python 对象查找 接上章-python_day17_Django-1
AutoField: int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
IntegerField: 一个整数类型,范围在 -2147483648 to 2147483647。
CharField: 字符类型,必须提供max_length参数, max_length表示字符长度。
DateField: 日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
DateTimeField: 日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
ForeignKey: 外键
ManyToManyField: 多表关连BooleanField: 布尔类型
IPAddressField(Field): 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制
URLField(CharField): 字符串类型,Django Admin以及ModelForm中提供验证 URL
FileField(Field): 字符串,路径保存在数据库,文件上传到指定目录
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
ImageField(FileField): 字符串,路径保存在数据库,文件上传到指定目录
- 参数: upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串)DecimalField: models.DecimalField(max_digits=5,decimal_places=2, default=99.99)
max_digits: 最大长度
decimal_places: 小数点的位数
null: 用于表示某个字段可以为空。
unique: 如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index: 如果db_index=True 则代表着为此字段设置索引。
default: 为该字段设置默认值。
DateField和DateTimeField 参数
auto_now_add: 配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now: 配置上auto_now=True,每次更新数据记录的时候会更新该字段。1、配置数据库 项目下的settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': "数据库名",
"USER": "帐号",
'PASSWORD': "密码",
"HOST": "地址",
"POST": 端口,
}
}
2、应用下的__init__.py文件 初始化db
import pymysql
pymysql.install_as_MySQLdb()
3、应用下的moduls.py 初始化表结构
类 = 表
字段 = 表结构
class Book(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=30, null=False)
data = models.DateTimeField(auto_now_add=True)
def __str__(self):
return "id: {} name: {}".format(self.id, self.name)
# 学生表
class Student(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=25, null=False)
borrow = models.ForeignKey(to=Book, on_delete=models.CASCADE)
def __str__(self):
return "id: {} name: {}".format(self.id, self.name)
4、根目录下创建一个py文件,用于直接查询数据库
import os
if __name__ == "__main__":
# 加载django项目配置信息
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "select_test.settings")
# 导入django,启动django
# 注意: 一定要先启动django项目,然后在运行这个py文件
import django
django.setup()
# 导入数据库models
from app01 import models
5、查询
print("all".center(50,"*"))
alls = models.Student.objects.all()
print(alls)
# 如果没有增加类 str 查找出来的是对象 字典形式
# <QuerySet [<Student: Student object (1)>, <Student: Student object (2)>, <Student: Student object (4)>]>
# for a in alls: 可以使用for 查看每个字典的内容
# print(a.name)
print("filter".center(50,"*"))
filters = models.Student.objects.filter(name="小熊")
print(filters) # <QuerySet [<Student: id: 1 name: 小熊>]>
filters2 = models.Student.objects.filter(name="小熊333")
print(filters2) # <QuerySet []>
# 如果查找的内容存在,那就返回列表,如果不存在那就直接为空,不报错
print("get".center(50,"*"))
gets = models.Student.objects.get(name="小熊")
print(gets) # id: 1 name: 小熊
# gets2 = models.Student.objects.get(name="小熊33")
# print(gets2) # 报错 app01.models.DoesNotExist: Student matching query does not exist.
# 如果查找的内容存在,直接返回内容,不存在就返回错误
print("exclude".center(50, "*"))
excludes = models.Student.objects.exclude(name="小熊")
print(excludes) # 如果存在这个值,取相反的结果
# <QuerySet [<Student: id: 2 name: 小熊2>, <Student: id: 4 name: 小1>]>
excludes2 = models.Student.objects.exclude(name="小熊33")
print(excludes2) # 当结果不存在就全部返回
# <QuerySet [<Student: id: 1 name: 小熊>, <Student: id: 2 name: 小熊2>, <Student: id: 4 name: 小1>]>
print("values".center(50, "*"))
values = models.Student.objects.values()
print(values) # 得到的是一个字典,跟all一样
# <QuerySet [{'id': 1, 'name': '小熊', 'borrow_id': 1}, {'id': 2, 'name': '小熊2', 'borrow_id': 1}, {'id': 4, 'name': '小1', 'borrow_id': 2}]>
print("values_list".center(50, "*"))
values_list = models.Student.objects.values_list()
print(values_list) # 得到的是元组,直接返回结果
# <QuerySet [(1, '小熊', 1), (2, '小熊2', 1), (4, '小1', 2)]>
print("order".center(50, "*"))
# 根据时间做出排序
order = models.Book.objects.all().order_by("date")
print(order)
# 对查询的结果进行排序
# <QuerySet [<Book: id: 1 name: 小熊的python自动化>, <Book: id: 2 name: 自动化python>, <Book: id: 3 name: flask>]>
print("reverse".center(50, "*"))
# 必须先做出有序的排序,然后才能用reverse进行倒序查询
order2 = models.Book.objects.all().order_by("date").reverse()
print(order2)
# <QuerySet [<Book: id: 3 name: flask>, <Book: id: 2 name: 自动化python>, <Book: id: 1 name: 小熊的python自动化>]>
print("count".center(50, "*"))
count = models.Book.objects.count()
print(count) # 统计表总共有多少行 3
print("first".center(50, "*"))
first = models.Book.objects.first()
print(first) # 打印出第一行,直接显示结果 id: 1 name: 小熊的python自动化
print("last".center(50, "*"))
last = models.Book.objects.last()
print(last) # 打印出最后一行,直接显示结果 id: 3 name: flask
print("exists".center(50, "*"))
exists = models.Book.objects.exists()
print(exists) # 结果为bule值, True或者False
返回QuerySet对象的方法有
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元祖序列
返回具体对象的
get()
first()
last()
返回布尔值的方法有:
exists()
返回数字的方法有
count()
6、下划线的使用
# gte : 大于等于
# lte : 小于等于
# 过滤掉大于等于1 小于3的值
lg_mod = models.Book.objects.filter(id__gte=1,id__lt=3)
print(lg_mod) # <QuerySet [<Book: id: 1 name: 小熊的python自动化>, <Book: id: 2 name: 自动化python>]>
# 包含这个值的内容,
ld_mod = models.Book.objects.filter(id__in=[1,3])
print(ld_mod) # <QuerySet [<Book: id: 1 name: 小熊的python自动化>, <Book: id: 3 name: flask>]>
# 反向查找
ld_exclude = models.Book.objects.exclude(id__in=[1,3])
print(ld_exclude) # <QuerySet [<Book: id: 2 name: 自动化python>]>
# 模糊匹配 ,查找包含py的内容 加上 name__icontaion 不区分大小写
ld_contains = models.Book.objects.filter(name__contains="py")
print(ld_contains) # <QuerySet [<Book: id: 1 name: 小熊的python自动化>, <Book: id: 2 name: 自动化python>]>
# 查找这个范围内的值
ld_range = models.Book.objects.filter(id__range=[2,3])
print(ld_range)
# <QuerySet [<Book: id: 2 name: 自动化python>, <Book: id: 3 name: flask>]>
1、数据库 modules.py
# 出版社
class Press(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=50)
class Books(models.Model):
'''
id 书编号
name: 书名
publish_time: 出版时间
press: 出版社
'''
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=25)
publish_time = models.DateTimeField(auto_now_add=True)
press = models.ForeignKey(to=Press, on_delete=models.CASCADE)
def __str__(self):
return "id: {} -- name: {} -- publish_time: {} -- press: {}".format(self.id,
self.name,self.publish_time, self.press)
class Auther(models.Model):
'''
boos 作者关连的书
'''
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=25)
books = models.ManyToManyField(to=Books)
2、sql语法:
INSERT INTO `test`.`app01_books` (`id`, `name`, `publish_time`, `press_id`) VALUES ('1', 'linux集群自动化', '2018-07-25 09:31:22.000000', '1');
INSERT INTO `test`.`app01_books` (`id`, `name`, `publish_time`, `press_id`) VALUES ('2', 'linux shell编程', '2018-07-25 09:31:47.000000', '2');
INSERT INTO `test`.`app01_books` (`id`, `name`, `publish_time`, `press_id`) VALUES ('3', 'python django开发编程', '2018-07-25 10:08:23.000000', '1');
INSERT INTO `test`.`app01_press` (`id`, `name`) VALUES ('1', '北京第一出版社');
INSERT INTO `test`.`app01_press` (`id`, `name`) VALUES ('2', '北京第二出版社');
INSERT INTO `test`.`app01_auther` (`id`, `name`) VALUES ('1', 'xiong');
INSERT INTO `test`.`app01_auther` (`id`, `name`) VALUES ('2', 'yu');
INSERT INTO `test`.`app01_auther_books` (`id`, `auther_id`, `books_id`) VALUES ('1', '1', '1');
INSERT INTO `test`.`app01_auther_books` (`id`, `auther_id`, `books_id`) VALUES ('2', '1', '2');
INSERT INTO `test`.`app01_auther_books` (`id`, `auther_id`, `books_id`) VALUES ('3', '2', '1'); 数据表关系 大致 
3、创建一个py文件,用于直接查询数据库
import os
if __name__ == "__main__":
# 加载django项目配置信息
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "select_test.settings")
# 导入django
import django
django.setup() # 启动django项目
from app01 import models 导入模块
# 正向查找 书查找出版社 由对象直接查找
books = models.Books.objects.first()
# 必须是要 queryset对象,必须会报这个错:AttributeError: 'QuerySet' object has no attribute 'name'
print(books.press) # 得到关联的出版社对象
print(books.press.name) # 得到这本书的出版社
# 正向查找, 字段查找
# 注意 这里是关联字段义外键的名称,而不是表的名称, 双下划线就表示跨了一张表
ret = models.Books.objects.values_list("press__name")
print(ret)
# < QuerySet[('北京第一出版社',), ('北京第二出版社',)] >
print("反向对象查找".center(50,"*"))
publisher_obj = models.Press.objects.first()
books2 = publisher_obj.books_set.all()
print(books2) # 查找第一个出版社对应书籍,对应多少本书,都会打印出来
# <QuerySet [<Books: id: 1 -- name: linux集群自动化 -- publish_time: 2018-07-25 09:31:22+00:00 -- press: Press object (1)>,
# <Books: id: 3 -- name: python django开发编程 -- publish_time: 2018-07-25 10:08:23+00:00 -- press: Press object (1)>]>
# 反向对象查找, 出版社所有的列表对应的书藉, queryset对象
print(models.Press.objects.values_list("books__name"))
# <QuerySet [('linux集群自动化',), ('linux shell编程',), ('python django开发编程',)]>
将modules添加这个属性:related_name, 在反向处理时就不需要加上 **_set了
class Books(models.Model):
'''
id 书编号
name: 书名
publish_time: 出版时间
press: 出版社
'''
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=25)
publish_time = models.DateTimeField(auto_now_add=True)
press = models.ForeignKey(to=Press, on_delete=models.CASCADE, related_name="book")
# 添加 related_name 反向对象操作
publisher_obj = models.Press.objects.first()
books3 = publisher_obj.book.all()
print("books3: {}".format(books3))
# 反向字段操作
print(models.Press.objects.values_list("book__name"))
# <QuerySet [('linux集群自动化',), ('linux shell编程',), ('python django开发编程',)]> 可迭代的对象
# 例
ret = models.Press.objects.filter(id=1).values_list("book__name")
print(ret) # 只获取出版社为 第一出版社的书
# <QuerySet [('linux集群自动化',), ('python django开发编程',)]>
对应sql语句为:SELECT `app01_books`.`name` FROM `app01_press` LEFT OUTER JOIN `app01_books` ON (`app01_press`.`id` = `app01_books`.`press_id`) WHERE `app01_press`.`id` = 1 LIMIT 21; args=(1,)
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器。
它存在于下面两种情况:
外键关系的反向查询
多对多关联关系
1、create 方法
auther_obj = models.Auther.objects.first()
print(auther_obj)
# 给第一个作者 创建一本书并关连 注意:publish_time 测试过程中我删了
# 注意 press不是model.py创建的字段,而是数据库中的字段,
auther_obj.books.create(name="flask web开发",press_id=2)
# auther.books.create(name="flask web开发",publish_time=datetime.datetime.now(),press_id=1)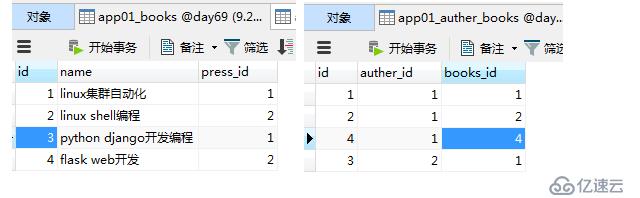
查询: print(models.Auther.objects.filter(name="xiong").values_list("books__name"))
结果: <QuerySet [('linux集群自动化',), ('linux shell编程',), ('flask web开发',)]>2、add 方法
# 获取返回具体对象的值
# 在yu关联的书里面,加一本id为1的书
auther_obj = models.Auther.objects.get(id=2)
book_obj = models.Books.objects.get(id=1)
auther_obj.books.add(book_obj)
print(models.Auther.objects.filter(id=2).values_list("books__name"))
# <QuerySet [('linux集群自动化',)]>
# 查找编号为2的作者,书籍编号大于2的 然后展开写入到作者的第三张表中
auther_obj = models.Auther.objects.get(id=2)
book_objs = models.Books.objects.filter(id__gt=2)
auther_obj.books.add(*book_objs)
print(models.Auther.objects.filter(id=2).values_list("books__name"))
# < QuerySet[('linux集群自动化',), ('python django开发编程',), ('flask web开发',)] >
3、remove方法
# 将作者为2的 linux集群这本书删除
auther_obj = models.Auther.objects.get(id=2)
book_obj = models.Books.objects.get(name="linux集群自动化")
auther_obj.books.remove(book_obj)
4、clear 方法
# 将作者为2的 所有的书全部删除
book_clear = models.Auther.objects.get(id=2)
book_clear.books.clear()
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
聚合
1、数据库表 Books 字段 增加, 然后进 Book表修改下数据
price = models.DecimalField(max_digits=5,decimal_places=2, default=99.99)
2、查询
from django.db.models import Avg, Sum, Max, Min, Count
avg_ret = models.Books.objects.all().aggregate(avg_price = Avg("price"))
print(avg_ret) # 平均值
ret = models.Books.objects.all().aggregate(sum = Sum("price"),max = Max("price"), min = Min("price"), count = Count("price") )
print(ret) # {'sum': Decimal('96.97'), 'max': Decimal('44.99'), 'min': Decimal('6.99'), 'count': 4}分组
1、统计每一本书分别有多少个作者
ret = models.Books.objects.all().annotate(aaa = Count("auther"))
# ret 打印结果为: <QuerySet [<Books: id: 1 -- name: linux集群自动化 -- -- press: Press object (1)>, <Books: id: 2 -- name: linux shell编程 -- -- press: Press object (2)>, <Books: id: 3 -- name: python django开发编程 -- -- press: Press object (1)>, <Books: id: 4 -- name: flask web开发 -- -- press: Press object (2)>]>
for book in ret:
print(book.id,book.aaa)
# 作者id号,以及对应有多少书
1 2
2 2
2、显示每个出版社最便宜的书
min_publish = models.Press.objects.annotate(mins = Min("book__price"))
for min_pub in min_publish:
print(min_pub.mins)
结果: 6.99 \n 33.00
方法二: xx= models.Books.objects.values("press__name").annotate(mins = Min("price")) \n print(xx)
3、取出作者大写两本的书
book_obj = models.Books.objects.annotate(auther_num=Count("auther")).filter(auther_num__gt=1)
for books in book_obj:
print(books.name,books.auther_num)
结果:linux shell编程 2
4、根据图书进行排序
ret = models.Books.objects.annotate(author_num=Count("auther")).order_by("author_num")
print(ret)
# <QuerySet [<Books: id: 3 -- name: python django开发编程 -- >, <Books: id: 4 -- name: flask web开发 -- >, <Books: id: 2 -- name: linux shell编程 -- >, <Books: id: 1 -- name: linux集群自动化 -- >]>
5、 查询出每个作者书本的总价
ret = models.Auther.objects.annotate(sum_price=Sum("books__price")).values("name","sum_price")
print(ret)
F查询
from django.db.models import F,Q
# 查询仓库数大于销售数的书藉
print(models.Books.objects.filter(depot__gt=F("sale")).values_list())
# <QuerySet [(1, 'linux集群自动化', 80, 20, Decimal('6.99'), 1), (2, 'linux shell编程', 60, 40, Decimal('44.99'), 2)]>
# 单个用户的值乘以三
models.Books.objects.filter(id=1).update(sale=F("sale")*3)
# 更新,将所有的书都乘以三,必须是queryset对象的才能操作
models.Books.objects.update(sale=F("sale")*3)
# 在书藉后面加上第一版
from django.db.models.functions import Concat
from django.db.models import Value
models.Books.objects.filter(id=1).update(name=Concat(F("name"),Value("第一版")))Q查询
| and, , or ~ 取反 & 或者
# 查找出 作者为xiong或者xx的书藉
auth_obj = models.Books.objects.filter(Q(auther__name="xiong")|Q(auther__name="xx"))
print(auth_obj)
# 查找作者为xiong,价格小于10的
方法一: print(models.Books.objects.filter(Q(auther__name="xiong") &~ Q(price__gt=10)).values_list())
项目中的settings.py中最后一行添加, 并重启项目
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
数据库中时间格式化
extra 使用原生的sql 语法 extra=( select = {"xx": "xx"})
如extra(select={"c": "age > 30"})
# sqlite3 时间格式化
# select strftime('%Y/%m/%d', '2018-01-01 11:22:22');
ret = models.Article.objects.filter(user=user).extra(select={"c": "strftime('%%Y-%%m',create_time)"}).values("c")
结果为 <QuerySet [{'c': '2018-12'}, {'c': '2018-12'}]>
select strftime('%Y/%m/%d', '2018-12-06 11:04:24');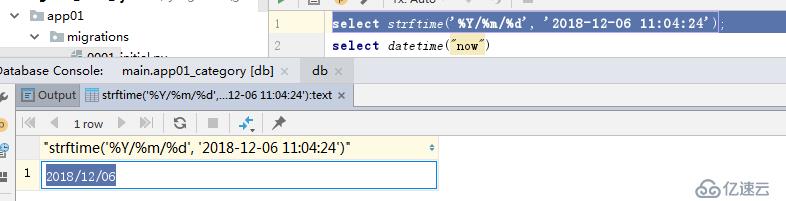
mysql时间格式化 date_format(字段, "格式化")
ret = models.Article.objects.filter(user=user).extra(select={"c": "date_format(create_time, '%%Y-%%m')"}).values("c")
结果跟sqlite3一样 注意的是create_time传递的参数不需要加引号
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务


