这篇文章主要讲解了“怎么连接JAVA高并发的线程和线程池”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么连接JAVA高并发的线程和线程池”吧!
1 JAVA线程的实现原理
java的线程是基于操作系统原生的线程模型(非用户态),通过系统调用,将程序的线程交给系统调度执行
java线程拥有属于自己的虚拟机栈,当JVM将栈、程序计数器、工作内存等准备好后,会分配一个系统原生线程来执行。Java线程结束,原生线程随之被回收
原生线程初始化完毕,会调Java线程的run方法。当JAVA线程结束时,则释放原生线程和Java线程的所有资源
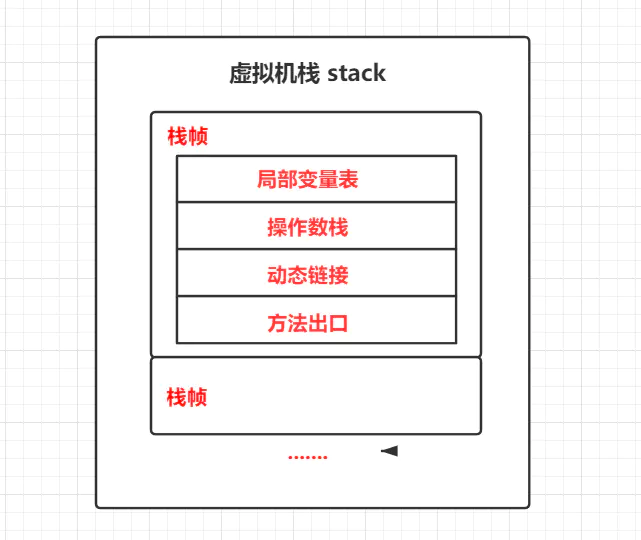
java方法的执行对应虚拟机栈的一个栈帧,用于存储局部变量、操作数栈、动态链接、方法出口等
2 JAVA线程的生命周期
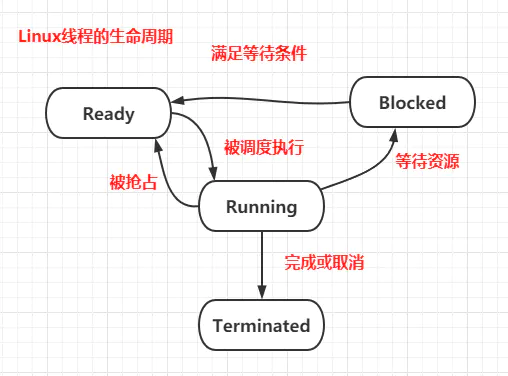
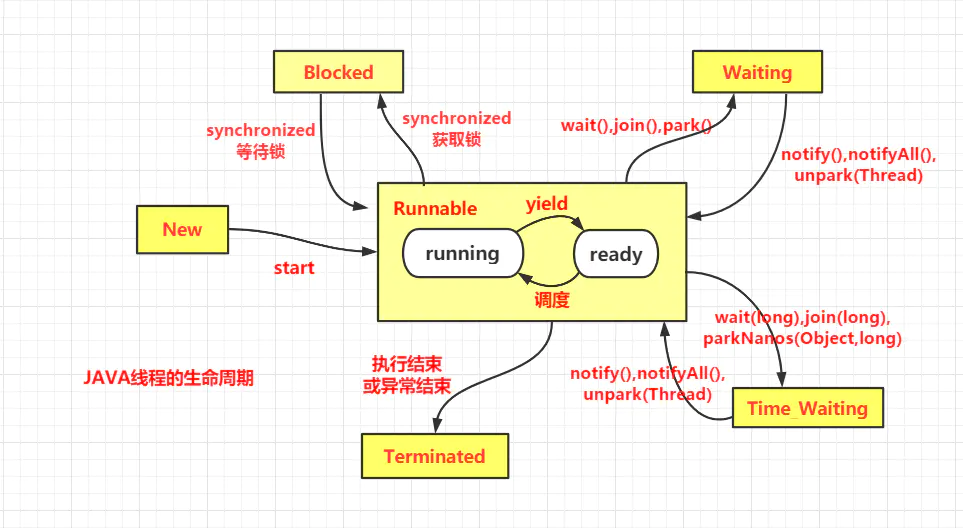
New(新建状态):用new关键字创建线程之后,该线程处于新建状态,此时仅由JVM为其分配内存,并初始化其成员变量
Runnable(就绪状态):当调用Thread.start方法后,该线程处于就绪状态。JVM会为其分配虚拟机栈等,然后等待系统调度
running(运行状态):处于就绪状态的线程获得CPU,执行run方法时,则线程处于运行状态
Terminated(线程死亡):线程正常run结束、或抛出一个未捕获的Throwable、调用Thread.stop来结束该线程,都会导致线程的死亡
3 JAVA线程的几种常用方法
「线程启动函数」
//Thread.java //调用start启动线程,进入Runnable状态,等待系统调度执行 public synchronized void start(){//synchronized同步执行 if (threadStatus != 0) //0 代表new状态,非0则抛出错误 throw new IllegalThreadStateException(); ... start0(); //本地方法方法 private native void start0() ... } //Running状态,新线程执行的代码方法,可被子类重写 public void run() { if (target != null) { //target是Runnable,new Thread(Runnable)时传入 target.run(); } }「线程终止函数」
//Thread.java @Deprecated public final void stop(); //中断线程 public void interrupt() //判断的是当前线程是否处于中断状态 public static boolean interrupted()用stop会强行终止线程,导致线程所持有的全部锁突然释放(不可控制),而被锁突同步的逻辑遭到破坏。不建议使用
interrupt函数中断线程,但它不一定会让线程退出的。它比stop函数优雅,可控制
当线程处于调用sleep、wait的阻塞状态时,会抛出InterruptedException,代码内部捕获,然后结束线程
线程处于非阻塞状态,则需要程序自己调用interrupted()判断,再决定是否退出
其他常用方法
//Thread.java //阻塞等待其他线程 public final synchronized void join(final long millis) //暂时让出CPU执行 public static native void yield(); //休眠一段时间 public static native void sleep(long millis) throws InterruptedException;start与run方法的区别
start是Thread类的方法,从线程的生命周期来看,start的执行并不意味着新线程的执行,而是让JVM分配虚拟机栈,进入Runnable状态,start的执行还是在旧线程上
run则是新线程被系统调度,获取CPU时,执行的方法,必须是继承Thread或者是实现Runnable接口
Thread.sleep与Object.wait区别
Thread.sleep需要指定休眠时间,时间一到继续运行;和锁机制无关,不能加锁也不用释放锁
Object.wait需要在synchronized中调用,否则报IllegalMonitorStateException错误。wait方法会释放锁,需要调用相同锁对象Object.notify来唤醒线程
4 线程池及其优点
线程的每次使用时创建,结束再销毁,是非常巨大的开销。若用缓存的策略(线程池),暂存曾经创建的线程,复用这些线程,可以减少程序的消耗,提高线程的利用率
降低资源消耗:重复利用线程可降低线程创建和销毁造成的消耗
提高响应速度:当任务到达时,不需要等待线程创建就能立即执行
提高线程的可管理性:使用线程池可以进行统一的分配,监控和调优
5 JDK封装的线程池
//ThreadPoolExecutor.java public ThreadPoolExecutor( int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)1 corePoolSize:核心线程数,线程池维持的线程数量
2 maximumPoolSize:最大的线程数,当阻塞队列不可再接受任务时且maximumPoolSize大于corePoolSize则会创建非核心线程来执行。无任务执行时,会被销毁
3 keepAliveTime:非核心线程在闲暇间的存活时间
4 TimeUnit:和keepAliveTime配合使用,表示keepAliveTime参数的时间单位
5 workQueue:正在执行的任务数超过corePoolSize时,任务的等待阻塞队列
6 threadFactory:线程的创建工厂
7 handler:拒绝策略,线程数达到了maximumPoolSize,还有任务提交则使用拒绝策略处理
6 线程池原理之执行流程
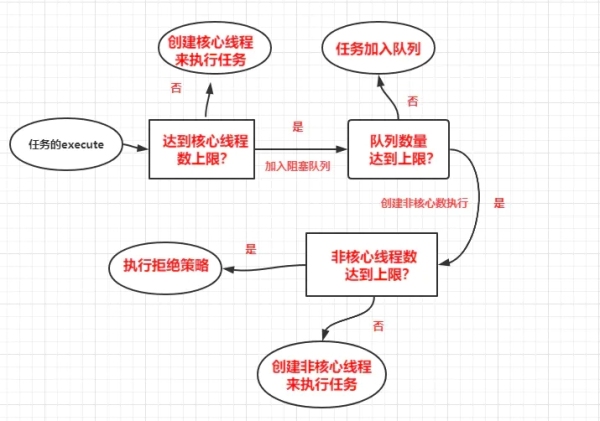
//ThreadPoolExecutor.java public void execute(Runnable command) { ... if (workerCountOf(c) < corePoolSize) { //plan A if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { //plan B int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } //addWorker(command, false) false代表可创建非核心线程执行任务 else if (!addWorker(command, false)) //plan C reject(command); // //plan D }plan A:任务的execute,先判断核心线程数量达到上限;否,则创建核心线程来执行任务;是,则执行plan B
plan B:当任务数大于核心数时,任务被加入阻塞队列,如果超过阻塞队列的容量上限,执行C
plan C: 阻塞队列不能接受任务时,且设置的maximumPoolSize大于corePoolSize,创建新的非核心线程执行任务
plan D:当plan A、B、C都无能为力时,使用拒绝策略处理
7 阻塞队列的简单了解
队列的阻塞插入:当队列满时,队列会阻塞插入元素的线程,直到队列不满
队列的阻塞移除:当队列为空时,获取元素的线程会等待队列变为非空
BlockingQueue提供的方法如下,其中put和take是阻塞操作
| 操作方法 | 抛出异常 | 阻塞线程 | 返回特殊值 | 超时退出 |
|---|---|---|---|---|
| 插入元素 | add(e) | put(e) | offer(e) | offer(e, timeout, unit) |
| 移除元素 | remove() | take() | poll() | pull(timeout, unit) |
| 检查 | element() | peek() | 无 | 无 |
「ArrayBlockingQueue」
ArrayBlockingQueue是用数组实现的「有界阻塞队列」,必须指定队列大小,先进先出(FIFO)原则排队
「LinkedBlockingQueue」
是用链表实现的「有界阻塞队列」,如果构造LinkedBlockingQueue时没有指定大小,则默认是Integer.MAX_VALUE,无限大
该队列生产端和消费端使用独立的锁来控制数据操作,以此来提高队列的并发性
「PriorityBlockingQueue」
public PriorityBlockingQueue(int initialCapacity, Comparator comparator)基于数组,元素具有优先级的「无界阻塞队列」,优先级由Comparator决定
PriorityBlockingQueue不会阻塞生产者,却会在没有可消费的任务时,阻塞消费者
「DelayQueue」
支持延时获取元素的「无界阻塞队列」,基于PriorityQueue实现
元素必须实现Delayed接口,指定多久才能从队列中获取该元素。
可用于缓存系统的设计、定时任务调度等场景的使用
「SynchronousQueue」
SynchronousQueue是一种无缓冲的等待队列,「添加一个元素必须等待被取走后才能继续添加元素」
「LinkedTransferQueue」
由链表组成的TransferQueue「无界阻塞队列」,相比其他队列多了tryTransfer和transfer函数
transfer:当前有消费者正在等待元素,则直接传给消费者,「否则存入队尾,并阻塞等待元素被消费才返回」
tryTransfer:试探传入的元素是否能直接传给消费者。如果没消费者等待消费元素,元素加入队尾,返回false
「LinkedBlockingDeque」
LinkedBlockingDeque是由链表构建的双向阻塞队列,多了一端可操作入队出队,少了一半的竞争,提高并发性
8 Executors的四种线程池浅析
「newFixedThreadPool」
指定核心线程数,队列是LinkedBlockingQueue无界阻塞队列,永远不可能拒绝任务;适合用在稳定且固定的并发场景,建议线程设置为CPU核数
//Executors.java public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }「newCachedThreadPool」
核心池大小为0,线程池最大线程数为最大整型,任务提交先加入到阻塞队列中,非核心线程60s没任务执行则销毁,阻塞队列为SynchronousQueue。newCachedThreadPool会不断的创建新线程来执行任务,不建议用
//Executors.java public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }「newScheduledThreadPool」
ScheduledThreadPoolExecutor(STPE)其实是ThreadPoolExecutor的子类,可指定核心线程数,队列是STPE的内部类DelayedWorkQueue。「STPE的好处是 A 延时可执行任务,B 可执行带有返回值的任务」
//Executors.java public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory) { super(corePoolSize, Integer.MAX_VALUE, DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS, new DelayedWorkQueue(), threadFactory); } //指定延迟执行时间 public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit)「newSingleThreadExecutor」
和newFixedThreadPool构造方法一致,不过线程数被设置为1了。SingleThreadExecutor比new个线程的好处是;「线程运行时抛出异常的时候会有新的线程加入线程池完成接下来的任务;阻塞队列可以保证任务按FIFO执行」
//Executors.java public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); //无界队列 }9 如果优雅地关闭线程池线程池
的关闭,就要先关闭池中的线程,上文第三点有提,暴力强制性stop线程会导致同步数据的不一致,因此我们要调用interrupt关闭线程
而线程池提供了两个关闭方法,shutdownNow和shuwdown
shutdownNow:线程池拒接收新任务,同时立马关闭线程池(执行中的会继续执行完),队列的任务不再执行,返回未执行任务List
public List<Runnable> shutdownNow() { ... final ReentrantLock mainLock = this.mainLock; mainLock.lock(); //加锁 try { checkShutdownAccess(); advanceRunState(STOP); interruptWorkers(); //interrupt关闭线程 tasks = drainQueue(); //未执行任务 ...shuwdown:线程池拒接收新任务,同时等待线程池里的任务执行完毕后关闭线程池,代码和shutdownNow类似就不贴了
10 线程池为什么使用的是阻塞队列
先考虑下为啥线程池的线程不会被释放,它是怎么管理线程的生命周期的呢
//ThreadPoolExecutor.Worker.class final void runWorker(Worker w) { ... //工作线程会进入一个循环获取任务执行的逻辑 while (task != null || (task = getTask()) != null) ... } private Runnable getTask(){ ... Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); //线程会阻塞挂起等待任务, ... }可以看出,无任务执行时,线程池其实是利用阻塞队列的take方法挂起,从而维持核心线程的存活
11 线程池的worker继承AQS的意义
//Worker class,一个worker一个线程 Worker(Runnable firstTask) { //禁止新线程未开始就被中断 setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); } final void runWorker(Worker w) { .... //对应构造Worker是的setState(-1) w.unlock(); // allow interrupts boolean completedAbruptly = true; .... w.lock(); //加锁同步 .... try { ... task.run(); afterExecute(task, null); } finally { .... w.unlock(); //释放锁 }worker继承AQS的意义:A 禁止线程未开始就被中断;B 同步runWorker方法的处理逻辑
12 拒绝策略
AbortPolicy 「丢弃任务并抛出RejectedExecutionException异常」
DiscardOldestPolicy 「丢弃队列最前面的任务,然后重新提交被拒绝的任务」
DiscardPolicy 「丢弃任务,但是不抛出异常」
CallerRunsPolicy
❝A handler for rejected tasks that runs the rejected task directly in the calling thread of the {@code execute} method, unless the executor has been shut down, in which case the task is discarded.❞
如果任务被拒绝了,则由「提交任务的线程」执行此任务
13 ForkJoinPool了解一波
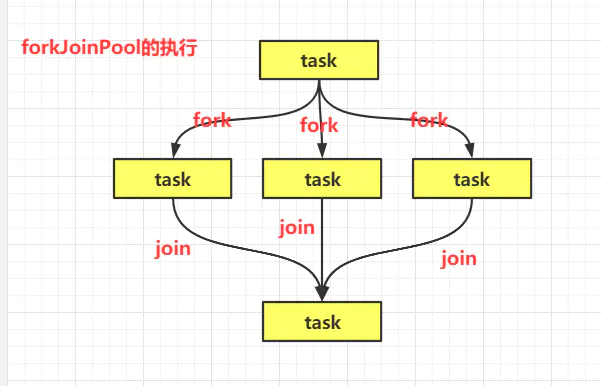
ForkJoinPool和ThreadPoolExecutor不同,它适合执行可以分解子任务的任务,如树的遍历,归并排序等一些递归场景

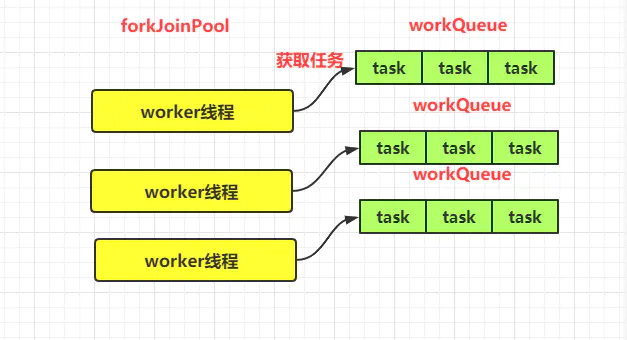
ForkJoinPool每个线程有一个对应的双端队列deque;当线程中的任务被fork分裂,分裂出来的子任务会放入线程自己的deque,减少线程的竞争
work-stealing工作窃取算法
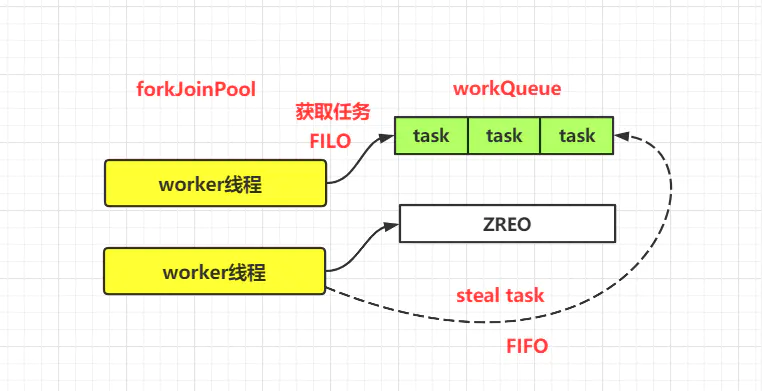
当线程执行完自己deque的任务,且其他线程deque还有多的任务,则会启动窃取策略,从其他线程deque队尾获取线程
使用RecursiveTask实现forkjoin流程demo
public class ForkJoinPoolTest { public static void main(String[] args) throws ExecutionException, InterruptedException { ForkJoinPool forkJoinPool = new ForkJoinPool(); for (int i = 0; i < 10; i++) { ForkJoinTask task = forkJoinPool.submit(new Fibonacci(i)); System.out.println(task.get()); } } static class Fibonacci extends RecursiveTask<Integer> { int n; public Fibonacci(int n) { this.n = n; } @Override protected Integer compute() { if (n <= 1) { return n; } Fibonacci fib1 = new Fibonacci(n - 1); fib1.fork(); //相当于开启新线程执行 Fibonacci fib2 = new Fibonacci(n - 2); fib2.fork(); //相当于开启新线程执行 return fib1.join() + fib2.join(); //合并阻塞返回结果 } } }感谢各位的阅读,以上就是“怎么连接JAVA高并发的线程和线程池”的内容了,经过本文的学习后,相信大家对怎么连接JAVA高并发的线程和线程池这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://juejin.im/post/5f016bd16fb9a07e9a07a09f



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



