҗҺпјҢеңЁдёҠиҝ°жӯҘйӘӨеҗҺпјҢEдјҡиў«и®ӨдёәжҳҜеӯҳжҙ»зҡ„пјҢеҚідҪҝеҗҺйқўEиў«AеҜ№иұЎжҠӣејғпјҢEдјҡиў«еңЁдёӢдёҖиҪ®зҡ„GCдёӯиҝӣиЎҢеӣһ收пјҢиҝҷдёҖиҪ®GCдёӯжҳҜдёҚдјҡеҜ№еҜ№иұЎEиҝӣиЎҢеӣһ收зҡ„
Go1.9дёӯејҖе§ӢеҗҜз”ЁдәҶж··еҗҲеҶҷеұҸйҡңпјҢдјӘд»Јз ҒеҰӮдёӢ
writePointer(slot, ptr): shade(*slot) if any stack is grey: shade(ptr) *slot = ptr
ж··еҗҲеҶҷеұҸйҡңдјҡеҗҢж—¶ж Үи®°жҢҮй’ҲеҶҷе…Ҙзӣ®ж Үзҡ„"еҺҹжҢҮй’Ҳ"е’ҢвҖңж–°жҢҮй’Ҳ".
ж Үи®°еҺҹжҢҮй’Ҳзҡ„еҺҹеӣ жҳҜ, е…¶д»–иҝҗиЎҢдёӯзҡ„зәҝзЁӢжңүеҸҜиғҪдјҡеҗҢж—¶жҠҠиҝҷдёӘжҢҮй’Ҳзҡ„еҖјеӨҚеҲ¶еҲ°еҜ„еӯҳеҷЁжҲ–иҖ…ж ҲдёҠзҡ„жң¬ең°еҸҳйҮҸ
еӣ дёәеӨҚеҲ¶жҢҮй’ҲеҲ°еҜ„еӯҳеҷЁжҲ–иҖ…ж ҲдёҠзҡ„жң¬ең°еҸҳйҮҸдёҚдјҡз»ҸиҝҮеҶҷеұҸйҡң, жүҖд»ҘжңүеҸҜиғҪдјҡеҜјиҮҙжҢҮй’ҲдёҚиў«ж Үи®°, иҜ•жғідёӢйқўзҡ„жғ…еҶөпјҡ
[go] b = obj [go] oldx = nil [gc] scan oldx... [go] oldx = b.x // еӨҚеҲ¶b.xеҲ°жң¬ең°еҸҳйҮҸ, дёҚиҝӣиҝҮеҶҷеұҸйҡң [go] b.x = ptr // еҶҷеұҸйҡңеә”иҜҘж Үи®°b.xзҡ„еҺҹеҖј [gc] scan b... еҰӮжһңеҶҷеұҸйҡңдёҚж Үи®°еҺҹеҖј, йӮЈд№Ҳoldxе°ұдёҚдјҡиў«жү«жҸҸеҲ°.
ж Үи®°ж–°жҢҮй’Ҳзҡ„еҺҹеӣ жҳҜ, е…¶д»–иҝҗиЎҢдёӯзҡ„зәҝзЁӢжңүеҸҜиғҪдјҡиҪ¬з§»жҢҮй’Ҳзҡ„дҪҚзҪ®, иҜ•жғідёӢйқўзҡ„жғ…еҶө:
[go] a = ptr [go] b = obj [gc] scan b... [go] b.x = a // еҶҷеұҸйҡңеә”иҜҘж Үи®°b.xзҡ„ж–°еҖј [go] a = nil [gc] scan a... еҰӮжһңеҶҷеұҸйҡңдёҚж Үи®°ж–°еҖј, йӮЈд№Ҳptrе°ұдёҚдјҡиў«жү«жҸҸеҲ°.
ж··еҗҲеҶҷеұҸйҡңеҸҜд»Ҙи®©GCеңЁе№¶иЎҢж Үи®°з»“жқҹеҗҺдёҚйңҖиҰҒйҮҚж–°жү«жҸҸеҗ„дёӘGзҡ„е Ҷж Ҳ, еҸҜд»ҘеҮҸе°‘Mark Terminationдёӯзҡ„STWж—¶й—ҙ
йҷӨдәҶеҶҷеұҸйҡңеӨ–, еңЁGCзҡ„иҝҮзЁӢдёӯжүҖжңүж–°еҲҶй…Қзҡ„еҜ№иұЎйғҪдјҡз«ӢеҲ»еҸҳдёәй»‘иүІ, еңЁдёҠйқўзҡ„mallocgcеҮҪж•°дёӯеҸҜд»ҘзңӢеҲ°
еӣһ收жөҒзЁӢ
GOзҡ„GCжҳҜ并иЎҢGC, д№ҹе°ұжҳҜGCзҡ„еӨ§йғЁеҲҶеӨ„зҗҶе’Ңжҷ®йҖҡзҡ„goд»Јз ҒжҳҜеҗҢж—¶иҝҗиЎҢзҡ„, иҝҷи®©GOзҡ„GCжөҒзЁӢжҜ”иҫғеӨҚжқӮ.
йҰ–е…ҲGCжңүеӣӣдёӘйҳ¶ж®ө, е®ғ们еҲҶеҲ«жҳҜ:
Sweep Termination: еҜ№жңӘжё…жү«зҡ„spanиҝӣиЎҢжё…жү«, еҸӘжңүдёҠдёҖиҪ®зҡ„GCзҡ„жё…жү«е·ҘдҪңе®ҢжҲҗжүҚеҸҜд»ҘејҖе§Ӣж–°дёҖиҪ®зҡ„GC
Mark: жү«жҸҸжүҖжңүж №еҜ№иұЎ, е’Ңж №еҜ№иұЎеҸҜд»ҘеҲ°иҫҫзҡ„жүҖжңүеҜ№иұЎ, ж Үи®°е®ғ们дёҚиў«еӣһ收
Mark Termination: е®ҢжҲҗж Үи®°е·ҘдҪң, йҮҚж–°жү«жҸҸйғЁеҲҶж №еҜ№иұЎ(иҰҒжұӮSTW)
Sweep: жҢүж Үи®°з»“жһңжё…жү«span
дёӢеӣҫжҳҜжҜ”иҫғе®Ңж•ҙзҡ„GCжөҒзЁӢ, 并жҢүйўңиүІеҜ№иҝҷеӣӣдёӘйҳ¶ж®өиҝӣиЎҢдәҶеҲҶзұ»:
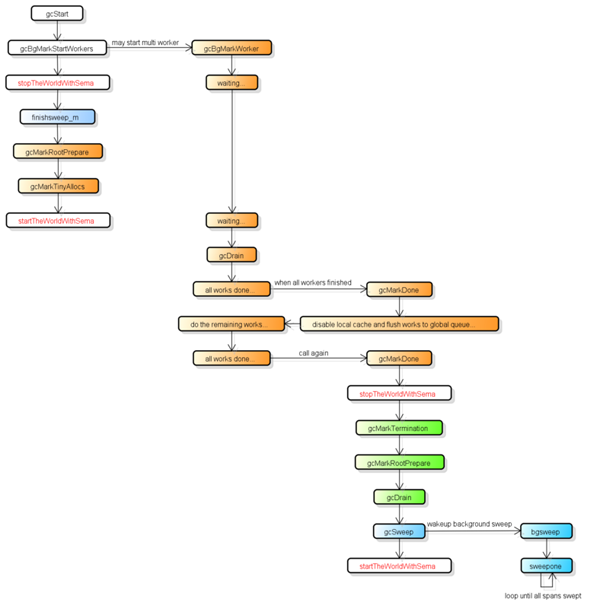
еңЁGCиҝҮзЁӢдёӯдјҡжңүдёӨз§ҚеҗҺеҸ°д»»еҠЎ(G), дёҖз§ҚжҳҜж Үи®°з”Ёзҡ„еҗҺеҸ°д»»еҠЎ, дёҖз§ҚжҳҜжё…жү«з”Ёзҡ„еҗҺеҸ°д»»еҠЎ.
ж Үи®°з”Ёзҡ„еҗҺеҸ°д»»еҠЎдјҡеңЁйңҖиҰҒж—¶еҗҜеҠЁ, еҸҜд»ҘеҗҢж—¶е·ҘдҪңзҡ„еҗҺеҸ°д»»еҠЎж•°йҮҸеӨ§зәҰжҳҜPзҡ„ж•°йҮҸзҡ„25%, д№ҹе°ұжҳҜgoжүҖи®Ізҡ„и®©25%зҡ„cpuз”ЁеңЁGCдёҠзҡ„ж №жҚ®.
жё…жү«з”Ёзҡ„еҗҺеҸ°д»»еҠЎеңЁзЁӢеәҸеҗҜеҠЁж—¶дјҡеҗҜеҠЁдёҖдёӘ, иҝӣе…Ҙжё…жү«йҳ¶ж®өж—¶е”ӨйҶ’.
зӣ®еүҚж•ҙдёӘGCжөҒзЁӢдјҡиҝӣиЎҢдёӨж¬ЎSTW(Stop The World), 第дёҖж¬ЎжҳҜMarkйҳ¶ж®өзҡ„ејҖе§Ӣ, 第дәҢж¬ЎжҳҜMark Terminationйҳ¶ж®ө.
第дёҖж¬ЎSTWдјҡеҮҶеӨҮж №еҜ№иұЎзҡ„жү«жҸҸ, еҗҜеҠЁеҶҷеұҸйҡң(Write Barrier)е’Ңиҫ…еҠ©GC(mutator assist).
第дәҢж¬ЎSTWдјҡйҮҚж–°жү«жҸҸйғЁеҲҶж №еҜ№иұЎ, зҰҒз”ЁеҶҷеұҸйҡң(Write Barrier)е’Ңиҫ…еҠ©GC(mutator assist).
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜ, дёҚжҳҜжүҖжңүж №еҜ№иұЎзҡ„жү«жҸҸйғҪйңҖиҰҒSTW, дҫӢеҰӮжү«жҸҸж ҲдёҠзҡ„еҜ№иұЎеҸӘйңҖиҰҒеҒңжӯўжӢҘжңүиҜҘж Ҳзҡ„G.
еҶҷеұҸйҡңзҡ„е®һзҺ°дҪҝз”ЁдәҶHybrid Write Barrier, еӨ§е№…еҮҸе°‘дәҶ第дәҢж¬ЎSTWзҡ„ж—¶й—ҙ.
жәҗз ҒеҲҶжһҗ
gcStart
func gcStart(mode gcMode, trigger gcTrigger) { // Since this is called from malloc and malloc is called in // the guts of a number of libraries that might be holding // locks, don't attempt to start GC in non-preemptible or // potentially unstable situations. // еҲӨж–ӯеҪ“еүҚgжҳҜеҗҰеҸҜд»ҘжҠўеҚ пјҢдёҚеҸҜжҠўеҚ ж—¶дёҚи§ҰеҸ‘GC mp := acquirem() if gp := getg(); gp == mp.g0 || mp.locks > 1 || mp.preemptoff != "" { releasem(mp) return } releasem(mp) mp = nil // Pick up the remaining unswept/not being swept spans concurrently // // This shouldn't happen if we're being invoked in background // mode since proportional sweep should have just finished // sweeping everything, but rounding errors, etc, may leave a // few spans unswept. In forced mode, this is necessary since // GC can be forced at any point in the sweeping cycle. // // We check the transition condition continuously here in case // this G gets delayed in to the next GC cycle. // жё…жү« ж®Ӣз•ҷзҡ„жңӘжё…жү«зҡ„еһғеңҫ for trigger.test() && gosweepone() != ^uintptr(0) { sweep.nbgsweep++ } // Perform GC initialization and the sweep termination // transition. semacquire(&work.startSema) // Re-check transition condition under transition lock. // еҲӨж–ӯgcTrrigerзҡ„жқЎд»¶жҳҜеҗҰжҲҗз«Ӣ if !trigger.test() { semrelease(&work.startSema) return } // For stats, check if this GC was forced by the user // еҲӨж–ӯ并记еҪ•GCжҳҜеҗҰиў«ејәеҲ¶жү§иЎҢзҡ„пјҢruntime.GC()еҸҜд»Ҙиў«з”ЁжҲ·и°ғ用并ејәеҲ¶жү§иЎҢ work.userForced = trigger.kind == gcTriggerAlways || trigger.kind == gcTriggerCycle // In gcstoptheworld debug mode, upgrade the mode accordingly. // We do this after re-checking the transition condition so // that multiple goroutines that detect the heap trigger don't // start multiple STW GCs. // и®ҫзҪ®gcзҡ„mode if mode == gcBackgroundMode { if debug.gcstoptheworld == 1 { mode = gcForceMode } else if debug.gcstoptheworld == 2 { mode = gcForceBlockMode } } // Ok, we're doing it! Stop everybody else semacquire(&worldsema) if trace.enabled { traceGCStart() } // еҗҜеҠЁеҗҺеҸ°ж Үи®°д»»еҠЎ if mode == gcBackgroundMode { gcBgMarkStartWorkers() } // йҮҚзҪ®gc ж Үи®°зӣёе…ізҡ„зҠ¶жҖҒ gcResetMarkState() work.stwprocs, work.maxprocs = gomaxprocs, gomaxprocs if work.stwprocs > ncpu { // This is used to compute CPU time of the STW phases, // so it can't be more than ncpu, even if GOMAXPROCS is. work.stwprocs = ncpu } work.heap0 = atomic.Load64(&memstats.heap_live) work.pauseNS = 0 work.mode = mode now := nanotime() work.tSweepTerm = now work.pauseStart = now if trace.enabled { traceGCSTWStart(1) } // STW,еҒңжӯўдё–з•Ң systemstack(stopTheWorldWithSema) // Finish sweep before we start concurrent scan. // е…Ҳжё…жү«дёҠдёҖиҪ®зҡ„еһғеңҫпјҢзЎ®дҝқдёҠиҪ®GCе®ҢжҲҗ systemstack(func() { finishsweep_m() }) // clearpools before we start the GC. If we wait they memory will not be // reclaimed until the next GC cycle. // жё…зҗҶ sync.pool sched.sudogcacheгҖҒsched.deferpoolпјҢиҝҷйҮҢдёҚеұ•ејҖпјҢsync.poolе·Із»ҸиҜҙдәҶпјҢеү©дҪҷзҡ„еҗҺйқўзҡ„ж–Үз« дјҡж¶үеҸҠ clearpools() // еўһеҠ GCжҠҖжңҜ work.cycles++ if mode == gcBackgroundMode { // Do as much work concurrently as possible gcController.startCycle() work.heapGoal = memstats.next_gc // Enter concurrent mark phase and enable // write barriers. // // Because the world is stopped, all Ps will // observe that write barriers are enabled by // the time we start the world and begin // scanning. // // Write barriers must be enabled before assists are // enabled because they must be enabled before // any non-leaf heap objects are marked. Since // allocations are blocked until assists can // happen, we want enable assists as early as // possible. // и®ҫзҪ®GCзҡ„зҠ¶жҖҒдёә gcMark setGCPhase(_GCmark) // жӣҙж–° bgmark зҡ„зҠ¶жҖҒ gcBgMarkPrepare() // Must happen before assist enable. // 计算并жҺ’йҳҹroot жү«жҸҸд»»еҠЎпјҢ并еҲқе§ӢеҢ–зӣёе…іжү«жҸҸд»»еҠЎзҠ¶жҖҒ gcMarkRootPrepare() // Mark all active tinyalloc blocks. Since we're // allocating from these, they need to be black like // other allocations. The alternative is to blacken // the tiny block on every allocation from it, which // would slow down the tiny allocator. // ж Үи®° tiny еҜ№иұЎ gcMarkTinyAllocs() // At this point all Ps have enabled the write // barrier, thus maintaining the no white to // black invariant. Enable mutator assists to // put back-pressure on fast allocating // mutators. // и®ҫзҪ® gcBlackenEnabled дёә 1пјҢеҗҜз”ЁеҶҷеұҸйҡң atomic.Store(&gcBlackenEnabled, 1) // Assists and workers can start the moment we start // the world. gcController.markStartTime = now // Concurrent mark. systemstack(func() { now = startTheWorldWithSema(trace.enabled) }) work.pauseNS += now - work.pauseStart work.tMark = now } else { // йқһ并иЎҢжЁЎејҸ // и®°еҪ•е®ҢжҲҗж Үи®°йҳ¶ж®өзҡ„ејҖе§Ӣж—¶й—ҙ if trace.enabled { // Switch to mark termination STW. traceGCSTWDone() traceGCSTWStart(0) } t := nanotime() work.tMark, work.tMarkTerm = t, t workwork.heapGoal = work.heap0 // Perform mark termination. This will restart the world. // stw,иҝӣиЎҢж Үи®°пјҢжё…жү«е№¶start the world gcMarkTermination(memstats.triggerRatio) } semrelease(&work.startSema) }gcBgMarkStartWorkers
иҝҷдёӘеҮҪж•°еҮҶеӨҮдёҖдәӣ жү§иЎҢbg markе·ҘдҪңзҡ„goroutineпјҢдҪҶжҳҜиҝҷдәӣgoroutine并дёҚжҳҜз«ӢеҚіе·ҘдҪңзҡ„пјҢиҖҢжҳҜеҲ°зӯүеҲ°GCзҡ„зҠ¶жҖҒиў«ж Үи®°дёәgcMark жүҚејҖе§Ӣе·ҘдҪңпјҢи§ҒдёҠдёӘеҮҪж•°зҡ„119иЎҢ
func gcBgMarkStartWorkers() { // Background marking is performed by per-P G's. Ensure that // each P has a background GC G. for _, p := range allp { if p.gcBgMarkWorker == 0 { go gcBgMarkWorker(p) // зӯүеҫ…gcBgMarkWorker goroutine зҡ„ bgMarkReadyдҝЎеҸ·еҶҚ继з»ӯ notetsleepg(&work.bgMarkReady, -1) noteclear(&work.bgMarkReady) } } }gcBgMarkWorker
еҗҺеҸ°ж Үи®°д»»еҠЎзҡ„еҮҪж•°
func gcBgMarkWorker(_p_ *p) { gp := getg() // з”ЁдәҺдј‘зң з»“жқҹеҗҺйҮҚж–°иҺ·еҸ–pе’Ңm type parkInfo struct { m muintptr // Release this m on park. attach puintptr // If non-nil, attach to this p on park. } // We pass park to a gopark unlock function, so it can't be on // the stack (see gopark). Prevent deadlock from recursively // starting GC by disabling preemption. gp.m.preemptoff = "GC worker init" park := new(parkInfo) gp.m.preemptoff = "" // и®ҫзҪ®parkзҡ„mе’Ңpзҡ„дҝЎжҒҜпјҢз•ҷзқҖеҗҺйқўдј з»ҷgoparkпјҢеңЁиў«gcController.findRunnableе”ӨйҶ’зҡ„ж—¶еҖҷпјҢдҫҝдәҺжүҫеӣһ park.m.set(acquirem()) park.attach.set(_p_) // Inform gcBgMarkStartWorkers that this worker is ready. // After this point, the background mark worker is scheduled // cooperatively by gcController.findRunnable. Hence, it must // never be preempted, as this would put it into _Grunnable // and put it on a run queue. Instead, when the preempt flag // is set, this puts itself into _Gwaiting to be woken up by // gcController.findRunnable at the appropriate time. // и®©gcBgMarkStartWorkers notetsleepgеҒңжӯўзӯүеҫ…并继з»ӯеҸҠйҖҖеҮә notewakeup(&work.bgMarkReady) for { // Go to sleep until woken by gcController.findRunnable. // We can't releasem yet since even the call to gopark // may be preempted. // и®©gиҝӣе…Ҙдј‘зң gopark(func(g *g, parkp unsafe.Pointer) bool { park := (*parkInfo)(parkp) // The worker G is no longer running, so it's // now safe to allow preemption. // йҮҠж”ҫеҪ“еүҚжҠўеҚ зҡ„m releasem(park.m.ptr()) // If the worker isn't attached to its P, // attach now. During initialization and after // a phase change, the worker may have been // running on a different P. As soon as we // attach, the owner P may schedule the // worker, so this must be done after the G is // stopped. // и®ҫзҪ®е…іиҒ”pпјҢдёҠйқўе·Із»Ҹи®ҫзҪ®иҝҮдәҶ if park.attach != 0 { p := park.attach.ptr() park.attach.set(nil) // cas the worker because we may be // racing with a new worker starting // on this P. if !p.gcBgMarkWorker.cas(0, guintptr(unsafe.Pointer(g))) { // The P got a new worker. // Exit this worker. return false } } return true }, unsafe.Pointer(park), waitReasonGCWorkerIdle, traceEvGoBlock, 0) // Loop until the P dies and disassociates this // worker (the P may later be reused, in which case // it will get a new worker) or we failed to associate. // жЈҖжҹҘPзҡ„gcBgMarkWorkerжҳҜеҗҰе’ҢеҪ“еүҚзҡ„GдёҖиҮҙ, дёҚдёҖиҮҙж—¶з»“жқҹеҪ“еүҚзҡ„д»»еҠЎ if _p_.gcBgMarkWorker.ptr() != gp { break } // Disable preemption so we can use the gcw. If the // scheduler wants to preempt us, we'll stop draining, // dispose the gcw, and then preempt. // gopark第дёҖдёӘеҮҪж•°дёӯйҮҠж”ҫдәҶmпјҢиҝҷйҮҢеҶҚжҠўеҚ еӣһжқҘ park.m.set(acquirem()) if gcBlackenEnabled == 0 { throw("gcBgMarkWorker: blackening not enabled") } startTime := nanotime() // и®ҫзҪ®gcmarkзҡ„ејҖе§Ӣж—¶й—ҙ _p_.gcMarkWorkerStartTime = startTime decnwait := atomic.Xadd(&work.nwait, -1) if decnwait == work.nproc { println("runtime: workwork.nwait=", decnwait, "work.nproc=", work.nproc) throw("work.nwait was > work.nproc") } // еҲҮжҚўеҲ°g0е·ҘдҪң systemstack(func() { // Mark our goroutine preemptible so its stack // can be scanned. This lets two mark workers // scan each other (otherwise, they would // deadlock). We must not modify anything on // the G stack. However, stack shrinking is // disabled for mark workers, so it is safe to // read from the G stack. // и®ҫзҪ®Gзҡ„зҠ¶жҖҒдёәwaitingпјҢд»ҘдҫҝдәҺеҸҰдёҖдёӘgжү«жҸҸе®ғзҡ„ж Ҳ(дёӨдёӘgеҸҜд»Ҙдә’зӣёжү«жҸҸеҜ№ж–№зҡ„ж Ҳ) casgstatus(gp, _Grunning, _Gwaiting) switch _p_.gcMarkWorkerMode { default: throw("gcBgMarkWorker: unexpected gcMarkWorkerMode") case gcMarkWorkerDedicatedMode: // дё“еҝғжү§иЎҢж Үи®°е·ҘдҪңзҡ„жЁЎејҸ gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit) if gp.preempt { // иў«жҠўеҚ дәҶпјҢжҠҠжүҖжңүжң¬ең°иҝҗиЎҢйҳҹеҲ—дёӯзҡ„Gж”ҫеҲ°е…ЁеұҖиҝҗиЎҢйҳҹеҲ—дёӯ // We were preempted. This is // a useful signal to kick // everything out of the run // queue so it can run // somewhere else. lock(&sched.lock) for { gp, _ := runqget(_p_) if gp == nil { break } globrunqput(gp) } unlock(&sched.lock) } // Go back to draining, this time // without preemption. // 继з»ӯжү§иЎҢж Үи®°е·ҘдҪң gcDrain(&_p_.gcw, gcDrainNoBlock|gcDrainFlushBgCredit) case gcMarkWorkerFractionalMode: // жү§иЎҢж Үи®°е·ҘдҪңпјҢзҹҘйҒ“иў«жҠўеҚ gcDrain(&_p_.gcw, gcDrainFractional|gcDrainUntilPreempt|gcDrainFlushBgCredit) case gcMarkWorkerIdleMode: // з©әй—Ізҡ„ж—¶еҖҷжү§иЎҢж Үи®°е·ҘдҪң gcDrain(&_p_.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit) } // жҠҠGзҡ„waitingзҠ¶жҖҒиҪ¬жҚўеҲ°runingзҠ¶жҖҒ casgstatus(gp, _Gwaiting, _Grunning) }) // If we are nearing the end of mark, dispose // of the cache promptly. We must do this // before signaling that we're no longer // working so that other workers can't observe // no workers and no work while we have this // cached, and before we compute done. // еҸҠж—¶еӨ„зҗҶжң¬ең°зј“еӯҳпјҢдёҠдәӨеҲ°е…ЁеұҖзҡ„йҳҹеҲ—дёӯ if gcBlackenPromptly { _p_.gcw.dispose() } // Account for time. // зҙҜеҠ иҖ—ж—¶ duration := nanotime() - startTime switch _p_.gcMarkWorkerMode { case gcMarkWorkerDedicatedMode: atomic.Xaddint64(&gcController.dedicatedMarkTime, duration) atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, 1) case gcMarkWorkerFractionalMode: atomic.Xaddint64(&gcController.fractionalMarkTime, duration) atomic.Xaddint64(&_p_.gcFractionalMarkTime, duration) case gcMarkWorkerIdleMode: atomic.Xaddint64(&gcController.idleMarkTime, duration) } // Was this the last worker and did we run out // of work? incnwait := atomic.Xadd(&work.nwait, +1) if incnwait > work.nproc { println("runtime: p.gcMarkWorkerMode=", _p_.gcMarkWorkerMode, "workwork.nwait=", incnwait, "work.nproc=", work.nproc) throw("work.nwait > work.nproc") } // If this worker reached a background mark completion // point, signal the main GC goroutine. if incnwait == work.nproc && !gcMarkWorkAvailable(nil) { // Make this G preemptible and disassociate it // as the worker for this P so // findRunnableGCWorker doesn't try to // schedule it. // еҸ–ж¶Ҳp mзҡ„е…іиҒ” _p_.gcBgMarkWorker.set(nil) releasem(park.m.ptr()) gcMarkDone() // Disable preemption and prepare to reattach // to the P. // // We may be running on a different P at this // point, so we can't reattach until this G is // parked. park.m.set(acquirem()) park.attach.set(_p_) } } }gcDrain
дёүиүІж Үи®°зҡ„дё»иҰҒе®һзҺ°
gcDrainжү«жҸҸжүҖжңүзҡ„rootsе’ҢеҜ№иұЎпјҢ并表黑зҒ°иүІеҜ№иұЎпјҢзҹҘйҒ“жүҖжңүзҡ„rootsе’ҢеҜ№иұЎйғҪиў«ж Үи®°
func gcDrain(gcw *gcWork, flags gcDrainFlags) { if !writeBarrier.needed { throw("gcDrain phase incorrect") } gp := getg().m.curg // зңӢеҲ°жҠўеҚ ж ҮиҜҶжҳҜеҗҰиҰҒиҝ”еӣһ preemptible := flags&gcDrainUntilPreempt != 0 // жІЎжңүд»»еҠЎж—¶жҳҜеҗҰиҰҒзӯүеҫ…д»»еҠЎ blocking := flags&(gcDrainUntilPreempt|gcDrainIdle|gcDrainFractional|gcDrainNoBlock) == 0 // жҳҜеҗҰи®Ўз®—еҗҺеҸ°зҡ„жү«жҸҸйҮҸжқҘеҮҸе°‘иҫ…еҠ©GCе’Ңе”ӨйҶ’зӯүеҫ…дёӯзҡ„G flushBgCredit := flags&gcDrainFlushBgCredit != 0 // жҳҜеҗҰеңЁз©әй—Ізҡ„ж—¶еҖҷжү§иЎҢж Үи®°д»»еҠЎ idle := flags&gcDrainIdle != 0 // и®°еҪ•еҲқе§Ӣзҡ„е·Із»Ҹжү§иЎҢиҝҮзҡ„жү«жҸҸд»»еҠЎ initScanWork := gcw.scanWork // checkWork is the scan work before performing the next // self-preempt check. // и®ҫзҪ®еҜ№еә”жЁЎејҸзҡ„е·ҘдҪңжЈҖжҹҘеҮҪж•° checkWork := int64(1<<63 - 1) var check func() bool if flags&(gcDrainIdle|gcDrainFractional) != 0 { checkWork = initScanWork + drainCheckThreshold if idle { check = pollWork } else if flags&gcDrainFractional != 0 { check = pollFractionalWorkerExit } } // Drain root marking jobs. // еҰӮжһңrootеҜ№иұЎжІЎжңүжү«жҸҸе®ҢпјҢеҲҷжү«жҸҸ if work.markrootNext < work.markrootJobs { for !(preemptible && gp.preempt) { job := atomic.Xadd(&work.markrootNext, +1) - 1 if job >= work.markrootJobs { break } // жү§иЎҢrootжү«жҸҸд»»еҠЎ markroot(gcw, job) if check != nil && check() { goto done } } } // Drain heap marking jobs. // еҫӘзҺҜзӣҙеҲ°иў«жҠўеҚ for !(preemptible && gp.preempt) { // Try to keep work available on the global queue. We used to // check if there were waiting workers, but it's better to // just keep work available than to make workers wait. In the // worst case, we'll do O(log(_WorkbufSize)) unnecessary // balances. if work.full == 0 { // е№іиЎЎе·ҘдҪңпјҢеҰӮжһңе…ЁеұҖзҡ„ж Үи®°йҳҹеҲ—дёәз©әпјҢеҲҷеҲҶдёҖйғЁеҲҶе·ҘдҪңеҲ°е…ЁеұҖйҳҹеҲ—дёӯ gcw.balance() } var b uintptr if blocking { b = gcw.get() } else { b = gcw.tryGetFast() if b == 0 { b = gcw.tryGet() } } // иҺ·еҸ–д»»еҠЎеӨұиҙҘпјҢи·іеҮәеҫӘзҺҜ if b == 0 { // work barrier reached or tryGet failed. break } // жү«жҸҸиҺ·еҸ–зҡ„еҲ°еҜ№иұЎ scanobject(b, gcw) // Flush background scan work credit to the global // account if we've accumulated enough locally so // mutator assists can draw on it. // еҰӮжһңеҪ“еүҚжү«жҸҸзҡ„ж•°йҮҸи¶…иҝҮдәҶ gcCreditSlackпјҢе°ұжҠҠжү«жҸҸзҡ„еҜ№иұЎж•°йҮҸеҠ еҲ°е…ЁеұҖзҡ„ж•°йҮҸпјҢжү№йҮҸжӣҙж–° if gcw.scanWork >= gcCreditSlack { atomic.Xaddint64(&gcController.scanWork, gcw.scanWork) if flushBgCredit { gcFlushBgCredit(gcw.scanWork - initScanWork) initScanWork = 0 } checkWork -= gcw.scanWork gcw.scanWork = 0 // еҰӮжһңжү«жҸҸзҡ„еҜ№иұЎж•°йҮҸе·Із»ҸиҫҫеҲ°дәҶ жү§иЎҢдёӢж¬ЎжҠўеҚ зҡ„зӣ®ж Үж•°йҮҸ checkWorkпјҢ еҲҷи°ғз”ЁеҜ№еә”жЁЎејҸзҡ„еҮҪж•° // idleжЁЎејҸдёә pollWorkпјҢ FractionalжЁЎејҸдёә pollFractionalWorkerExit пјҢеңЁз¬¬20иЎҢ if checkWork <= 0 { checkWork += drainCheckThreshold if check != nil && check() { break } } } } // In blocking mode, write barriers are not allowed after this // point because we must preserve the condition that the work // buffers are empty. done: // Flush remaining scan work credit. if gcw.scanWork > 0 { // жҠҠжү«жҸҸзҡ„еҜ№иұЎж•°йҮҸж·»еҠ еҲ°е…ЁеұҖ atomic.Xaddint64(&gcController.scanWork, gcw.scanWork) if flushBgCredit { gcFlushBgCredit(gcw.scanWork - initScanWork) } gcw.scanWork = 0 } }markroot
иҝҷдёӘиў«з”ЁдәҺж №еҜ№иұЎжү«жҸҸ
func markroot(gcw *gcWork, i uint32) { // TODO(austin): This is a bit ridiculous. Compute and store // the bases in gcMarkRootPrepare instead of the counts. baseFlushCache := uint32(fixedRootCount) baseData := baseFlushCache + uint32(work.nFlushCacheRoots) baseBSS := baseData + uint32(work.nDataRoots) baseSpans := baseBSS + uint32(work.nBSSRoots) baseStacks := baseSpans + uint32(work.nSpanRoots) end := baseStacks + uint32(work.nStackRoots) // Note: if you add a case here, please also update heapdump.go:dumproots. switch { // йҮҠж”ҫmcacheдёӯзҡ„span case baseFlushCache <= i && i < baseData: flushmcache(int(i - baseFlushCache)) // жү«жҸҸеҸҜиҜ»еҶҷзҡ„е…ЁеұҖеҸҳйҮҸ case baseData <= i && i < baseBSS: for _, datap := range activeModules() { markrootBlock(datap.data, datap.edata-datap.data, datap.gcdatamask.bytedata, gcw, int(i-baseData)) } // жү«жҸҸеҸӘиҜ»зҡ„е…ЁеұҖйҳҹеҲ— case baseBSS <= i && i < baseSpans: for _, datap := range activeModules() { markrootBlock(datap.bss, datap.ebss-datap.bss, datap.gcbssmask.bytedata, gcw, int(i-baseBSS)) } // жү«жҸҸFinalizerйҳҹеҲ— case i == fixedRootFinalizers: // Only do this once per GC cycle since we don't call // queuefinalizer during marking. if work.markrootDone { break } for fb := allfin; fb != nil; fbfb = fb.alllink { cnt := uintptr(atomic.Load(&fb.cnt)) scanblock(uintptr(unsafe.Pointer(&fb.fin[0])), cnt*unsafe.Sizeof(fb.fin[0]), &finptrmask[0], gcw) } // йҮҠж”ҫе·Із»Ҹз»Ҳжӯўзҡ„stack case i == fixedRootFreeGStacks: // Only do this once per GC cycle; preferably // concurrently. if !work.markrootDone { // Switch to the system stack so we can call // stackfree. systemstack(markrootFreeGStacks) } // жү«жҸҸMSpan.specials case baseSpans <= i && i < baseStacks: // mark MSpan.specials markrootSpans(gcw, int(i-baseSpans)) default: // the rest is scanning goroutine stacks // иҺ·еҸ–йңҖиҰҒжү«жҸҸзҡ„g var gp *g if baseStacks <= i && i < end { gp = allgs[i-baseStacks] } else { throw("markroot: bad index") } // remember when we've first observed the G blocked // needed only to output in traceback status := readgstatus(gp) // We are not in a scan state if (status == _Gwaiting || status == _Gsyscall) && gp.waitsince == 0 { gp.waitsince = work.tstart } // scang must be done on the system stack in case // we're trying to scan our own stack. // иҪ¬дәӨз»ҷg0иҝӣиЎҢжү«жҸҸ systemstack(func() { // If this is a self-scan, put the user G in // _Gwaiting to prevent self-deadlock. It may // already be in _Gwaiting if this is a mark // worker or we're in mark termination. userG := getg().m.curg selfScan := gp == userG && readgstatus(userG) == _Grunning // еҰӮжһңжҳҜжү«жҸҸиҮӘе·ұзҡ„пјҢеҲҷиҪ¬жҚўиҮӘе·ұзҡ„gзҡ„зҠ¶жҖҒ if selfScan { casgstatus(userG, _Grunning, _Gwaiting) userG.waitreason = waitReasonGarbageCollectionScan } // TODO: scang blocks until gp's stack has // been scanned, which may take a while for // running goroutines. Consider doing this in // two phases where the first is non-blocking: // we scan the stacks we can and ask running // goroutines to scan themselves; and the // second blocks. // жү«жҸҸgзҡ„ж Ҳ scang(gp, gcw) if selfScan { casgstatus(userG, _Gwaiting, _Grunning) } }) } }markRootBlock
ж №жҚ® ptrmask0пјҢжқҘжү«жҸҸ[b0, b0+n0)еҢәеҹҹ
func markrootBlock(b0, n0 uintptr, ptrmask0 *uint8, gcw *gcWork, shard int) { if rootBlockBytes%(8*sys.PtrSize) != 0 { // This is necessary to pick byte offsets in ptrmask0. throw("rootBlockBytes must be a multiple of 8*ptrSize") } b := b0 + uintptr(shard)*rootBlockBytes // еҰӮжһңйңҖжү«жҸҸзҡ„blockеҢәеҹҹпјҢи¶…еҮәb0+n0зҡ„еҢәеҹҹпјҢзӣҙжҺҘиҝ”еӣһ if b >= b0+n0 { return } ptrmask := (*uint8)(add(unsafe.Pointer(ptrmask0), uintptr(shard)*(rootBlockBytes/(8*sys.PtrSize)))) n := uintptr(rootBlockBytes) if b+n > b0+n0 { n = b0 + n0 - b } // Scan this shard. // жү«жҸҸз»ҷе®ҡblockзҡ„shard scanblock(b, n, ptrmask, gcw) }scanblock
func scanblock(b0, n0 uintptr, ptrmask *uint8, gcw *gcWork) { // Use local copies of original parameters, so that a stack trace // due to one of the throws below shows the original block // base and extent. b := b0 n := n0 for i := uintptr(0); i < n; { // Find bits for the next word. // жүҫеҲ°bitmapдёӯеҜ№еә”зҡ„bits bits := uint32(*addb(ptrmask, i/(sys.PtrSize*8))) if bits == 0 { i += sys.PtrSize * 8 continue } for j := 0; j < 8 && i < n; j++ { if bits&1 != 0 { // еҰӮжһңиҜҘең°еқҖеҢ…еҗ«жҢҮй’Ҳ // Same work as in scanobject; see comments there. obj := *(*uintptr)(unsafe.Pointer(b + i)) if obj != 0 { // еҰӮжһңиҜҘең°еқҖдёӢжүҫеҲ°дәҶеҜ№еә”зҡ„еҜ№иұЎпјҢж ҮзҒ° if obj, span, objIndex := findObject(obj, b, i); obj != 0 { greyobject(obj, b, i, span, gcw, objIndex) } } } bits >>= 1 i += sys.PtrSize } } }greyobject
ж ҮзҒ°еҜ№иұЎе…¶е®һе°ұжҳҜжүҫеҲ°еҜ№еә”bitmapпјҢж Үи®°еӯҳжҙ»е№¶жү”иҝӣйҳҹеҲ—
func greyobject(obj, base, off uintptr, span *mspan, gcw *gcWork, objIndex uintptr) { // obj should be start of allocation, and so must be at least pointer-aligned. if obj&(sys.PtrSize-1) != 0 { throw("greyobject: obj not pointer-aligned") } mbits := span.markBitsForIndex(objIndex) if useCheckmark { // иҝҷйҮҢжҳҜз”ЁжқҘdebugпјҢзЎ®дҝқжүҖжңүзҡ„еҜ№иұЎйғҪиў«жӯЈзЎ®ж ҮиҜҶ if !mbits.isMarked() { // иҝҷдёӘеҜ№иұЎжІЎжңүиў«ж Үи®° printlock() print("runtime:greyobject: checkmarks finds unexpected unmarked object obj=", hex(obj), "\n") print("runtime: found obj at *(", hex(base), "+", hex(off), ")\n") // Dump the source (base) object gcDumpObject("base", base, off) // Dump the object gcDumpObject("obj", obj, ^uintptr(0)) getg().m.traceback = 2 throw("checkmark found unmarked object") } hbits := heapBitsForAddr(obj) if hbits.isCheckmarked(span.elemsize) { return } hbits.setCheckmarked(span.elemsize) if !hbits.isCheckmarked(span.elemsize) { throw("setCheckmarked and isCheckmarked disagree") } } else { if debug.gccheckmark > 0 && span.isFree(objIndex) { print("runtime: marking free object ", hex(obj), " found at *(", hex(base), "+", hex(off), ")\n") gcDumpObject("base", base, off) gcDumpObject("obj", obj, ^uintptr(0)) getg().m.traceback = 2 throw("marking free object") } // If marked we have nothing to do. // еҜ№иұЎиў«жӯЈзЎ®ж Үи®°дәҶпјҢж— йңҖеҒҡе…¶д»–зҡ„ж“ҚдҪң if mbits.isMarked() { return } // mbits.setMarked() // Avoid extra call overhead with manual inlining. // ж Үи®°еҜ№иұЎ atomic.Or8(mbits.bytep, mbits.mask) // If this is a noscan object, fast-track it to black // instead of greying it. // еҰӮжһңеҜ№иұЎдёҚжҳҜжҢҮй’ҲпјҢеҲҷеҸӘйңҖиҰҒж Үи®°пјҢдёҚйңҖиҰҒж”ҫиҝӣйҳҹеҲ—пјҢзӣёеҪ“дәҺзӣҙжҺҘж Үй»‘ if span.spanclass.noscan() { gcw.bytesMarked += uint64(span.elemsize) return } } // Queue the obj for scanning. The PREFETCH(obj) logic has been removed but // seems like a nice optimization that can be added back in. // There needs to be time between the PREFETCH and the use. // Previously we put the obj in an 8 element buffer that is drained at a rate // to give the PREFETCH time to do its work. // Use of PREFETCHNTA might be more appropriate than PREFETCH // еҲӨж–ӯеҜ№иұЎжҳҜеҗҰиў«ж”ҫиҝӣйҳҹеҲ—пјҢжІЎжңүеҲҷж”ҫе…ҘпјҢж ҮзҒ°жӯҘйӘӨе®ҢжҲҗ if !gcw.putFast(obj) { gcw.put(obj) } }gcWork.putFast
workжңүwbuf1 wbuf2дёӨдёӘйҳҹеҲ—з”ЁдәҺдҝқеӯҳзҒ°иүІеҜ№иұЎпјҢйҰ–е…ҲдјҡеҫҖwbuf1йҳҹеҲ—йҮҢеҠ е…ҘзҒ°иүІеҜ№иұЎпјҢwbuf1ж»ЎдәҶеҗҺпјҢдәӨжҚўwbuf1е’Ңwbuf2пјҢиҝҷдәӢwbuf2дҫҝжҷӢеҚҮдёәwbuf1пјҢ继з»ӯеӯҳж”ҫзҒ°иүІеҜ№иұЎпјҢдёӨдёӘйҳҹеҲ—йғҪж»ЎдәҶпјҢеҲҷжғіе…ЁеұҖиҝӣиЎҢз”іиҜ·
putFastиҝҷйҮҢиҝӣе°қиҜ•е°ҶеҜ№иұЎж”ҫиҝӣwbuf1йҳҹеҲ—дёӯ
func (w *gcWork) putFast(obj uintptr) bool { wbuf := w.wbuf1 if wbuf == nil { // жІЎжңүз”іиҜ·зј“еӯҳйҳҹеҲ—пјҢиҝ”еӣһfalse return false } else if wbuf.nobj == len(wbuf.obj) { // wbuf1йҳҹеҲ—ж»ЎдәҶпјҢиҝ”еӣһfalse return false } // еҗ‘жңӘж»Ўwbuf1йҳҹеҲ—дёӯеҠ е…ҘеҜ№иұЎ wbuf.obj[wbuf.nobj] = obj wbuf.nobj++ return true }gcWork.put
putдёҚд»…е°қиҜ•е°ҶеҜ№иұЎж”ҫе…Ҙwbuf1пјҢиҝҳдјҡеҶҚwbuf1ж»Ўзҡ„ж—¶еҖҷпјҢе°қиҜ•жӣҙжҚўwbuf1 wbuf2зҡ„и§’иүІпјҢйғҪж»Ўзҡ„иҜқпјҢеҲҷжғіе…ЁеұҖиҝӣиЎҢз”іиҜ·пјҢ并е°Ҷж»Ўзҡ„йҳҹеҲ—дёҠдәӨеҲ°е…ЁеұҖйҳҹеҲ—
func (w *gcWork) put(obj uintptr) { flushed := false wbuf := w.wbuf1 if wbuf == nil { // еҰӮжһңwbuf1дёҚеӯҳеңЁпјҢеҲҷеҲқе§ӢеҢ–wbuf1 wbuf2дёӨдёӘйҳҹеҲ— w.init() wwbuf = w.wbuf1 // wbuf is empty at this point. } else if wbuf.nobj == len(wbuf.obj) { // wbuf1ж»ЎдәҶпјҢжӣҙжҚўwbuf1 wbuf2зҡ„и§’иүІ w.wbuf1, ww.wbuf2 = w.wbuf2, w.wbuf1 wwbuf = w.wbuf1 if wbuf.nobj == len(wbuf.obj) { // жӣҙжҚўи§’иүІеҗҺпјҢwbuf1д№ҹж»ЎдәҶпјҢиҜҙжҳҺдёӨдёӘйҳҹеҲ—йғҪж»ЎдәҶ // жҠҠ wbuf1дёҠдәӨе…ЁеұҖ并иҺ·еҸ–дёҖдёӘз©әзҡ„йҳҹеҲ— putfull(wbuf) wbuf = getempty() w.wbuf1 = wbuf // и®ҫзҪ®йҳҹеҲ—дёҠдәӨзҡ„ж Үеҝ—дҪҚ flushed = true } } wbuf.obj[wbuf.nobj] = obj wbuf.nobj++ // If we put a buffer on full, let the GC controller know so // it can encourage more workers to run. We delay this until // the end of put so that w is in a consistent state, since // enlistWorker may itself manipulate w. // жӯӨж—¶е…ЁеұҖе·Із»Ҹжңүж Үи®°ж»Ўзҡ„йҳҹеҲ—пјҢGC controllerйҖүжӢ©и°ғеәҰжӣҙеӨҡworkиҝӣиЎҢе·ҘдҪң if flushed && gcphase == _GCmark { gcController.enlistWorker() } }еҲ°иҝҷйҮҢпјҢжҺҘдёӢжқҘпјҢжҲ‘们继з»ӯеҲҶжһҗgcDrainйҮҢйқўзҡ„еҮҪж•°пјҢиҝҪиёӘдёҖдёӢпјҢжҲ‘们ж ҮзҒ°зҡ„еҜ№иұЎжҳҜеҰӮдҪ•иў«ж Үй»‘зҡ„
gcw.balance()
继з»ӯеҲҶжһҗ gcDrainзҡ„58иЎҢпјҢbalance workжҳҜд»Җд№Ҳ
func (w *gcWork) balance() { if w.wbuf1 == nil { // иҝҷйҮҢwbuf1 wbuf2йҳҹеҲ—иҝҳжІЎжңүеҲқе§ӢеҢ– return } // еҰӮжһңwbuf2дёҚдёәз©әпјҢеҲҷдёҠдәӨеҲ°е…ЁеұҖпјҢ并иҺ·еҸ–дёҖдёӘз©әеІӣйҳҹеҲ—з»ҷwbuf2 if wbuf := w.wbuf2; wbuf.nobj != 0 { putfull(wbuf) w.wbuf2 = getempty() } else if wbuf := w.wbuf1; wbuf.nobj > 4 { // жҠҠжңӘж»Ўзҡ„wbuf1еҲҶжҲҗдёӨеҚҠпјҢ并жҠҠе…¶дёӯдёҖеҚҠдёҠдәӨзҡ„е…ЁеұҖйҳҹеҲ— w.wbuf1 = handoff(wbuf) } else { return } // We flushed a buffer to the full list, so wake a worker. // иҝҷйҮҢпјҢе…ЁеұҖйҳҹеҲ—жңүж»Ўзҡ„йҳҹеҲ—дәҶпјҢе…¶д»–workеҸҜд»Ҙе·ҘдҪңдәҶ if gcphase == _GCmark { gcController.enlistWorker() } }gcw.get()
继з»ӯеҲҶжһҗ gcDrainзҡ„63иЎҢпјҢиҝҷйҮҢе°ұжҳҜйҰ–е…Ҳд»Һжң¬ең°зҡ„йҳҹеҲ—иҺ·еҸ–дёҖдёӘеҜ№иұЎпјҢеҰӮжһңжң¬ең°йҳҹеҲ—зҡ„wbuf1жІЎжңүпјҢе°қиҜ•д»Һwbuf2иҺ·еҸ–пјҢеҰӮжһңдёӨдёӘйғҪжІЎжңүпјҢеҲҷе°қиҜ•д»Һе…ЁеұҖйҳҹеҲ—иҺ·еҸ–дёҖдёӘж»Ўзҡ„йҳҹеҲ—пјҢ并иҺ·еҸ–дёҖдёӘеҜ№иұЎ
func (w *gcWork) get() uintptr { wbuf := w.wbuf1 if wbuf == nil { w.init() wwbuf = w.wbuf1 // wbuf is empty at this point. } if wbuf.nobj == 0 { // wbuf1з©әдәҶпјҢжӣҙжҚўwbuf1 wbuf2зҡ„и§’иүІ w.wbuf1, ww.wbuf2 = w.wbuf2, w.wbuf1 wwbuf = w.wbuf1 // еҺҹwbuf2д№ҹжҳҜз©әзҡ„пјҢе°қиҜ•д»Һе…ЁеұҖйҳҹеҲ—иҺ·еҸ–дёҖдёӘж»Ўзҡ„йҳҹеҲ— if wbuf.nobj == 0 { owbuf := wbuf wbuf = getfull() // иҺ·еҸ–дёҚеҲ°пјҢеҲҷиҝ”еӣһ if wbuf == nil { return 0 } // жҠҠз©әзҡ„йҳҹеҲ—дёҠдј еҲ°е…ЁеұҖз©әйҳҹеҲ—пјҢ并жҠҠиҺ·еҸ–зҡ„ж»Ўзҡ„йҳҹеҲ—пјҢдҪңдёәиҮӘиә«зҡ„wbuf1 putempty(owbuf) w.wbuf1 = wbuf } } // TODO: This might be a good place to add prefetch code wbuf.nobj-- return wbuf.obj[wbuf.nobj] }gcw.tryGet() gcw.tryGetFast() йҖ»иҫ‘е·®дёҚеӨҡпјҢзӣёеҜ№жҜ”иҫғз®ҖеҚ•пјҢе°ұдёҚ继з»ӯеҲҶжһҗдәҶ
scanobject
жҲ‘们继з»ӯеҲҶжһҗеҲ° gcDrain зҡ„L76пјҢиҝҷйҮҢе·Із»ҸиҺ·еҸ–еҲ°дәҶbпјҢејҖе§Ӣж¶Ҳиҙ№йҳҹеҲ—
func scanobject(b uintptr, gcw *gcWork) { // Find the bits for b and the size of the object at b. // // b is either the beginning of an object, in which case this // is the size of the object to scan, or it points to an // oblet, in which case we compute the size to scan below. // иҺ·еҸ–bеҜ№еә”зҡ„bits hbits := heapBitsForAddr(b) // иҺ·еҸ–bжүҖеңЁзҡ„span s := spanOfUnchecked(b) n := s.elemsize if n == 0 { throw("scanobject n == 0") } // еҜ№иұЎиҝҮеӨ§пјҢеҲҷеҲҮеүІеҗҺеҶҚжү«жҸҸпјҢmaxObletBytesдёә128k if n > maxObletBytes { // Large object. Break into oblets for better // parallelism and lower latency. if b == s.base() { // It's possible this is a noscan object (not // from greyobject, but from other code // paths), in which case we must *not* enqueue // oblets since their bitmaps will be // uninitialized. // еҰӮжһңдёҚжҳҜжҢҮй’ҲпјҢзӣҙжҺҘж Үи®°иҝ”еӣһпјҢзӣёеҪ“дәҺж Үй»‘дәҶ if s.spanclass.noscan() { // Bypass the whole scan. gcw.bytesMarked += uint64(n) return } // Enqueue the other oblets to scan later. // Some oblets may be in b's scalar tail, but // these will be marked as "no more pointers", // so we'll drop out immediately when we go to // scan those. // жҢүmaxObletBytesеҲҮеүІеҗҺж”ҫе…ҘеҲ° йҳҹеҲ— for oblet := b + maxObletBytes; oblet < s.base()+s.elemsize; oblet += maxObletBytes { if !gcw.putFast(oblet) { gcw.put(oblet) } } } // Compute the size of the oblet. Since this object // must be a large object, s.base() is the beginning // of the object. n = s.base() + s.elemsize - b if n > maxObletBytes { n = maxObletBytes } } var i uintptr for i = 0; i < n; i += sys.PtrSize { // Find bits for this word. // иҺ·еҸ–еҲ°еҜ№еә”зҡ„bits if i != 0 { // Avoid needless hbits.next() on last iteration. hbitshbits = hbits.next() } // Load bits once. See CL 22712 and issue 16973 for discussion. bits := hbits.bits() // During checkmarking, 1-word objects store the checkmark // in the type bit for the one word. The only one-word objects // are pointers, or else they'd be merged with other non-pointer // data into larger allocations. if i != 1*sys.PtrSize && bits&bitScan == 0 { break // no more pointers in this object } // дёҚжҳҜжҢҮй’ҲпјҢ继з»ӯ if bits&bitPointer == 0 { continue // not a pointer } // Work here is duplicated in scanblock and above. // If you make changes here, make changes there too. obj := *(*uintptr)(unsafe.Pointer(b + i)) // At this point we have extracted the next potential pointer. // Quickly filter out nil and pointers back to the current object. if obj != 0 && obj-b >= n { // Test if obj points into the Go heap and, if so, // mark the object. // // Note that it's possible for findObject to // fail if obj points to a just-allocated heap // object because of a race with growing the // heap. In this case, we know the object was // just allocated and hence will be marked by // allocation itself. // жүҫеҲ°жҢҮй’ҲеҜ№еә”зҡ„еҜ№иұЎпјҢ并ж ҮзҒ° if obj, span, objIndex := findObject(obj, b, i); obj != 0 { greyobject(obj, b, i, span, gcw, objIndex) } } } gcw.bytesMarked += uint64(n) gcw.scanWork += int64(i) }з»јдёҠпјҢжҲ‘们еҸҜд»ҘеҸ‘зҺ°пјҢж ҮзҒ°е°ұжҳҜж Ү记并ж”ҫиҝӣйҳҹеҲ—пјҢж Үй»‘е°ұжҳҜж Үи®°пјҢжүҖд»ҘеҪ“зҒ°иүІеҜ№иұЎд»ҺйҳҹеҲ—дёӯеҸ–еҮәеҗҺпјҢжҲ‘们е°ұеҸҜд»Ҙи®ӨдёәиҝҷдёӘеҜ№иұЎжҳҜй»‘иүІеҜ№иұЎдәҶ
иҮіжӯӨпјҢgcDrainзҡ„ж Үи®°е·ҘдҪңеҲҶжһҗе®ҢжҲҗпјҢжҲ‘们继з»ӯеӣһеҲ°gcBgMarkWorkerеҲҶжһҗ
gcMarkDone
gcMarkDoneдјҡе°Ҷmark1йҳ¶ж®өиҝӣе…ҘеҲ°mark2йҳ¶ж®өпјҢ mark2йҳ¶ж®өиҝӣе…ҘеҲ°mark terminationйҳ¶ж®ө
mark1йҳ¶ж®өпјҡ еҢ…жӢ¬жүҖжңүrootж Үи®°пјҢе…ЁеұҖзј“еӯҳйҳҹеҲ—е’Ңжң¬ең°зј“еӯҳйҳҹеҲ—
mark2йҳ¶ж®өпјҡжң¬ең°зј“еӯҳйҳҹеҲ—дјҡиў«зҰҒз”Ё
func gcMarkDone() { top: semacquire(&work.markDoneSema) // Re-check transition condition under transition lock. if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) { semrelease(&work.markDoneSema) return } // Disallow starting new workers so that any remaining workers // in the current mark phase will drain out. // // TODO(austin): Should dedicated workers keep an eye on this // and exit gcDrain promptly? // зҰҒжӯўж–°зҡ„ж Үи®°д»»еҠЎ atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, -0xffffffff) prevFractionalGoal := gcController.fractionalUtilizationGoal gcController.fractionalUtilizationGoal = 0 // еҰӮжһңgcBlackenPromptlyиЎЁеҗҚйңҖиҰҒжүҖжңүжң¬ең°зј“еӯҳйҳҹеҲ—з«ӢеҚідёҠдәӨеҲ°е…ЁеұҖйҳҹеҲ—пјҢ并зҰҒз”Ёжң¬ең°зј“еӯҳйҳҹеҲ— if !gcBlackenPromptly { // Transition from mark 1 to mark 2. // // The global work list is empty, but there can still be work // sitting in the per-P work caches. // Flush and disable work caches. // Disallow caching workbufs and indicate that we're in mark 2. // зҰҒз”Ёжң¬ең°зј“еӯҳйҳҹеҲ—пјҢиҝӣе…Ҙmark2йҳ¶ж®ө gcBlackenPromptly = true // Prevent completion of mark 2 until we've flushed // cached workbufs. atomic.Xadd(&work.nwait, -1) // GC is set up for mark 2. Let Gs blocked on the // transition lock go while we flush caches. semrelease(&work.markDoneSema) // еҲҮжҚўеҲ°g0жү§иЎҢпјҢжң¬ең°зј“еӯҳдёҠдј еҲ°е…ЁеұҖзҡ„ж“ҚдҪң systemstack(func() { // Flush all currently cached workbufs and // ensure all Ps see gcBlackenPromptly. This // also blocks until any remaining mark 1 // workers have exited their loop so we can // start new mark 2 workers. forEachP(func(_p_ *p) { wbBufFlush2(_p_) _p_.gcw.dispose() }) }) // Check that roots are marked. We should be able to // do this before the forEachP, but based on issue // #16083 there may be a (harmless) race where we can // enter mark 2 while some workers are still scanning // stacks. The forEachP ensures these scans are done. // // TODO(austin): Figure out the race and fix this // properly. // жЈҖжҹҘжүҖжңүзҡ„rootжҳҜеҗҰйғҪиў«ж Үи®°дәҶ gcMarkRootCheck() // Now we can start up mark 2 workers. atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, 0xffffffff) gcController.fractionalUtilizationGoal = prevFractionalGoal incnwait := atomic.Xadd(&work.nwait, +1) // еҰӮжһңжІЎжңүжӣҙеӨҡзҡ„д»»еҠЎпјҢеҲҷжү§иЎҢ第дәҢж¬Ўи°ғз”ЁпјҢд»Һmark2йҳ¶ж®өиҪ¬жҚўеҲ°mark terminationйҳ¶ж®ө if incnwait == work.nproc && !gcMarkWorkAvailable(nil) { // This loop will make progress because // gcBlackenPromptly is now true, so it won't // take this same "if" branch. goto top } } else { // Transition to mark termination. now := nanotime() work.tMarkTerm = now work.pauseStart = now getg().m.preemptoff = "gcing" if trace.enabled { traceGCSTWStart(0) } systemstack(stopTheWorldWithSema) // The gcphase is _GCmark, it will transition to _GCmarktermination // below. The important thing is that the wb remains active until // all marking is complete. This includes writes made by the GC. // Record that one root marking pass has completed. work.markrootDone = true // Disable assists and background workers. We must do // this before waking blocked assists. atomic.Store(&gcBlackenEnabled, 0) // Wake all blocked assists. These will run when we // start the world again. // е”ӨйҶ’жүҖжңүзҡ„иҫ…еҠ©GC gcWakeAllAssists() // Likewise, release the transition lock. Blocked // workers and assists will run when we start the // world again. semrelease(&work.markDoneSema) // endCycle depends on all gcWork cache stats being // flushed. This is ensured by mark 2. // и®Ўз®—дёӢдёҖж¬ЎgcеҮәеҸ‘зҡ„йҳҲеҖј nextTriggerRatio := gcController.endCycle() // Perform mark termination. This will restart the world. // start the worldпјҢ并иҝӣе…Ҙе®ҢжҲҗйҳ¶ж®ө gcMarkTermination(nextTriggerRatio) } }gcMarkTermination
з»“жқҹж Үи®°пјҢ并иҝӣиЎҢжё…жү«зӯүе·ҘдҪң
func gcMarkTermination(nextTriggerRatio float64) { // World is stopped. // Start marktermination which includes enabling the write barrier. atomic.Store(&gcBlackenEnabled, 0) gcBlackenPromptly = false // и®ҫзҪ®GCзҡ„йҳ¶ж®өж ҮиҜҶ setGCPhase(_GCmarktermination) work.heap1 = memstats.heap_live startTime := nanotime() mp := acquirem() mp.preemptoff = "gcing" _g_ := getg() _g_.m.traceback = 2 gp := _g_.m.curg // и®ҫзҪ®еҪ“еүҚgзҡ„зҠ¶жҖҒдёәwaitingзҠ¶жҖҒ casgstatus(gp, _Grunning, _Gwaiting) gp.waitreason = waitReasonGarbageCollection // Run gc on the g0 stack. We do this so that the g stack // we're currently running on will no longer change. Cuts // the root set down a bit (g0 stacks are not scanned, and // we don't need to scan gc's internal state). We also // need to switch to g0 so we can shrink the stack. systemstack(func() { // йҖҡиҝҮg0жү«жҸҸеҪ“еүҚgзҡ„ж Ҳ gcMark(startTime) // Must return immediately. // The outer function's stack may have moved // during gcMark (it shrinks stacks, including the // outer function's stack), so we must not refer // to any of its variables. Return back to the // non-system stack to pick up the new addresses // before continuing. }) systemstack(func() { workwork.heap2 = work.bytesMarked if debug.gccheckmark > 0 { // Run a full stop-the-world mark using checkmark bits, // to check that we didn't forget to mark anything during // the concurrent mark process. // еҰӮжһңеҗҜз”ЁдәҶgccheckmarkпјҢеҲҷжЈҖжҹҘжүҖжңүеҸҜиҫҫеҜ№иұЎжҳҜеҗҰйғҪжңүж Үи®° gcResetMarkState() initCheckmarks() gcMark(startTime) clearCheckmarks() } // marking is complete so we can turn the write barrier off // и®ҫзҪ®gcзҡ„йҳ¶ж®өж ҮиҜҶпјҢGCoffж—¶дјҡе…ій—ӯеҶҷеұҸйҡң setGCPhase(_GCoff) // ејҖе§Ӣжё…жү« gcSweep(work.mode) if debug.gctrace > 1 { startTime = nanotime() // The g stacks have been scanned so // they have gcscanvalid==true and gcworkdone==true. // Reset these so that all stacks will be rescanned. gcResetMarkState() finishsweep_m() // Still in STW but gcphase is _GCoff, reset to _GCmarktermination // At this point all objects will be found during the gcMark which // does a complete STW mark and object scan. setGCPhase(_GCmarktermination) gcMark(startTime) setGCPhase(_GCoff) // marking is done, turn off wb. gcSweep(work.mode) } }) _g_.m.traceback = 0 casgstatus(gp, _Gwaiting, _Grunning) if trace.enabled { traceGCDone() } // all done mp.preemptoff = "" if gcphase != _GCoff { throw("gc done but gcphase != _GCoff") } // Update GC trigger and pacing for the next cycle. // жӣҙж–°дёӢж¬ЎеҮәеҸ‘gcзҡ„еўһй•ҝжҜ” gcSetTriggerRatio(nextTriggerRatio) // Update timing memstats // жӣҙж–°з”Ёж—¶ now := nanotime() sec, nsec, _ := time_now() unixNow := sec*1e9 + int64(nsec) work.pauseNS += now - work.pauseStart work.tEnd = now atomic.Store64(&memstats.last_gc_unix, uint64(unixNow)) // must be Unix time to make sense to user atomic.Store64(&memstats.last_gc_nanotime, uint64(now)) // monotonic time for us memstats.pause_ns[memstats.numgc%uint32(len(memstats.pause_ns))] = uint64(work.pauseNS) memstats.pause_end[memstats.numgc%uint32(len(memstats.pause_end))] = uint64(unixNow) memstats.pause_total_ns += uint64(work.pauseNS) // Update work.totaltime. sweepTermCpu := int64(work.stwprocs) * (work.tMark - work.tSweepTerm) // We report idle marking time below, but omit it from the // overall utilization here since it's "free". markCpu := gcController.assistTime + gcController.dedicatedMarkTime + gcController.fractionalMarkTime markTermCpu := int64(work.stwprocs) * (work.tEnd - work.tMarkTerm) cycleCpu := sweepTermCpu + markCpu + markTermCpu work.totaltime += cycleCpu // Compute overall GC CPU utilization. totalCpu := sched.totaltime + (now-sched.procresizetime)*int64(gomaxprocs) memstats.gc_cpu_fraction = float64(work.totaltime) / float64(totalCpu) // Reset sweep state. // йҮҚзҪ®жё…жү«зҡ„зҠ¶жҖҒ sweep.nbgsweep = 0 sweep.npausesweep = 0 // еҰӮжһңжҳҜејәеҲ¶ејҖеҗҜзҡ„gcпјҢж ҮиҜҶеўһеҠ if work.userForced { memstats.numforcedgc++ } // Bump GC cycle count and wake goroutines waiting on sweep. // з»ҹи®Ўжү§иЎҢGCзҡ„次数然еҗҺе”ӨйҶ’зӯүеҫ…жё…жү«зҡ„G lock(&work.sweepWaiters.lock) memstats.numgc++ injectglist(work.sweepWaiters.head.ptr()) work.sweepWaiters.head = 0 unlock(&work.sweepWaiters.lock) // Finish the current heap profiling cycle and start a new // heap profiling cycle. We do this before starting the world // so events don't leak into the wrong cycle. mProf_NextCycle() // start the world systemstack(func() { startTheWorldWithSema(true) }) // Flush the heap profile so we can start a new cycle next GC. // This is relatively expensive, so we don't do it with the // world stopped. mProf_Flush() // Prepare workbufs for freeing by the sweeper. We do this // asynchronously because it can take non-trivial time. prepareFreeWorkbufs() // Free stack spans. This must be done between GC cycles. systemstack(freeStackSpans) // Print gctrace before dropping worldsema. As soon as we drop // worldsema another cycle could start and smash the stats // we're trying to print. if debug.gctrace > 0 { util := int(memstats.gc_cpu_fraction * 100) var sbuf [24]byte printlock() print("gc ", memstats.numgc, " @", string(itoaDiv(sbuf[:], uint64(work.tSweepTerm-runtimeInitTime)/1e6, 3)), "s ", util, "%: ") prev := work.tSweepTerm for i, ns := range []int64{work.tMark, work.tMarkTerm, work.tEnd} { if i != 0 { print("+") } print(string(fmtNSAsMS(sbuf[:], uint64(ns-prev)))) prev = ns } print(" ms clock, ") for i, ns := range []int64{sweepTermCpu, gcController.assistTime, gcController.dedicatedMarkTime + gcController.fractionalMarkTime, gcController.idleMarkTime, markTermCpu} { if i == 2 || i == 3 { // Separate mark time components with /. print("/") } else if i != 0 { print("+") } print(string(fmtNSAsMS(sbuf[:], uint64(ns)))) } print(" ms cpu, ", work.heap0>>20, "->", work.heap1>>20, "->", work.heap2>>20, " MB, ", work.heapGoal>>20, " MB goal, ", work.maxprocs, " P") if work.userForced { print(" (forced)") } print("\n") printunlock() } semrelease(&worldsema) // Careful: another GC cycle may start now. releasem(mp) mp = nil // now that gc is done, kick off finalizer thread if needed // еҰӮжһңдёҚжҳҜ并иЎҢGCпјҢеҲҷи®©еҪ“еүҚMејҖе§Ӣи°ғеәҰ if !concurrentSweep { // give the queued finalizers, if any, a chance to run Gosched() } }goSweep
жё…жү«д»»еҠЎ
func gcSweep(mode gcMode) { if gcphase != _GCoff { throw("gcSweep being done but phase is not GCoff") } lock(&mheap_.lock) // sweepgenеңЁжҜҸж¬ЎGCд№ӢеҗҺйғҪдјҡеўһй•ҝ2пјҢжҜҸж¬ЎGCд№ӢеҗҺsweepSpansзҡ„и§’иүІйғҪдјҡдә’жҚў mheap_.sweepgen += 2 mheap_.sweepdone = 0 if mheap_.sweepSpans[mheap_.sweepgen/2%2].index != 0 { // We should have drained this list during the last // sweep phase. We certainly need to start this phase // with an empty swept list. throw("non-empty swept list") } mheap_.pagesSwept = 0 unlock(&mheap_.lock) // еҰӮжһңдёҚжҳҜ并иЎҢGCпјҢжҲ–иҖ…ејәеҲ¶GC if !_ConcurrentSweep || mode == gcForceBlockMode { // Special case synchronous sweep. // Record that no proportional sweeping has to happen. lock(&mheap_.lock) mheap_.sweepPagesPerByte = 0 unlock(&mheap_.lock) // Sweep all spans eagerly. // жё…жү«жүҖжңүзҡ„span for sweepone() != ^uintptr(0) { sweep.npausesweep++ } // Free workbufs eagerly. // йҮҠж”ҫжүҖжңүзҡ„ workbufs prepareFreeWorkbufs() for freeSomeWbufs(false) { } // All "free" events for this mark/sweep cycle have // now happened, so we can make this profile cycle // available immediately. mProf_NextCycle() mProf_Flush() return } // Background sweep. lock(&sweep.lock) // е”ӨйҶ’еҗҺеҸ°жё…жү«д»»еҠЎ,д№ҹе°ұжҳҜ bgsweep еҮҪж•°пјҢжё…жү«жөҒзЁӢи·ҹдёҠйқўйқһ并иЎҢжё…жү«е·®дёҚеӨҡ if sweep.parked { sweep.parked = false ready(sweep.g, 0, true) } unlock(&sweep.lock) }sweepone
жҺҘдёӢжқҘжҲ‘们е°ұеҲҶжһҗдёҖдёӢsweepone жё…жү«зҡ„жөҒзЁӢ
func sweepone() uintptr { _g_ := getg() sweepRatio := mheap_.sweepPagesPerByte // For debugging // increment locks to ensure that the goroutine is not preempted // in the middle of sweep thus leaving the span in an inconsistent state for next GC _g_.m.locks++ // жЈҖжҹҘжҳҜеҗҰе·Із»Ҹе®ҢжҲҗдәҶжё…жү« if atomic.Load(&mheap_.sweepdone) != 0 { _g_.m.locks-- return ^uintptr(0) } // еўһеҠ жё…жү«зҡ„workerж•°йҮҸ atomic.Xadd(&mheap_.sweepers, +1) npages := ^uintptr(0) sg := mheap_.sweepgen for { // еҫӘзҺҜиҺ·еҸ–йңҖиҰҒжё…жү«зҡ„span s := mheap_.sweepSpans[1-sg/2%2].pop() if s == nil { atomic.Store(&mheap_.sweepdone, 1) break } if s.state != mSpanInUse { // This can happen if direct sweeping already // swept this span, but in that case the sweep // generation should always be up-to-date. if s.sweepgen != sg { print("runtime: bad span s.state=", s.state, " s.sweepgen=", s.sweepgen, " sweepgen=", sg, "\n") throw("non in-use span in unswept list") } continue } // sweepgen == h->sweepgen - 2, иЎЁзӨәиҝҷдёӘspanйңҖиҰҒжё…жү« // sweepgen == h->sweepgen - 1, иЎЁзӨәиҝҷдёӘspanжӯЈеңЁиў«жё…жү« // иҝҷжҳҜйҮҢзЎ®е®ҡspanзҡ„зҠ¶жҖҒеҸҠе°қиҜ•иҪ¬жҚўspanзҡ„зҠ¶жҖҒ if s.sweepgen != sg-2 || !atomic.Cas(&s.sweepgen, sg-2, sg-1) { continue } npages = s.npages // еҚ•дёӘspanзҡ„жё…жү« if !s.sweep(false) { // Span is still in-use, so this returned no // pages to the heap and the span needs to // move to the swept in-use list. npages = 0 } break } // Decrement the number of active sweepers and if this is the // last one print trace information. // еҪ“еүҚworkerжё…жү«д»»еҠЎе®ҢжҲҗпјҢжӣҙж–°sweepersзҡ„ж•°йҮҸ if atomic.Xadd(&mheap_.sweepers, -1) == 0 && atomic.Load(&mheap_.sweepdone) != 0 { if debug.gcpacertrace > 0 { print("pacer: sweep done at heap size ", memstats.heap_live>>20, "MB; allocated ", (memstats.heap_live-mheap_.sweepHeapLiveBasis)>>20, "MB during sweep; swept ", mheap_.pagesSwept, " pages at ", sweepRatio, " pages/byte\n") } } _g_.m.locks-- return npages }mspan.sweep
func (s *mspan) sweep(preserve bool) bool { // It's critical that we enter this function with preemption disabled, // GC must not start while we are in the middle of this function. _g_ := getg() if _g_.m.locks == 0 && _g_.m.mallocing == 0 && _g_ != _g_.m.g0 { throw("MSpan_Sweep: m is not locked") } sweepgen := mheap_.sweepgen // еҸӘжңүжӯЈеңЁжё…жү«дёӯзҠ¶жҖҒзҡ„spanжүҚеҸҜд»ҘжӯЈеёёжү§иЎҢ if s.state != mSpanInUse || s.sweepgen != sweepgen-1 { print("MSpan_Sweep: state=", s.state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n") throw("MSpan_Sweep: bad span state") } if trace.enabled { traceGCSweepSpan(s.npages * _PageSize) } // е…Ҳжӣҙж–°жё…жү«зҡ„pageж•° atomic.Xadd64(&mheap_.pagesSwept, int64(s.npages)) spc := s.spanclass size := s.elemsize res := false c := _g_.m.mcache freeToHeap := false // The allocBits indicate which unmarked objects don't need to be // processed since they were free at the end of the last GC cycle // and were not allocated since then. // If the allocBits index is >= s.freeindex and the bit // is not marked then the object remains unallocated // since the last GC. // This situation is analogous to being on a freelist. // Unlink & free special records for any objects we're about to free. // Two complications here: // 1. An object can have both finalizer and profile special records. // In such case we need to queue finalizer for execution, // mark the object as live and preserve the profile special. // 2. A tiny object can have several finalizers setup for different offsets. // If such object is not marked, we need to queue all finalizers at once. // Both 1 and 2 are possible at the same time. specialp := &s.specials special := *specialp // еҲӨж–ӯеңЁspecialдёӯзҡ„еҜ№иұЎжҳҜеҗҰеӯҳжҙ»пјҢжҳҜеҗҰиҮіе°‘жңүдёҖдёӘfinalizerпјҢйҮҠж”ҫжІЎжңүfinalizerзҡ„еҜ№иұЎпјҢжҠҠжңүfinalizerзҡ„еҜ№иұЎз»„жҲҗйҳҹеҲ— for special != nil { // A finalizer can be set for an inner byte of an object, find object beginning. objIndex := uintptr(special.offset) / size p := s.base() + objIndex*size mbits := s.markBitsForIndex(objIndex) if !mbits.isMarked() { // This object is not marked and has at least one special record. // Pass 1: see if it has at least one finalizer. hasFin := false endOffset := p - s.base() + size for tmp := special; tmp != nil && uintptr(tmp.offset) < endOffset; tmptmp = tmp.next { if tmp.kind == _KindSpecialFinalizer { // Stop freeing of object if it has a finalizer. mbits.setMarkedNonAtomic() hasFin = true break } } // Pass 2: queue all finalizers _or_ handle profile record. for special != nil && uintptr(special.offset) < endOffset { // Find the exact byte for which the special was setup // (as opposed to object beginning). p := s.base() + uintptr(special.offset) if special.kind == _KindSpecialFinalizer || !hasFin { // Splice out special record. y := special specialspecial = special.next *specialspecialp = special freespecial(y, unsafe.Pointer(p), size) } else { // This is profile record, but the object has finalizers (so kept alive). // Keep special record. specialp = &special.next special = *specialp } } } else { // object is still live: keep special record specialp = &special.next special = *specialp } } if debug.allocfreetrace != 0 || raceenabled || msanenabled { // Find all newly freed objects. This doesn't have to // efficient; allocfreetrace has massive overhead. mbits := s.markBitsForBase() abits := s.allocBitsForIndex(0) for i := uintptr(0); i < s.nelems; i++ { if !mbits.isMarked() && (abits.index < s.freeindex || abits.isMarked()) { x := s.base() + i*s.elemsize if debug.allocfreetrace != 0 { tracefree(unsafe.Pointer(x), size) } if raceenabled { racefree(unsafe.Pointer(x), size) } if msanenabled { msanfree(unsafe.Pointer(x), size) } } mbits.advance() abits.advance() } } // Count the number of free objects in this span. // иҺ·еҸ–йңҖиҰҒйҮҠж”ҫзҡ„allocеҜ№иұЎзҡ„жҖ»ж•° nalloc := uint16(s.countAlloc()) // еҰӮжһңsizeclassдёә0пјҢеҚҙеҲҶй…Қзҡ„жҖ»ж•°йҮҸдёә0пјҢеҲҷйҮҠж”ҫеҲ°mheap if spc.sizeclass() == 0 && nalloc == 0 { s.needzero = 1 freeToHeap = true } nfreed := s.allocCount - nalloc if nalloc > s.allocCount { print("runtime: nelems=", s.nelems, " nalloc=", nalloc, " previous allocCount=", s.allocCount, " nfreed=", nfreed, "\n") throw("sweep increased allocation count") } s.allocCount = nalloc // еҲӨж–ӯspanжҳҜеҗҰempty wasempty := s.nextFreeIndex() == s.nelems // йҮҚзҪ®freeindex s.freeindex = 0 // reset allocation index to start of span. if trace.enabled { getg().m.p.ptr().traceReclaimed += uintptr(nfreed) * s.elemsize } // gcmarkBits becomes the allocBits. // get a fresh cleared gcmarkBits in preparation for next GC // йҮҚзҪ® allocBitsдёә gcMarkBits ss.allocBits = s.gcmarkBits // йҮҚзҪ® gcMarkBits s.gcmarkBits = newMarkBits(s.nelems) // Initialize alloc bits cache. // жӣҙж–°allocCache s.refillAllocCache(0) // We need to set s.sweepgen = h.sweepgen only when all blocks are swept, // because of the potential for a concurrent free/SetFinalizer. // But we need to set it before we make the span available for allocation // (return it to heap or mcentral), because allocation code assumes that a // span is already swept if available for allocation. if freeToHeap || nfreed == 0 { // The span must be in our exclusive ownership until we update sweepgen, // check for potential races. if s.state != mSpanInUse || s.sweepgen != sweepgen-1 { print("MSpan_Sweep: state=", s.state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n") throw("MSpan_Sweep: bad span state after sweep") } // Serialization point. // At this point the mark bits are cleared and allocation ready // to go so release the span. atomic.Store(&s.sweepgen, sweepgen) } if nfreed > 0 && spc.sizeclass() != 0 { c.local_nsmallfree[spc.sizeclass()] += uintptr(nfreed) // жҠҠspanйҮҠж”ҫеҲ°mcentralдёҠ res = mheap_.central[spc].mcentral.freeSpan(s, preserve, wasempty) // MCentral_FreeSpan updates sweepgen } else if freeToHeap { // иҝҷйҮҢжҳҜеӨ§еҜ№иұЎзҡ„spanйҮҠж”ҫпјҢдёҺ117иЎҢе‘јеә” // Free large span to heap // NOTE(rsc,dvyukov): The original implementation of efence // in CL 22060046 used SysFree instead of SysFault, so that // the operating system would eventually give the memory // back to us again, so that an efence program could run // longer without running out of memory. Unfortunately, // calling SysFree here without any kind of adjustment of the // heap data structures means that when the memory does // come back to us, we have the wrong metadata for it, either in // the MSpan structures or in the garbage collection bitmap. // Using SysFault here means that the program will run out of // memory fairly quickly in efence mode, but at least it won't // have mysterious crashes due to confused memory reuse. // It should be possible to switch back to SysFree if we also // implement and then call some kind of MHeap_DeleteSpan. if debug.efence > 0 { s.limit = 0 // prevent mlookup from finding this span sysFault(unsafe.Pointer(s.base()), size) } else { // жҠҠsapnйҮҠж”ҫеҲ°mheapдёҠ mheap_.freeSpan(s, 1) } c.local_nlargefree++ c.local_largefree += size res = true } if !res { // The span has been swept and is still in-use, so put // it on the swept in-use list. // еҰӮжһңspanжңӘйҮҠж”ҫеҲ°mcentralжҲ–mheapпјҢиЎЁзӨәspanд»Қ然еӨ„дәҺin-useзҠ¶жҖҒ mheap_.sweepSpans[sweepgen/2%2].push(s) } return res }еҲ°жӯӨпјҢе…ідәҺвҖңGoиҜӯиЁҖзҡ„GCжөҒзЁӢи§ЈжһҗвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





