pythonзәҝзЁӢеҸҠеӨҡзәҝзЁӢзҡ„е®һдҫӢи®Іи§Ј
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңpythonзәҝзЁӢеҸҠеӨҡзәҝзЁӢзҡ„е®һдҫӢи®Іи§ЈвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
иҝӣзЁӢе’ҢзәҝзЁӢ
дёҖгҖҒиҝӣзЁӢ
иҝӣзЁӢжҳҜзЁӢеәҸзҡ„еҲҶй…Қиө„жәҗзҡ„жңҖе°ҸеҚ•е…ғпјӣдёҖдёӘзЁӢеәҸеҸҜд»ҘжңүеӨҡдёӘиҝӣзЁӢпјҢдҪҶеҸӘжңүдёҖдёӘдё»иҝӣзЁӢпјӣиҝӣзЁӢз”ұзЁӢеәҸгҖҒж•°жҚ®йӣҶгҖҒжҺ§еҲ¶еҷЁдёүйғЁеҲҶз»„жҲҗгҖӮ
дәҢгҖҒзәҝзЁӢ
зәҝзЁӢжҳҜзЁӢеәҸжңҖе°Ҹзҡ„жү§иЎҢеҚ•е…ғпјӣдёҖдёӘиҝӣзЁӢеҸҜд»ҘжңүеӨҡдёӘзәҝзЁӢпјҢдҪҶжҳҜеҸӘжңүдёҖдёӘдё»зәҝзЁӢпјӣзәҝзЁӢеҲҮжҚўеҲҶдёәдёӨз§Қ:дёҖз§ҚжҳҜI/OеҲҮжҚўпјҢдёҖз§ҚжҳҜж—¶й—ҙеҲҮжҚў(I/OеҲҮжҚў:дёҖж—ҰиҝҗиЎҢI/Oд»»еҠЎж—¶дҫҝиҝӣиЎҢзәҝзЁӢеҲҮжҚўпјҢCPUејҖе§Ӣжү§иЎҢе…¶д»–зәҝзЁӢ;ж—¶й—ҙеҲҮжҚў:дёҖж—ҰеҲ°дәҶдёҖе®ҡж—¶й—ҙпјҢзәҝзЁӢд№ҹиҝӣиЎҢеҲҮжҚўпјҢCPUејҖе§Ӣжү§иЎҢе…¶д»–зәҝзЁӢ)гҖӮ
дёүгҖҒжҖ»з»“
дёҖдёӘзЁӢеәҸиҮіе°‘жңүдёҖдёӘиҝӣзЁӢе’ҢдёҖдёӘзәҝзЁӢпјӣ
зЁӢеәҸзҡ„е·ҘдҪңж–№ејҸпјҡ
1.еҚ•иҝӣзЁӢеҚ•зәҝзЁӢпјӣ2.еҚ•иҝӣзЁӢеӨҡзәҝзЁӢпјӣ3.еӨҡиҝӣзЁӢеӨҡзәҝзЁӢпјӣ
иҖғиҷ‘еҲ°е®һзҺ°зҡ„еӨҚжқӮжҖ§пјҢдёҖиҲ¬жңҖеӨҡеҸӘдјҡйҮҮз”ЁеҚ•иҝӣзЁӢеӨҡзәҝзЁӢзҡ„е·ҘдҪңж–№ејҸпјӣ
еӣӣгҖҒдёәд»Җд№ҲиҰҒдҪҝз”ЁеӨҡзәҝзЁӢ
жҲ‘们еңЁе®һйҷ…з”ҹжҙ»дёӯпјҢеёҢжңӣж—ўиғҪдёҖиҫ№жөҸи§ҲзҪ‘йЎөпјҢдёҖиҫ№еҗ¬жӯҢпјҢдёҖиҫ№жү“жёёжҲҸгҖӮиҝҷж—¶пјҢеҰӮжһңеҸӘејҖдёҖдёӘиҝӣзЁӢпјҢдёәдәҶж»Ўи¶ійңҖжұӮпјҢCPUеҸӘиғҪеҝ«йҖҹеҲҮжҚўиҝӣзЁӢпјҢдҪҶжҳҜеңЁеҲҮжҚўиҝӣзЁӢж—¶дјҡйҖ жҲҗеӨ§йҮҸиө„жәҗжөӘиҙ№гҖӮжүҖд»ҘпјҢеҰӮжһңжҳҜеӨҡж ёCPUпјҢеҸҜд»ҘеңЁеҗҢж—¶иҝҗиЎҢеӨҡдёӘиҝӣзЁӢиҖҢдёҚз”ЁиҝӣиЎҢиҝӣзЁӢд№Ӣй—ҙзҡ„еҲҮжҚўгҖӮ
然иҖҢпјҢеңЁе®һйҷ…дёӯпјҢжҜ”еҰӮ:дҪ еңЁзҺ©жёёжҲҸзҡ„ж—¶еҖҷпјҢз”өи„‘йңҖиҰҒдёҖиҫ№жҳҫзӨәжёёжҲҸзҡ„еҠЁжҖҒпјҢдёҖиҫ№дҪ иҝҳеҫ—е’ҢеҗҢдјҙиҝӣиЎҢиҜӯйҹіжҲ–иҜӯиЁҖиҝӣиЎҢжІҹйҖҡгҖӮиҝҷж—¶пјҢеҰӮжһңжҳҜеҚ•зәҝзЁӢзҡ„е·ҘдҪңж–№ејҸпјҢе°ҶдјҡйҖ жҲҗеңЁж“ҚдҪңжёёжҲҸзҡ„ж—¶еҖҷе°ұж— жі•з»ҷеҗҢдјҙжІҹйҖҡпјҢеңЁе’ҢеҗҢдјҙжІҹйҖҡзҡ„ж—¶еҖҷе°ұж— жі•ж“ҚдҪңжёёжҲҸгҖӮдёәдәҶи§ЈеҶіиҜҘй—®йўҳпјҢжҲ‘们еҸҜд»ҘејҖеҗҜеӨҡзәҝзЁӢжқҘе…ұдә«жёёжҲҸиө„жәҗпјҢеҗҢж—¶иҝӣиЎҢжёёжҲҸж“ҚдҪңе’ҢжІҹйҖҡгҖӮ
дә”гҖҒе®һдҫӢ
еңәжҷҜдёҖ:并еҸ‘дҫқж¬Ўжү§иЎҢ
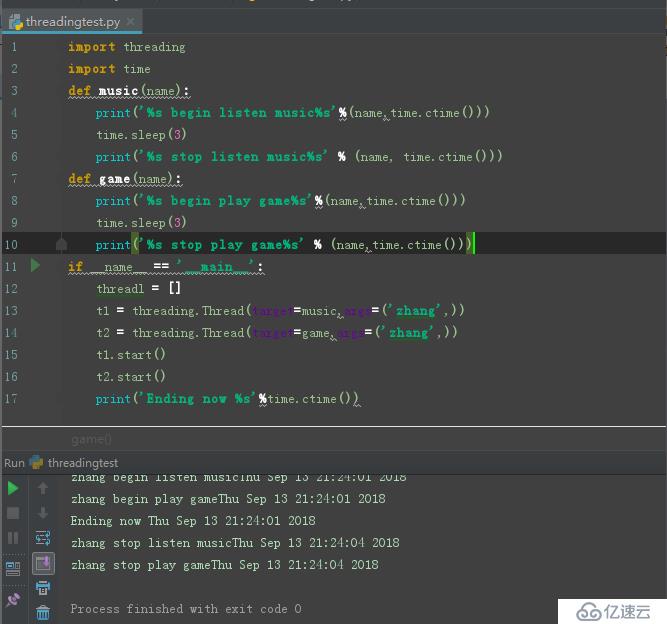
еҰӮдёҠеӣҫжүҖзӨә:жңүдёӨдёӘз®ҖеҚ•зҡ„еҮҪж•°пјҢдёҖдёӘжҳҜеҗ¬йҹід№җдёҖдёӘжҳҜжү“жёёжҲҸзҡ„еҮҪж•°гҖӮ
еҰӮжһңжҢүз…§д№ӢеүҚзҡ„еҚ•зәҝзЁӢж–№ејҸпјҢе°ҶдјҡжҳҜе…ҲиҝҗиЎҢе®Ңеҗ¬йҹід№җзҡ„еҮҪж•°еҶҚеҺ»иҝҗиЎҢжү“жёёжҲҸзҡ„еҮҪж•°пјҢжңҖеҗҺжү“еҚ°EndingгҖӮеҰӮдёӢеӣҫжүҖзӨә:
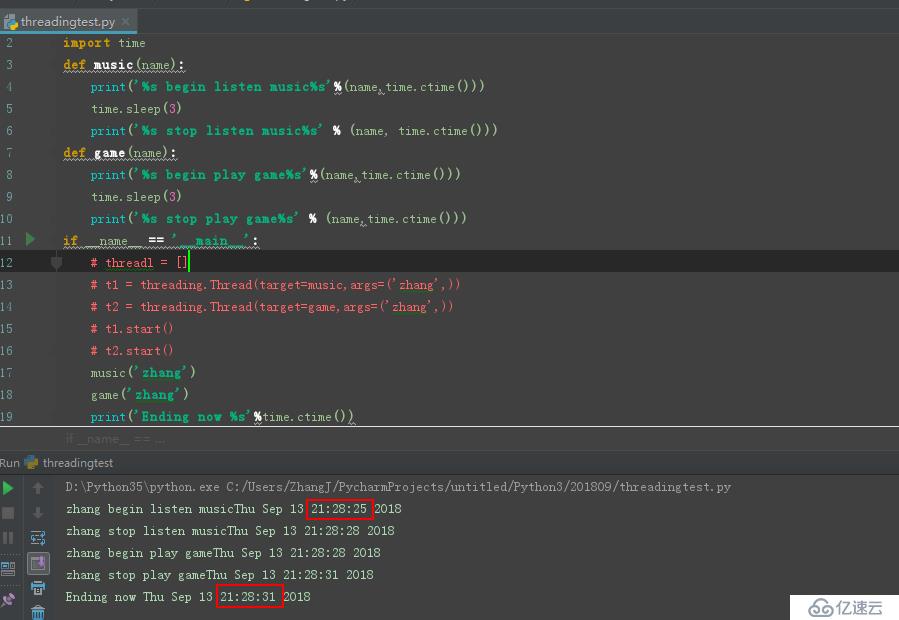
дёҖе…ұзҡ„иҝҗиЎҢж—¶й—ҙжҳҜ6з§’гҖӮ并且жҳҜеҸӘиғҪеҚ•дёҖжҢүз…§йЎәеәҸдҫқж¬ЎеҺ»жү§иЎҢгҖӮиҖҢдҪҝз”ЁеӨҡзәҝж—¶пјҢиҝҗиЎҢж—¶й—ҙжҳҜ3з§’пјҢ并且жҳҜ并иЎҢжү§иЎҢгҖӮ
иҜҘжғ…еҶөдёӢзҡ„еӨҡзәҝзЁӢиҝҗиЎҢж–№ејҸжҳҜпјҢе…ҲеҲӣе»әзәҝзЁӢ1пјҢеҶҚеҲӣе»әзәҝзЁӢ2пјҢ然еҗҺеҺ»еҗҜеҠЁзәҝзЁӢ1е’ҢзәҝзЁӢ2пјҢ并е’Ңдё»зәҝзЁӢеҗҢж—¶иҝҗиЎҢгҖӮжӯӨз§Қжғ…еҶөдёӢпјҢиӢҘеӯҗзәҝзЁӢе…ҲдәҺдё»зәҝзЁӢиҝҗиЎҢе®ҢжҜ•пјҢеҲҷеӯҗзәҝзЁӢе…Ҳе…ій—ӯеҗҺдё»зәҝзЁӢиҝҗиЎҢе®ҢжҜ•е…ій—ӯпјӣиӢҘдё»зәҝзЁӢе…ҲдәҺеӯҗзәҝзЁӢз»“жқҹпјҢеҲҷдё»зәҝзЁӢиҰҒзӯүеҫ…жүҖжңүзҡ„еӯҗзәҝзЁӢиҝҗиЎҢе®ҢжҜ•еҗҺеҶҚе…ій—ӯгҖӮ
иҜҘйғЁеҲҶд»Јз Ғеқ—:
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(3)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(3)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
# threadl = []
# t1 = threading.Thread(target=music,args=('zhang',))
# t2 = threading.Thread(target=game,args=('zhang',))
# t1.start()
# t2.start()
music('zhang')
game('zhang')
print('Ending now %s'%time.ctime())еңәжҷҜдәҢ:дё»зәҝзЁӢзӯүеҫ…жҹҗеӯҗзәҝзЁӢз»“жқҹеҗҺжүҚиғҪжү§иЎҢ(join()еҮҪж•°зҡ„з”Ёжі•)
дҫӢеҰӮ:еңЁе®һйҷ…дёӯпјҢйңҖиҰҒеӯҗзәҝзЁӢеңЁжҸ’е…Ҙж•°жҚ®пјҢдё»зәҝзЁӢйңҖиҰҒзӯүеҫ…ж•°жҚ®жҸ’е…Ҙз»“жқҹеҗҺжүҚиғҪиҝӣиЎҢжҹҘиҜўйӘҢиҜҒж“ҚдҪңпјҲжөӢиҜ•йӘҢиҜҒж•°жҚ®пјү
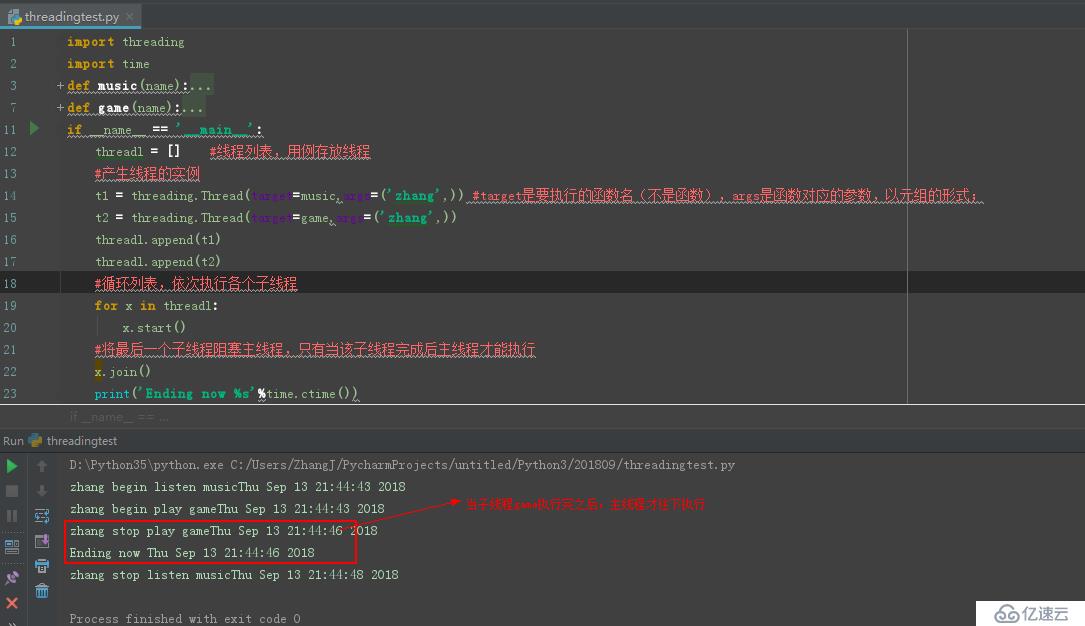
иҜҘйғЁеҲҶд»Јз Ғеқ—дёә:
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(5)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(3)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
threadl = [] #зәҝзЁӢеҲ—иЎЁпјҢз”ЁдҫӢеӯҳж”ҫзәҝзЁӢ
#дә§з”ҹзәҝзЁӢзҡ„е®һдҫӢ
t1 = threading.Thread(target=music,args=('zhang',)) #targetжҳҜиҰҒжү§иЎҢзҡ„еҮҪж•°еҗҚпјҲдёҚжҳҜеҮҪж•°пјүпјҢargsжҳҜеҮҪж•°еҜ№еә”зҡ„еҸӮж•°пјҢд»Ҙе…ғз»„зҡ„еҪўејҸпјӣ
t2 = threading.Thread(target=game,args=('zhang',))
threadl.append(t1)
threadl.append(t2)
#еҫӘзҺҜеҲ—иЎЁпјҢдҫқж¬Ўжү§иЎҢеҗ„дёӘеӯҗзәҝзЁӢ
for x in threadl:
x.start()
#е°ҶжңҖеҗҺдёҖдёӘеӯҗзәҝзЁӢйҳ»еЎһдё»зәҝзЁӢпјҢеҸӘжңүеҪ“иҜҘеӯҗзәҝзЁӢе®ҢжҲҗеҗҺдё»зәҝзЁӢжүҚиғҪеҫҖдёӢжү§иЎҢ
x.join()
print('Ending now %s'%time.ctime())иҜҘйғЁеҲҶд»Јз Ғеқ—дёә:
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(2)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(5)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
threadl = [] #зәҝзЁӢеҲ—иЎЁпјҢз”ЁдҫӢеӯҳж”ҫзәҝзЁӢ
#дә§з”ҹзәҝзЁӢзҡ„е®һдҫӢ
t1 = threading.Thread(target=music,args=('zhang',)) #targetжҳҜиҰҒжү§иЎҢзҡ„еҮҪж•°еҗҚпјҲдёҚжҳҜеҮҪж•°пјүпјҢargsжҳҜеҮҪж•°еҜ№еә”зҡ„еҸӮж•°пјҢд»Ҙе…ғз»„зҡ„еҪўејҸпјӣ
t2 = threading.Thread(target=game,args=('zhang',))
threadl.append(t1)
threadl.append(t2)
#еҫӘзҺҜеҲ—иЎЁпјҢдҫқж¬Ўжү§иЎҢеҗ„дёӘеӯҗзәҝзЁӢ
for x in threadl:
x.start()
#е°ҶеӯҗзәҝзЁӢt1йҳ»еЎһдё»зәҝзЁӢпјҢеҸӘжңүеҪ“иҜҘеӯҗзәҝзЁӢе®ҢжҲҗеҗҺдё»зәҝзЁӢжүҚиғҪеҫҖдёӢжү§иЎҢ
t1.join()
print('Ending now %s'%time.ctime())е…ӯгҖҒзәҝзЁӢе®ҲжҠӨпјҲsetDaemon()еҮҪж•°пјү
еүҚйқўдёҚз®ЎжҳҜдёҚжҳҜз”ЁеҲ°дәҶjoin()еҮҪж•°пјҢдё»зәҝзЁӢжңҖеҗҺжҖ»жҳҜиҰҒеҫ—жүҖжңүзҡ„еӯҗзәҝзЁӢжү§иЎҢе®ҢжҲҗеҗҺдё”иҮӘе·ұжү§иЎҢе®ҢжүҚиғҪе…ій—ӯпјҲд»ҘеӯҗзәҝзЁӢдёәдё»жқҘз»“жқҹдё»зәҝзЁӢпјүгҖӮдёӢйқўпјҢжҲ‘们讲иҝ°дёҖз§Қд»Ҙдё»зәҝзЁӢдёәдё»зҡ„ж–№жі•жқҘз»“жқҹдё»зәҝзЁӢгҖӮ
еӣҫ1:ж— зәҝзЁӢе®ҲжҠӨ
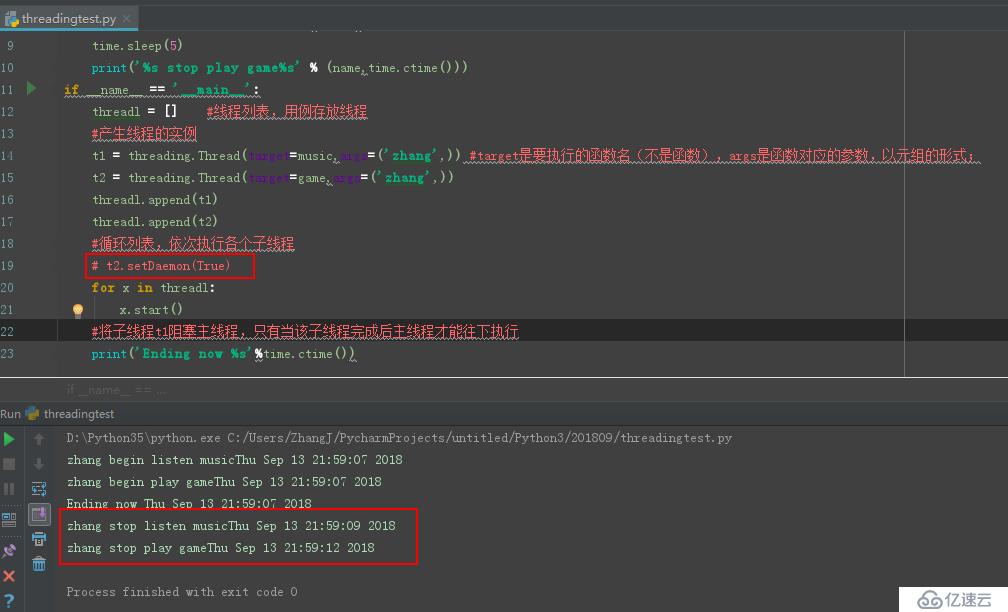
еӣҫ2:t2зәҝзЁӢе®ҲжҠӨ
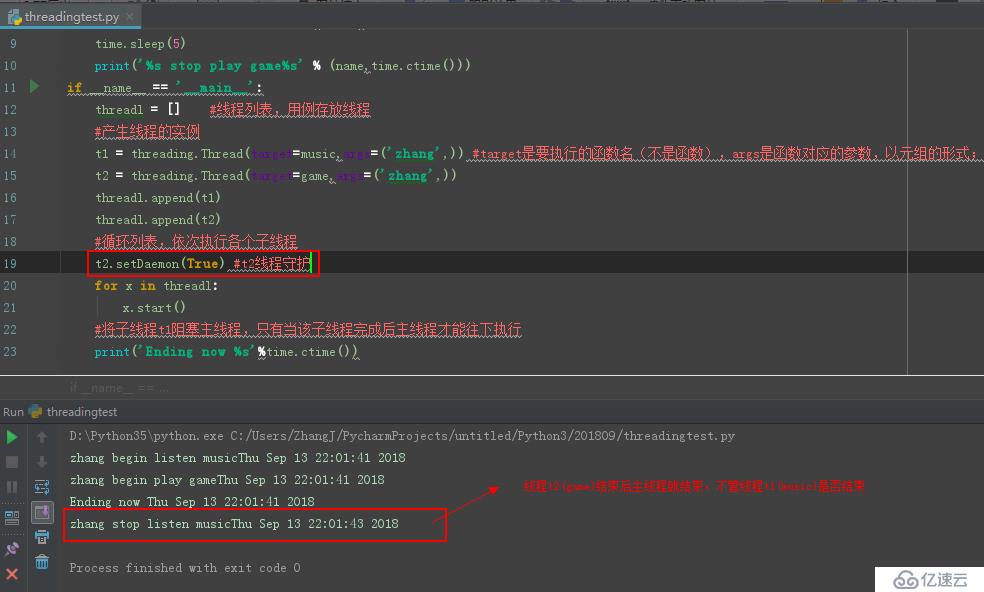
иҜҘйғЁеҲҶд»Јз Ғеқ—дёә:
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(2)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(5)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
threadl = [] #зәҝзЁӢеҲ—иЎЁпјҢз”ЁдҫӢеӯҳж”ҫзәҝзЁӢ
#дә§з”ҹзәҝзЁӢзҡ„е®һдҫӢ
t1 = threading.Thread(target=music,args=('zhang',)) #targetжҳҜиҰҒжү§иЎҢзҡ„еҮҪж•°еҗҚпјҲдёҚжҳҜеҮҪж•°пјүпјҢargsжҳҜеҮҪж•°еҜ№еә”зҡ„еҸӮж•°пјҢд»Ҙе…ғз»„зҡ„еҪўејҸпјӣ
t2 = threading.Thread(target=game,args=('zhang',))
threadl.append(t1)
threadl.append(t2)
#еҫӘзҺҜеҲ—иЎЁпјҢдҫқж¬Ўжү§иЎҢеҗ„дёӘеӯҗзәҝзЁӢ
t2.setDaemon(True) #t2зәҝзЁӢе®ҲжҠӨ
for x in threadl:
x.start()
#е°ҶеӯҗзәҝзЁӢt1йҳ»еЎһдё»зәҝзЁӢпјҢеҸӘжңүеҪ“иҜҘеӯҗзәҝзЁӢе®ҢжҲҗеҗҺдё»зәҝзЁӢжүҚиғҪеҫҖдёӢжү§иЎҢ
print('Ending now %s'%time.ctime())жүҖи°“вҖҷзәҝзЁӢе®ҲжҠӨвҖҷпјҢе°ұжҳҜдё»зәҝзЁӢдёҚз®ЎиҜҘзәҝзЁӢзҡ„жү§иЎҢжғ…еҶөпјҢеҸӘиҰҒжҳҜе…¶д»–еӯҗзәҝзЁӢз»“жқҹдё”дё»зәҝзЁӢжү§иЎҢе®ҢжҜ•пјҢдё»зәҝзЁӢйғҪдјҡе…ій—ӯгҖӮд№ҹе°ұжҳҜиҜҙ:дё»зәҝзЁӢдёҚзӯүеҫ…иҜҘе®ҲжҠӨзәҝзЁӢзҡ„жү§иЎҢе®ҢеҶҚеҺ»е…ій—ӯгҖӮ
жіЁж„Ҹ:setDaemonж–№жі•еҝ…йЎ»еңЁstartд№ӢеүҚдё”иҰҒеёҰдёҖдёӘеҝ…еЎ«зҡ„еёғе°”еһӢеҸӮж•°
дёғгҖҒиҮӘе®ҡд№үзҡ„ж–№ејҸжқҘдә§з”ҹеӨҡзәҝзЁӢ
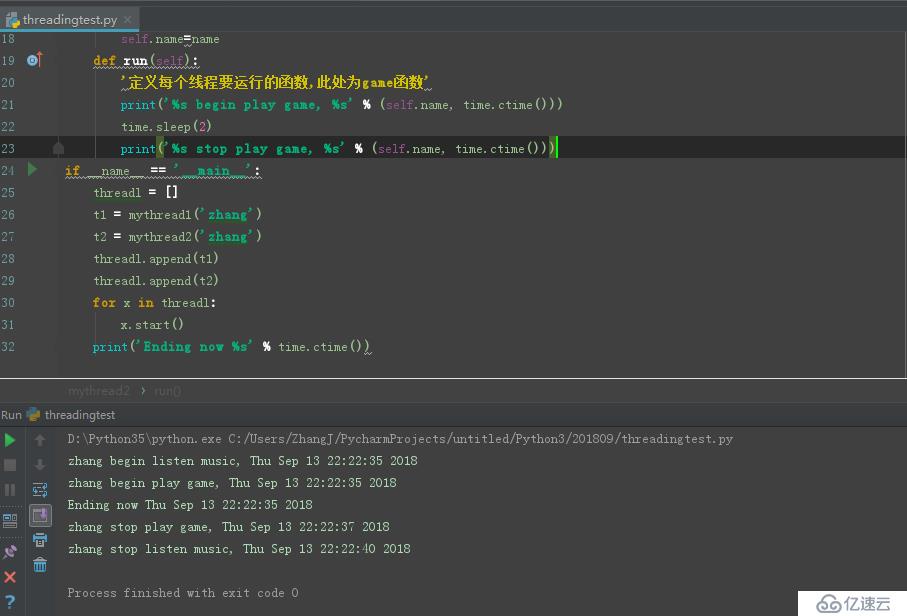
иҜҘйғЁеҲҶд»Јз Ғеқ—дёә:
import threading
import time
class mythread1(threading.Thread):
'иҮӘе®ҡд№үзәҝзЁӢ'
def __init__(self,name):
threading.Thread.__init__(self)
self.name=name
def run(self):
'е®ҡд№үжҜҸдёӘзәҝзЁӢиҰҒиҝҗиЎҢзҡ„еҮҪж•°,жӯӨеӨ„дёәmusicеҮҪж•°'
print('%s begin listen music, %s' % (self.name, time.ctime()))
time.sleep(5)
print('%s stop listen music, %s' % (self.name, time.ctime()))
class mythread2(threading.Thread):
'иҮӘе®ҡд№үзәҝзЁӢ'
def __init__(self,name):
threading.Thread.__init__(self)
self.name=name
def run(self):
'е®ҡд№үжҜҸдёӘзәҝзЁӢиҰҒиҝҗиЎҢзҡ„еҮҪж•°,жӯӨеӨ„дёәgameеҮҪж•°'
print('%s begin play game, %s' % (self.name, time.ctime()))
time.sleep(2)
print('%s stop play game, %s' % (self.name, time.ctime()))
if __name__ == '__main__':
threadl = []
t1 = mythread1('zhang')
t2 = mythread2('zhang')
threadl.append(t1)
threadl.append(t2)
for x in threadl:
x.start()
print('Ending now %s' % time.ctime())е…«гҖҒThreadingзҡ„е…¶д»–еёёз”Ёж–№жі•
getName() :иҺ·еҸ–зәҝзЁӢеҗҚз§°
setName():и®ҫзҪ®зәҝзЁӢеҗҚз§°
run():з”Ёд»ҘиЎЁзӨәзәҝзЁӢжҙ»еҠЁзҡ„ж–№жі•пјҲи§ҒдёғдёӯиҮӘе®ҡд№үзәҝзЁӢзҡ„runж–№жі•пјү
rtart():еҗҜеҠЁзәҝзЁӢжҙ»еҠЁ
is_alive():иЎЁзӨәзәҝзЁӢжҳҜеҗҰеӨ„дәҺжҙ»еҠЁзҡ„зҠ¶жҖҒпјҢз»“жһңдёәеёғе°”еҖјпјӣ
threading.active_count():иҝ”еӣһжӯЈеңЁиҝҗиЎҢзәҝзЁӢзҡ„ж•°йҮҸ
Threading.enumerate():иҝ”еӣһжӯЈеңЁиҝҗиЎҢзәҝзЁӢзҡ„еҲ—иЎЁ
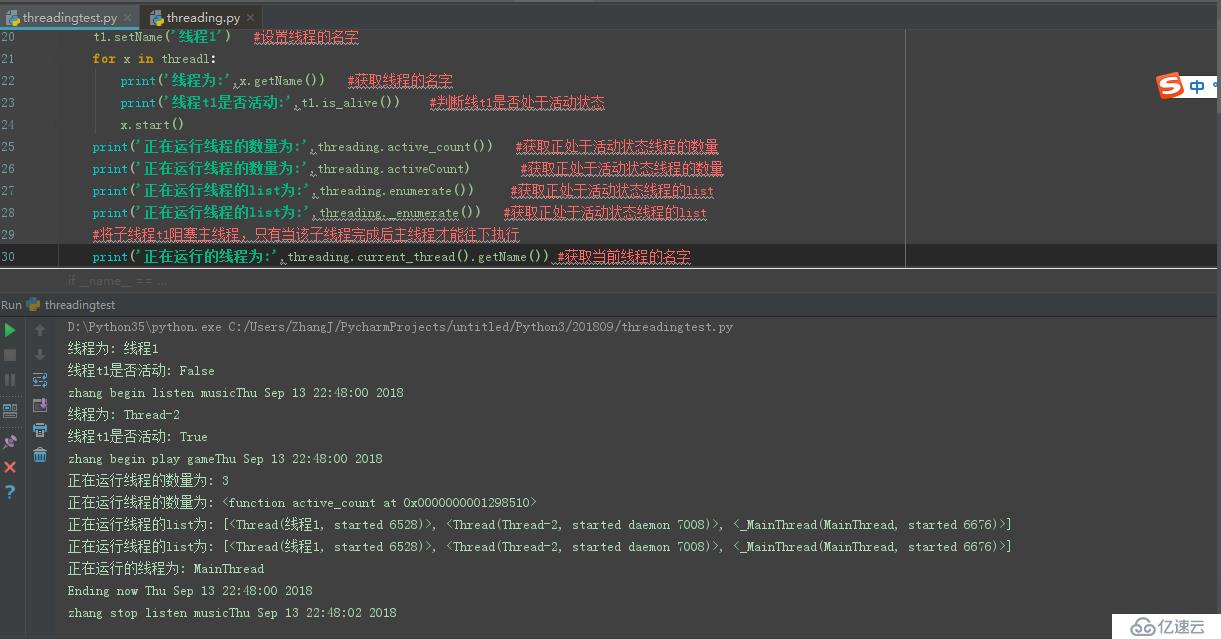
иҜҘйғЁеҲҶд»Јз Ғеқ—дёәпјӣ
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(2)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(5)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
threadl = [] #зәҝзЁӢеҲ—иЎЁпјҢз”ЁдҫӢеӯҳж”ҫзәҝзЁӢ
#дә§з”ҹзәҝзЁӢзҡ„е®һдҫӢ
t1 = threading.Thread(target=music,args=('zhang',)) #targetжҳҜиҰҒжү§иЎҢзҡ„еҮҪж•°еҗҚпјҲдёҚжҳҜеҮҪж•°пјүпјҢargsжҳҜеҮҪж•°еҜ№еә”зҡ„еҸӮж•°пјҢд»Ҙе…ғз»„зҡ„еҪўејҸпјӣ
t2 = threading.Thread(target=game,args=('zhang',))
threadl.append(t1)
threadl.append(t2)
#еҫӘзҺҜеҲ—иЎЁпјҢдҫқж¬Ўжү§иЎҢеҗ„дёӘеӯҗзәҝзЁӢ
t2.setDaemon(True) #t2зәҝзЁӢе®ҲжҠӨ,setDaemonж–№жі•еҝ…йЎ»еңЁstartд№ӢеүҚдё”иҰҒеёҰдёҖдёӘеҝ…еЎ«зҡ„еёғе°”еһӢеҸӮж•°
t1.setName('зәҝзЁӢ1') #и®ҫзҪ®зәҝзЁӢзҡ„еҗҚеӯ—
for x in threadl:
print('зәҝзЁӢдёә:',x.getName()) #иҺ·еҸ–зәҝзЁӢзҡ„еҗҚеӯ—
print('зәҝзЁӢt1жҳҜеҗҰжҙ»еҠЁ:',t1.is_alive()) #еҲӨж–ӯзәҝt1жҳҜеҗҰеӨ„дәҺжҙ»еҠЁзҠ¶жҖҒ
x.start()
print('жӯЈеңЁиҝҗиЎҢзәҝзЁӢзҡ„ж•°йҮҸдёә:',threading.active_count()) #иҺ·еҸ–жӯЈеӨ„дәҺжҙ»еҠЁзҠ¶жҖҒзәҝзЁӢзҡ„ж•°йҮҸ
print('жӯЈеңЁиҝҗиЎҢзәҝзЁӢзҡ„ж•°йҮҸдёә:',threading.activeCount) #иҺ·еҸ–жӯЈеӨ„дәҺжҙ»еҠЁзҠ¶жҖҒзәҝзЁӢзҡ„ж•°йҮҸ
print('жӯЈеңЁиҝҗиЎҢзәҝзЁӢзҡ„listдёә:',threading.enumerate()) #иҺ·еҸ–жӯЈеӨ„дәҺжҙ»еҠЁзҠ¶жҖҒзәҝзЁӢзҡ„list
print('жӯЈеңЁиҝҗиЎҢзәҝзЁӢзҡ„listдёә:',threading._enumerate()) #иҺ·еҸ–жӯЈеӨ„дәҺжҙ»еҠЁзҠ¶жҖҒзәҝзЁӢзҡ„list
#е°ҶеӯҗзәҝзЁӢt1йҳ»еЎһдё»зәҝзЁӢпјҢеҸӘжңүеҪ“иҜҘеӯҗзәҝзЁӢе®ҢжҲҗеҗҺдё»зәҝзЁӢжүҚиғҪеҫҖдёӢжү§иЎҢ
print('жӯЈеңЁиҝҗиЎҢзҡ„зәҝзЁӢдёә:',threading.current_thread().getName()) #иҺ·еҸ–еҪ“еүҚзәҝзЁӢзҡ„еҗҚеӯ—
print('Ending now %s'%time.ctime())д№қгҖҒGIL:cpythonи§ЈйҮҠеҷЁзҡ„вҖҷBUGвҖҷ
йҰ–е…ҲйңҖиҰҒжҳҺзЎ®зҡ„дёҖзӮ№жҳҜGIL并дёҚжҳҜPythonзҡ„зү№жҖ§пјҢе®ғжҳҜеңЁе®һзҺ°Pythonи§ЈжһҗеҷЁ(CPython)ж—¶жүҖеј•е…Ҙзҡ„дёҖдёӘжҰӮеҝөгҖӮеңЁе…¶дёӯзҡ„JPythonе°ұжІЎжңүGILгҖӮ然иҖҢеӣ дёәCPythonжҳҜеӨ§йғЁеҲҶзҺҜеўғдёӢй»ҳи®Өзҡ„Pythonжү§иЎҢзҺҜеўғгҖӮжүҖд»ҘеңЁеҫҲеӨҡдәәзҡ„жҰӮеҝөйҮҢCPythonе°ұжҳҜPythonпјҢд№ҹе°ұжғіеҪ“然зҡ„жҠҠGILеҪ’з»“дёәPythonиҜӯиЁҖзҡ„зјәйҷ·гҖӮжүҖд»ҘиҝҷйҮҢиҰҒе…ҲжҳҺзЎ®дёҖзӮ№пјҡGIL并дёҚжҳҜPythonзҡ„зү№жҖ§пјҢPythonе®Ңе…ЁеҸҜд»ҘдёҚдҫқиө–дәҺGILгҖӮ
GIL:global interpreter lock,е…ЁеұҖи§ЈйҮҠеҷЁй”ҒгҖӮеҺҹж–Ү:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPythonвҖҷs memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
д№ҹе°ұжҳҜиҜҙ:ж— и®әжңүеӨҡе°‘дёӘCPUпјҢејҖеҗҜеӨҡе°‘зәҝзЁӢпјҢжҜҸж¬ЎеҸӘиғҪжү§иЎҢдёҖдёӘзәҝзЁӢгҖӮ
еҹәдәҺжӯӨи®ҫи®ЎеҺҹзҗҶдёҠпјҢжҲ‘们дјҡи§үеҫ—pythonзҡ„еӨҡзәҝзЁӢе…¶е®һе®Ңе…ЁжІЎжңүз”ЁпјҢеҰӮдёӢеӣҫдёҚејҖеӨҡзәҝзЁӢжү§иЎҢзҡ„ж—¶й—ҙ:
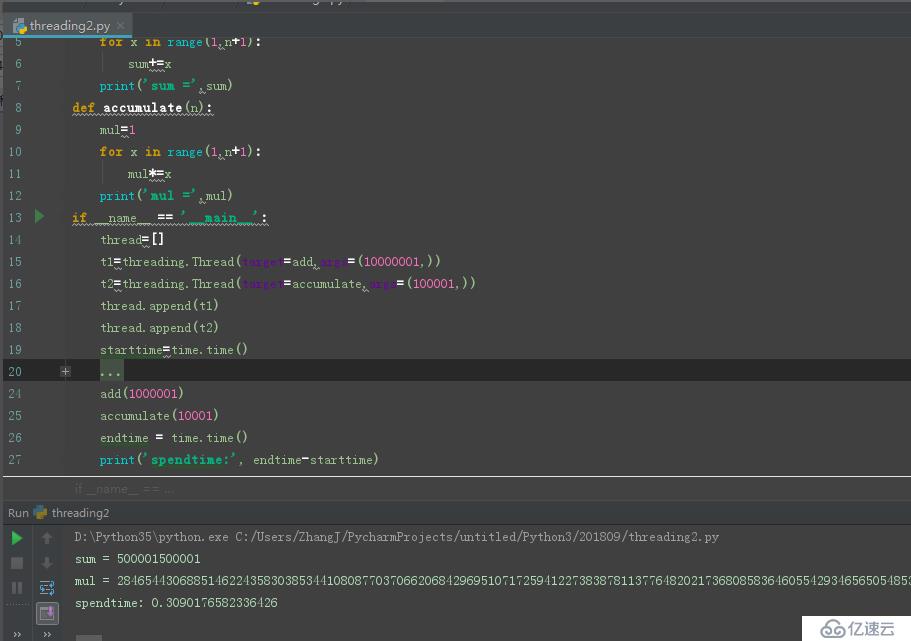
еҰӮдёӢеӣҫејҖеҗҜеӨҡзәҝзЁӢжү§иЎҢзҡ„ж—¶й—ҙ:
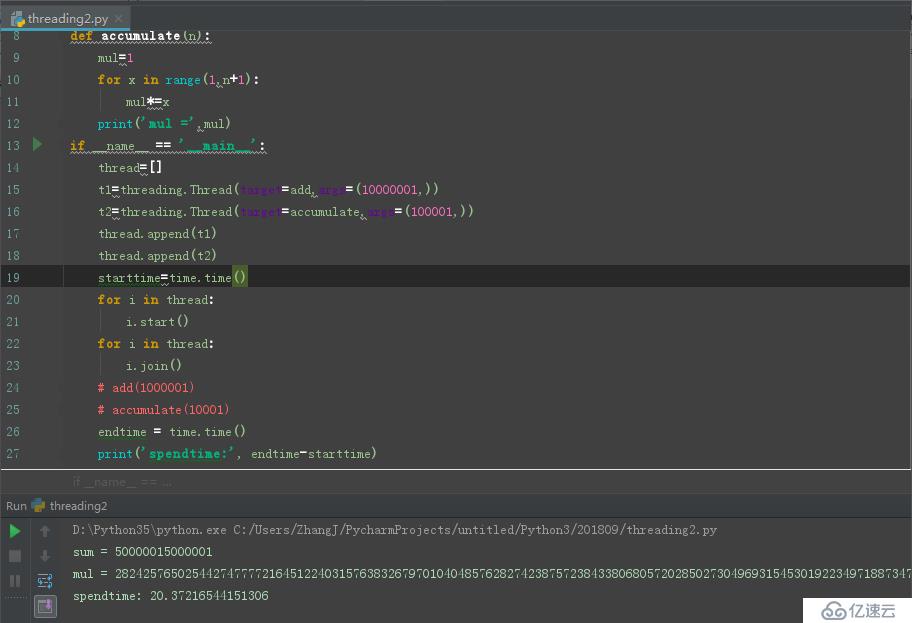
еҘҪеҗ§пјҢеүҚиҖ…жҳҜ0.3з§’пјҢеҗҺиҖ…жҳҜ20з§’пјҢиҝҷдёӘз»“жһңжҳҜдёҚжҳҜж— жі•жҺҘеҸ—...........
иҜҘйғЁеҲҶд»Јз Ғеқ—:
import threading
import time
def add(n):
sum=0
for x in range(1,n+1):
sum+=x
print('sum =',sum)
def accumulate(n):
mul=1
for x in range(1,n+1):
mul*=x
print('mul =',mul)
if __name__ == '__main__':
thread=[]
t1=threading.Thread(target=add,args=(10000001,))
t2=threading.Thread(target=accumulate,args=(100001,))
thread.append(t1)
thread.append(t2)
starttime=time.time()
for i in thread:
i.start()
for i in thread:
i.join()
# add(1000001)
# accumulate(10001)
endtime = time.time()
print('spendtime:', endtime-starttime)GILеҺҹзҗҶ:

еүҚиҖ…жҳҜеҚ•зәҝзЁӢпјҢд»»еҠЎдёІиЎҢпјҢжү§иЎҢе®ҢaddеҮҪж•°еҗҺеҶҚжү§иЎҢaccumulateеҮҪж•°пјҢдёҚз”ЁиҝӣиЎҢзәҝзЁӢй—ҙзҡ„еҲҮжҚўгҖӮиҖҢеңЁеҗҺиҖ…дёӯпјҢзәҝзЁӢaddе’ҢзәҝзЁӢaccumulateеҸҠдё»зәҝзЁӢдёүиҖ…йңҖиҰҒдёҚж–ӯзҡ„еҲҮжҚўжқҘжү§иЎҢпјҢе…¶дёӯеҲҮжҚўзәҝзЁӢйңҖиҰҒж¶ҲиҖ—еӨ§йҮҸж—¶й—ҙе’Ңиө„жәҗгҖӮжүҖд»ҘпјҢжҲ‘们зңӢеҲ°жҳҜеҗҺиҖ…зҡ„ж—¶й—ҙжҳҜеүҚиҖ…зҡ„7еҖҚе·ҰеҸігҖӮ
дҪҶжҳҜпјҢжҲ‘们еңЁдёҠйқўзҡ„musicе’ҢgameзәҝзЁӢдёӯеҚҙеҸ‘зҺ°еӨҡзәҝзЁӢиғҪеӨ§еӨ§зҡ„иҠӮзңҒж—¶й—ҙпјҢжҸҗй«ҳж•ҲзҺҮпјҢйӮЈеҸҲжҳҜдёәд»Җд№Ҳе‘ўпјҹе…¶е®һпјҢдё»иҰҒиҰҒзңӢд»»еҠЎзҡ„зұ»еһӢпјҢжҲ‘们жҠҠд»»еҠЎеҲҶдёәI/OеҜҶйӣҶеһӢе’Ңи®Ўз®—еҜҶйӣҶеһӢпјҢиҖҢеӨҡзәҝзЁӢеңЁеҲҮжҚўдёӯеҸҲеҲҶдёәI/OеҲҮжҚўе’Ңж—¶й—ҙеҲҮжҚўгҖӮеҰӮжһңд»»еҠЎеұһдәҺжҳҜI/OеҜҶйӣҶеһӢпјҢиӢҘдёҚйҮҮз”ЁеӨҡзәҝзЁӢпјҢжҲ‘们еңЁиҝӣиЎҢI/Oж“ҚдҪңж—¶пјҢеҠҝеҝ…иҰҒзӯүеҫ…еүҚйқўдёҖдёӘI/Oд»»еҠЎе®ҢжҲҗеҗҺйқўзҡ„I/Oд»»еҠЎжүҚиғҪиҝӣиЎҢпјҢеңЁиҝҷдёӘзӯүеҫ…зҡ„иҝҮзЁӢдёӯпјҢCPUеӨ„дәҺзӯүеҫ…зҠ¶жҖҒпјҢиҝҷж—¶еҰӮжһңйҮҮз”ЁеӨҡзәҝзЁӢзҡ„иҜқпјҢеҲҡеҘҪеҸҜд»ҘеҲҮжҚўеҲ°иҝӣиЎҢеҸҰдёҖдёӘI/Oд»»еҠЎгҖӮиҝҷж ·е°ұеҲҡеҘҪеҸҜд»Ҙе……еҲҶеҲ©з”ЁCPUйҒҝе…ҚCPUеӨ„дәҺй—ІзҪ®зҠ¶жҖҒпјҢжҸҗй«ҳж•ҲзҺҮгҖӮдҪҶжҳҜеҰӮжһңеӨҡзәҝзЁӢд»»еҠЎйғҪжҳҜи®Ўз®—еһӢпјҢCPUдјҡдёҖзӣҙеңЁиҝӣиЎҢе·ҘдҪңпјҢзӣҙеҲ°дёҖе®ҡзҡ„ж—¶й—ҙеҗҺйҮҮеҸ–еӨҡзәҝзЁӢж—¶й—ҙеҲҮжҚўзҡ„ж–№ејҸиҝӣиЎҢеҲҮжҚўзәҝзЁӢпјҢжӯӨж—¶CPUдёҖзӣҙеӨ„дәҺе·ҘдҪңзҠ¶жҖҒпјҢжӯӨз§Қжғ…еҶөдёӢ并дёҚиғҪжҸҗй«ҳжҖ§иғҪпјҢзӣёеҸҚеңЁеҲҮжҚўеӨҡзәҝзЁӢд»»еҠЎж—¶пјҢеҸҜиғҪиҝҳдјҡйҖ жҲҗж—¶й—ҙе’Ңиө„жәҗзҡ„жөӘиҙ№пјҢеҜјиҮҙж•ҲиғҪдёӢйҷҚгҖӮиҝҷе°ұжҳҜйҖ жҲҗдёҠйқўдёӨз§ҚеӨҡзәҝзЁӢз»“жһңдёҚиғҪзҡ„и§ЈйҮҠгҖӮ
з»“и®ә:I/OеҜҶйӣҶеһӢд»»еҠЎпјҢе»әи®®йҮҮеҸ–еӨҡзәҝзЁӢпјҢиҝҳеҸҜд»ҘйҮҮз”ЁеӨҡиҝӣзЁӢ+еҚҸзЁӢзҡ„ж–№ејҸ(дҫӢеҰӮ:зҲ¬иҷ«еӨҡйҮҮз”ЁеӨҡзәҝзЁӢеӨ„зҗҶзҲ¬еҸ–зҡ„ж•°жҚ®)пјӣеҜ№дәҺи®Ўз®—еҜҶйӣҶеһӢд»»еҠЎпјҢpythonжӯӨж—¶е°ұдёҚйҖӮз”ЁдәҶгҖӮ
еҚҒгҖҒзәҝзЁӢеҗҢжӯҘй”Ғ
1.дёәд»Җд№ҲйңҖиҰҒеҗҢжӯҘй”Ғ
зңӢдёӢйқўдҫӢеӯҗпјҢжҲ‘们иҮӘе®ҡд№үдёҖдёӘеҮҸ1зҡ„еҮҪж•°пјҢеҲқе§ӢиөӢеҖј100пјҢдҪҝз”ЁеӨҡзәҝзЁӢпјҢејҖеҗҜ100дёӘзәҝзЁӢпјҢйӮЈд№Ҳжңҹжңӣзҡ„з»“жһңжҳҜжңҖз»Ҳз»“жһңдёә0пјҢзңӢдёӢеӣҫ:
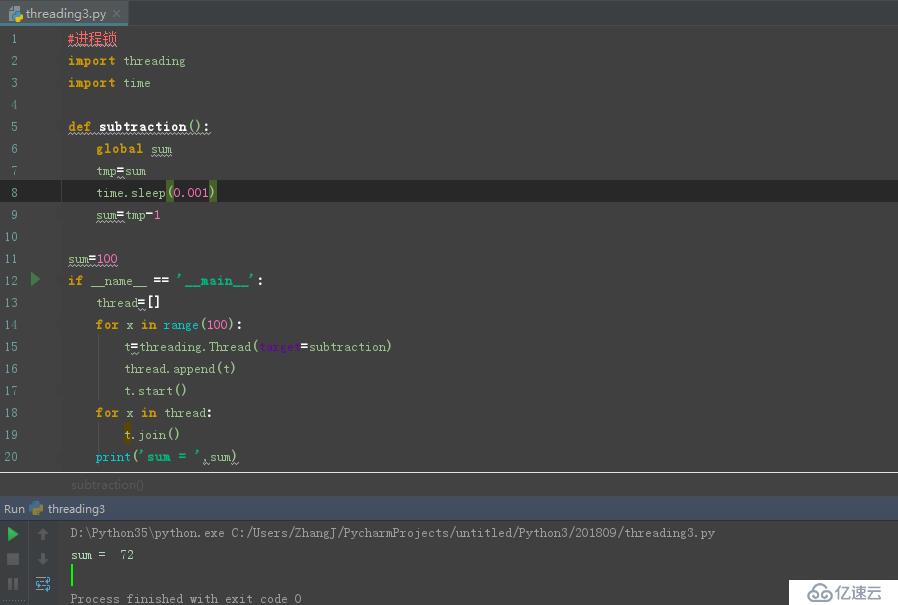
иҜҘйғЁеҲҶд»Јз Ғеқ—дёә:
#иҝӣзЁӢй”Ғ
import threading
import time
def subtraction():
global sum
tmp=sum
time.sleep(0.001)
sum=tmp-1
sum=100
if __name__ == '__main__':
thread=[]
for x in range(100):
t=threading.Thread(target=subtraction)
thread.append(t)
t.start()
for x in thread:
t.join()
print('sum = ',sum)дёҠйқўзҺ°иұЎдә§з”ҹзҡ„еҺҹеӣ дёә:жҲ‘们еңЁејҖеҗҜ100дёӘзәҝзЁӢзҡ„ж—¶еҖҷпјҢеҪ“100дёӘзәҝзЁӢеңЁиҝӣиЎҢsubtractionеҮҪж•°ж“ҚдҪңж—¶пјҢйҰ–е…ҲиҰҒиҺ·еҸ–еҗ„иҮӘзҡ„sum(жјҸжҙһ:е…ұеҗҢзҡ„ж•°жҚ®дёҚиғҪе…ұдә«еҗҢж—¶иў«еӨҡзәҝзЁӢж“ҚдҪң)е’ҢtmpпјҢдҪҶжҳҜжӯӨж—¶еӨҡзәҝзЁӢдјҡжҢүз…§ж—¶й—ҙ规еҲҷжқҘиҝӣиЎҢеҲҮжҚўпјҢеҰӮжһңеҪ“еүҚйқўжҹҗдәӣзәҝзЁӢеңЁеӨ„зҗҶsumж—¶жңӘз»“жқҹпјҢеҗҺйқўзҡ„иҝӣзЁӢе·Із»ҸејҖе§ӢдәҶ(дёҠйқўдҫӢеӯҗдёӯзҡ„д»Јз ҒеўһеҠ дәҶдј‘зң ж—¶й—ҙжқҘдҪ“зҺ°иҜҘж•Ҳжһң)пјҢжӯӨж—¶жӢҝеҲ°зҡ„sumе°ұдёҚеҶҚжҳҜsum-1зҡ„жңҹжңӣз»“жһңдәҶпјҢиҖҢжҳҜжӢҝеҲ°дәҶsumзҡ„еҖјгҖӮиҝҷж ·е°ұдјҡеҜјиҮҙпјҢжӯӨж¬Ўзҡ„зәҝзЁӢиҝӣиЎҢиҮӘеҮҸ1зҡ„ж“ҚдҪңеӨұж•ҲдәҶгҖӮSo,е°ұдјҡеҜјиҮҙдёҠеӣҫзҡ„зҺ°иұЎдәҶпјҢдёӢйқўе°ұи®Іиҝ°иҜҘеҰӮдҪ•йҖҡиҝҮеҠ еҗҢжӯҘй”ҒжқҘи§ЈеҶіиҜҘй—®йўҳгҖӮ
2.еўһеҠ еҗҢжӯҘй”ҒиҝӣиЎҢеӨ„зҗҶе…ұеҗҢж•°жҚ®
еҰӮдёӢеӣҫ:
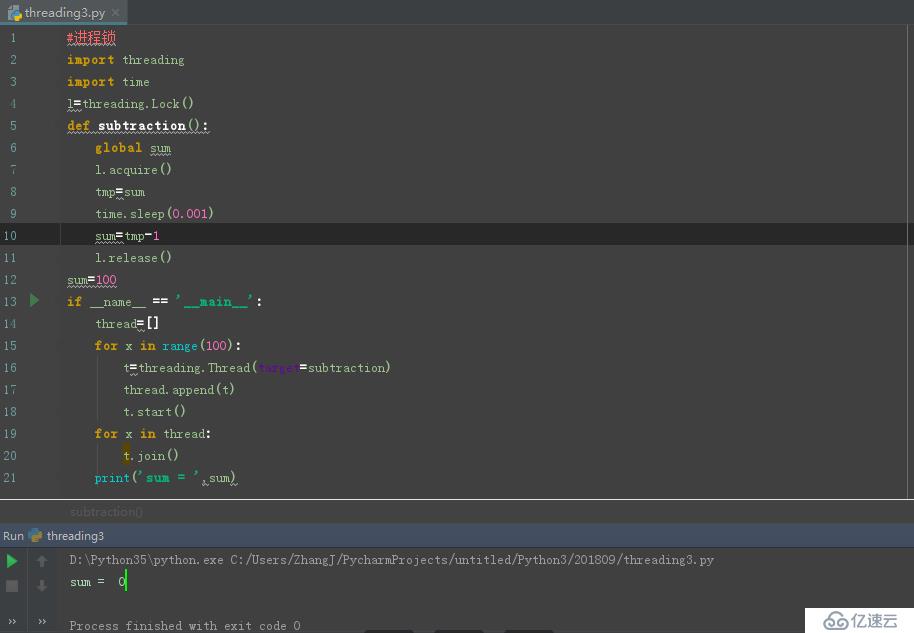
иҜҘйғЁеҲҶд»Јз Ғеқ—еҰӮдёӢпјҡ
#иҝӣзЁӢй”Ғ
import threading
import time
l=threading.Lock()
def subtraction():
global sum
l.acquire()
tmp=sum
time.sleep(0.001)
sum=tmp-1
l.release()
sum=100
if __name__ == '__main__':
thread=[]
for x in range(100):
t=threading.Thread(target=subtraction)
thread.append(t)
t.start()
for x in thread:
t.join()
print('sum = ',sum)йҡҫзӮ№:2.1дҪ•еӨ„еҠ й”ҒпјҹдҪ•еӨ„йҮҠж”ҫй”Ғпјҹз®ҖеҚ•зҡ„еҺҹеҲҷе°ұжҳҜ:йңҖиҰҒеңЁеј•иө·еӨҡзәҝзЁӢзӣёдә’зҹӣзӣҫзҡ„е…ұеҗҢж•°жҚ®йғЁеҲҶжһ·й”ҒпјҢдҫӢеҰӮдёҠйқўдҫӢеӯҗдёӯзҡ„sumеӨҡдёӘзәҝзЁӢйғҪиҰҒдҪҝз”Ёдё”еҗҺйқўзәҝзЁӢжңҹжңӣдҪҝз”Ёзҡ„еә”иҜҘжҳҜеүҚйқўзәҝзЁӢеҮҸ1зҡ„з»“жһңпјӣиҝҳжңүеңЁж•°жҚ®еә“ж“ҚдҪңж—¶пјҢдҪҝз”ЁиҮӘеўһдё»й”®ж—¶пјҢд№ҹиҰҒеҜ№жҸ’е…Ҙзҡ„ж•°жҚ®иҝӣиЎҢеҠ й”ҒпјҢеҗҰеҲҷе°ҶеҸҜиғҪдјҡеҜјиҮҙдё»й”®йҮҚеӨҚгҖӮ
2.2еҠ й”Ғзҡ„йғЁеҲҶд»Јз ҒзӣёеҪ“дәҺжҳҜеҚ•зәҝзЁӢдёІиЎҢиҝҗиЎҢдәҶгҖӮ
3.иҝӣзЁӢжӯ»й”Ғ
еңЁзәҝзЁӢй—ҙе…ұдә«еӨҡдёӘиө„жәҗзҡ„ж—¶еҖҷпјҢеҰӮжһңеҲҶеҲ«еҚ жңүдёҖйғЁеҲҶиө„жәҗ并且еҗҢж—¶еңЁзӯүеҫ…еҜ№ж–№зҡ„иө„жәҗпјҢе°ұдјҡйҖ жҲҗжӯ»й”ҒгҖӮдҫӢеҰӮпјӣж•°жҚ®еә“ж“ҚдҪңж—¶AзәҝзЁӢйңҖиҰҒBзәҝзЁӢзҡ„з»“жһңиҝӣиЎҢж“ҚдҪңпјҢBзәҝзЁӢзҡ„йңҖиҰҒAзәҝзЁӢзҡ„з»“жһңиҝӣиЎҢж“ҚдҪңпјҢеҪ“A,BзәҝзЁӢеҗҢж—¶еңЁиҝӣиЎҢж“ҚдҪңиҝҳжІЎжңүз»“жһңеҮәжқҘж—¶пјҢжӯӨж—¶A,BзәҝзЁӢе°ҶдјҡдёҖзӣҙеӨ„дәҺзӯүеҫ…еҜ№ж–№з»“жқҹзҡ„зҠ¶жҖҒгҖӮ
зҺ°иұЎеҰӮдёӢеӣҫпјҡ
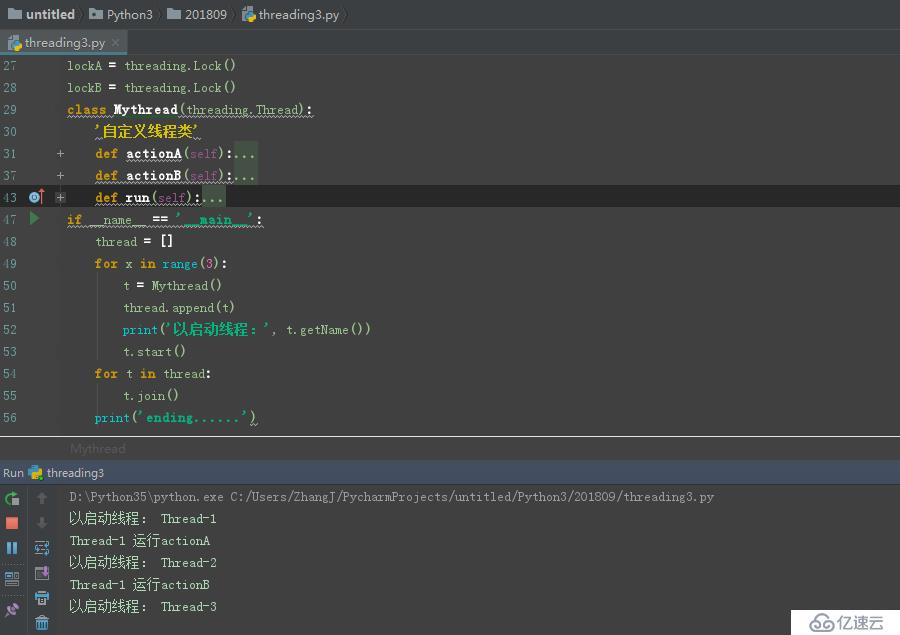
иҜҘйғЁеҲҶд»Јз Ғеқ—еҰӮдёӢ:
#жӯ»й”Ғ
import threading
lockA = threading.Lock()
lockB = threading.Lock()
class Mythread(threading.Thread):
'иҮӘе®ҡд№үзәҝзЁӢзұ»'
def actionA(self):
'actionAеҮҪж•°дёӯиҝҗиЎҢactionBеҮҪж•°пјҢиҝҗиЎҢactionBеҮҪж•°еүҚеҠ й”ҒпјҢиҝҗиЎҢactionBеҮҪж•°з»“жқҹеҗҺйҮҠж”ҫй”Ғ'
lockA.acquire()
print(self.name,'иҝҗиЎҢactionA')
self.actionB()
lockA.release()
def actionB(self):
'actionBеҮҪж•°дёӯиҝҗиЎҢactionAеҮҪж•°пјҢиҝҗиЎҢactionAеҮҪж•°еүҚеҠ й”ҒпјҢиҝҗиЎҢactionAеҮҪж•°з»“жқҹеҗҺйҮҠж”ҫй”Ғ'
lockB.acquire()
print(self.name,'иҝҗиЎҢactionB')
self.actionA()
lockB.release()
def run(self):
'иҝҗиЎҢеҮҪж•°'
self.actionA()
self.actionB()
if __name__ == '__main__':
thread = []
for x in range(3):
t = Mythread()
thread.append(t)
print('д»ҘеҗҜеҠЁзәҝзЁӢпјҡ', t.getName())
t.start()
for t in thread:
t.join()
print('ending......')еҚҒдёҖгҖҒеӨҡзәҝзЁӢеҲ©еҷЁ-йҳҹеҲ—(squeue)
еңәжҷҜ:е®ҡд№үдёҖдёӘеҮҪж•°з”ЁдҫӢеҲ йҷӨеҲ—иЎЁдёӯжңҖеҗҺдёҖдёӘе…ғзҙ пјҢдҪҝз”ЁеӨҡзәҝзЁӢжқҘеҲ йҷӨдёҖдёӘеҲ—иЎЁдёӯзҡ„ж•°жҚ®пјҢзҺ°иұЎеҰӮдёӢеӣҫжүҖзӨә:
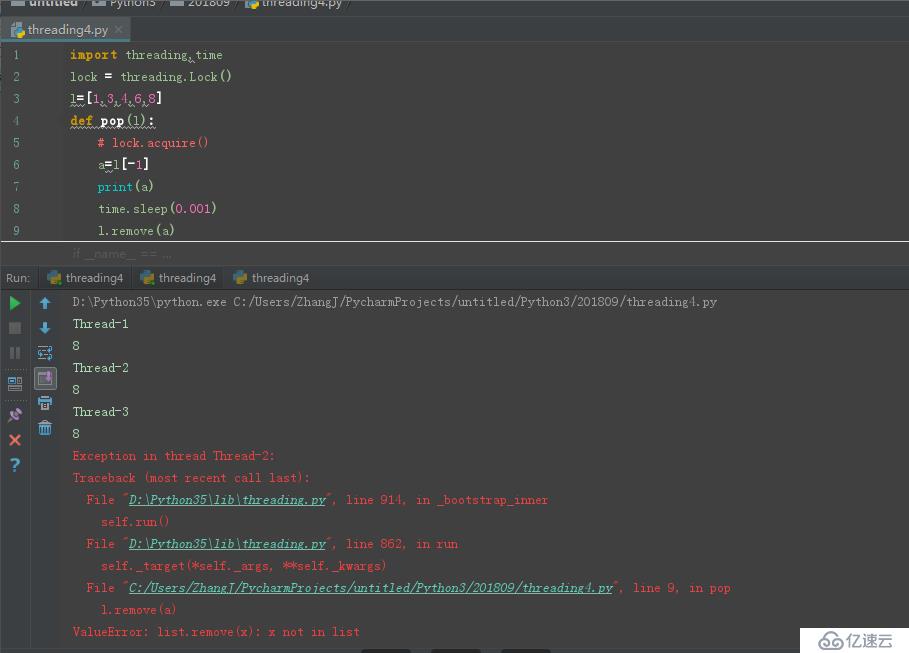
иҜҘйғЁеҲҶзҡ„д»Јз Ғеқ—еҰӮдёӢ:
import threading,time
l=[1,3,4,6,8]
def pop(l):
a=l[-1]
print(a)
time.sleep(0.001)
l.remove(a)
if __name__ == '__main__':
th=[]
for x in range(3):
t = threading.Thread(target=pop, args=(l,))
th.append(t)
print(t.getName())
t.start()
for x in th:
x.join()
# pop(l)
print('l = ',l) жӯӨеӨ„з”ұдәҺеӨҡзәҝзЁӢеңЁж“ҚдҪңж—¶еҸҜиғҪжӢҝеҲ°зӣёеҗҢзҡ„жңҖеҗҺдёҖдёӘе…ғзҙ еҖјпјҢжӯӨж—¶иӢҘеүҚиҖ…зҡ„зәҝзЁӢе·Із»ҸеҲ йҷӨдәҶиҜҘе…ғзҙ пјҢеҲҷеҗҺйқўзәҝзЁӢзҡ„еҮҪж•°еҲҷж— жі•еҲ йҷӨиҜҘе…ғзҙ (removeжҳҜжҢүе…ғзҙ жқҘиҝӣиЎҢеҲ йҷӨзҡ„)гҖӮдёәдәҶи§ЈеҶіжӯӨж¬Ўе…ұдә«ж•°жҚ®еҜјиҮҙзҡ„еӨҡзәҝзЁӢй—®йўҳпјҢжҲ‘们еҸҜд»ҘеҲ©з”ЁеүҚйқўзҡ„иҝӣзЁӢеҗҢжӯҘй”ҒжқҘеӨ„зҗҶпјҢжҲ‘们еҸҜд»ҘеңЁиҺ·еҸ–е’ҢеҲ йҷӨж•°жҚ®зҡ„ж—¶еҖҷеҠ й”ҒпјҢд»Јз ҒеҰӮдёӢ:
import threading,time
lock = threading.Lock()
l=[1,3,4,6,8]
def pop(l):
# lock.acquire()
a=l[-1]
print(a)
time.sleep(0.001)
l.remove(a)
# lock.release()
if __name__ == '__main__':
th=[]
for x in range(3):
t = threading.Thread(target=pop, args=(l,))
th.append(t)
print(t.getName())
t.start()
for x in th:
x.join()
# pop(l)
print('l = ',l) еңЁиҜҘйғЁеҲҶпјҢжҲ‘们引е…Ҙж–°зҡ„жЁЎеқ—queue(зәҝзЁӢйҳҹеҲ—)жқҘи§ЈеҶіиҜҘй—®йўҳпјҢеҰӮдёӢеӣҫжүҖзӨә:

иҜҘйғЁеҲҶд»Јз Ғеқ—еҰӮдёӢ:
import threading,time
import queue #зәҝзЁӢйҳҹеҲ—
l=[1,3,4,6,8]
def pop(l):
a=l[-1]
print('a = ',a)
time.sleep(0.001)
l.remove(a)
if __name__ == '__main__':
q = queue.Queue()
for x in range(3):
t = threading.Thread(target=pop, args=(l,))
q.put(t)
while not q.empty():
data = q.get()
print('еҪ“еүҚжү§иЎҢзҡ„зәҝзЁӢ:', data.getName())
data.run()
print('l = ',l)QueueзәҝзЁӢйҳҹеҲ—еӯҳж”ҫж•°жҚ®зҡ„дёүз§Қж–№ејҸ:
1.1е…Ҳиҝӣе…ҲеҮә(FIFO)
q=queue.Queue()
q.put(maxsize)
1.2е…ҲиҝӣеҗҺеҮә(LIFO)
q=queue.LifoQueue()
q.put(maxsize)
1.3жҢүз…§дјҳе…Ҳзә§иҝӣеҮә
q = queue.PriorityQueue()
q.put(list) #д»Ҙй•ҝеәҰдёә2зҡ„listеӯҳж•°жҚ®,第дёҖдёӘе…ғзҙ иЎЁзӨәдјҳе…Ҳзә§пјҢ第дәҢдёӘе…ғзҙ иЎЁзӨәеӯҳж”ҫзҡ„еҜ№еә”зҡ„еҖј
д»Јз Ғеқ—еҰӮдёӢ:
import queue #зәҝзЁӢйҳҹеҲ—
num=5
#numз”ЁдҫӢйҷҗеҲ¶йҳҹеҲ—дёӯжҸ’е…Ҙе…ғзҙ зҡ„дёӘж•°пјҢеҸҜдёҚеЎ«
q1 = queue.Queue(num) #дёүз§ҚеӯҳеҸ–ж•°жҚ®зҡ„йЎәеәҸпјҢ1.е…Ҳиҝӣе…ҲеҮә(FIFO,дёҚжҢҮжҳҺж–№ејҸеҲҷй»ҳи®ӨиҜҘж–№ејҸ)пјӣ2.е…ҲиҝӣеҗҺеҮә(LIFO);3.жҢүдјҳе…Ҳзә§иҝӣеҮә()
q1.put(123)
q1.put('you')
q1.put({'name':'zhangzhou'})
q2 = queue.LifoQueue(num)
q2.put(123)
q2.put('you')
q2.put({'name':'zhangzhou'})
q3 = queue.PriorityQueue()
q3.put([2,123])
q3.put([3,'you'])
q3.put([1,{'name':'zhangzhou'}])
if __name__ == '__main__':
while not q1.empty():
data = q1.get()
print('------------',data,'------------')
while not q2.empty():
data = q2.get()
print('------------',data,'------------')
while not q3.empty():
data = q3.get()
print('------Priority=',data[0],'value=',data[1],'-------')вҖңpythonзәҝзЁӢеҸҠеӨҡзәҝзЁӢзҡ„е®һдҫӢи®Іи§ЈвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





