本文来自社区用户投稿,感谢这位小伙伴的技术分享
巨杉数据库架构简介
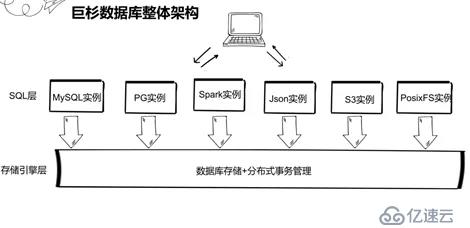
巨杉数据库作为分布式数据库是计算和存储分离架构,由数据库实例层和存储引擎层组成的。存储引擎层负责数据库核心功能比如数据读写存储以及分布式事务管理。数据库实例层也就是这里的的SQL层负责把应用SQL请求处理后发存储引擎层处理,并且把存储引擎层响应结果反馈给应用层。支持结构化实例比如MySQL实例/PG实例/spark实例,也支持非结构化实例比如 Json实例/S3对象存储实例/PosixFs实例等等。这种架构支持的实例类型比较多,方便从传统数据库无缝迁移到巨杉数据库,减小了开发学习成本,之前也跟数据库圈同行交流,他们对架构也是十分认可。
这里的SQL层采用的是MySQL实例,存储引擎层是有三个数据节点和协调节点编目节点组成。其中数据节点就是用来存储数据的,协调节点不存储数据,是用来把MySQL的请求进行路由分发到数据库节点。编目节点用来存储集群的系统信息比如用户信息/分区信息等等。这里用一个容器来模拟一个物理机或云虚拟机,这里设置的是MySQL实例在一个容器里,编目和节点和协调节点放在了一个容器,三个数据节点分别放在一个容器,三个数据节点构成了三个数据组,每个数据组三个副本。Web应用的海量数据是通过分片切分的方式分散给不同的数据节点,像这里的数据ABC通过分片打散到三台机器。
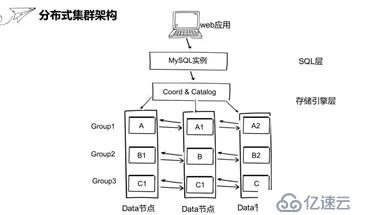
这里的数据分片是通过分布式Hash算法DHT机制实现,DHT是distribute Hashing table 缩写。当写入数据时,首先通过MySQL实例把记录下发到协调节点,协调节点会通过分布式Hash算法根据每条记录的分区键进行散列,散列完之后协调节点根据分区键判断到底发送到哪一个分区,所以每个分区之间的数据是完全隔离互相独立的。采用这种方法,我们就可以把一个很大的表拆散到下面不同的子分区里面小表,实现数据拆分。
mysqldump和 mydumper/myloader
导入导出工具实战
SequoiaDB实现了对MySQL的完整兼容,那么有的用户会问了:
“既然是完整兼容,MySQL相关的工具是否能使用?”
“数据从MySQL迁移到SequoiaDB如何操作?”
下面我们就介绍SequoiaDB如何使用 mysqldump和 mydumper/myloader 进行数据的导入导出。
1)通过存储过程制造测试数据
#mysql -h 127.0.0.1 -P 3306 -u root
mysql>create database news;
mysql>use news;
mysql>create table user_info(id int(11),unickname varchar(100));
delimiter //
create procedure `news`.`user_info_PROC`()
begin
declare iloop smallint default 0;
declare iNum mediumint default 0;
declare uid int default 0;
declare unickname varchar(100) default 'test';
while iNum <=10 do
start transaction;
while iloop<=10 do
set uid=uid+1;
set unickname=CONCAT('test',uid);
insert into `news`.`user_info`(id,unickname)
values(uid,unickname);
set iloop=iloop+1;
end while;
set iloop=0;
set iNum=iNum+1;
commit;
end while;
end//
delimiter ;
call news.user_info_PROC();2)查看制造测试数据状况
mysql> use news;
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
1 row in set (0.00 sec)
mysql> select count(*) from user_info;
+----------+
| count(*) |
+----------+
| 121 |
+----------+
1 row in set (0.01 sec)3)执行下面mysqldump备份指令
#/opt/sequoiasql/mysql/bin/mysqldump -h 127.0.0.1 -P 3306 -u
root -B news > news.sql查看到对应的文件为news.sql
然后登陆到数据库删除原来的数据库数据
mysql> drop database news;
Query OK, 1 row affected (0.10 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)4)用source导入新的数据
#/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
使用mysqldump导出的完整sql语句,直接登陆数据库执行导入即可:
#/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
mysql>source news.sql
mysql> use news;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with-A
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
1 row in set (0.00 sec)可以看到返回结果,的确支持mysqldump数据导出工具和source导入工具。
这一章节将介绍有关mydumper和myloader工具的使用。
有的同学对于mysqldump与mydumper有点混淆:mysqldump是MySQL原厂自带的。mydumper/myloader是由MySQL /Facebook等公司开发维护的一套逻辑备份恢复工具,DBA较常使用,需要单独安装,具体安装方式可以在网络上进行查询。
针对SequoiaDB使用mydumper/myloader的情况,
我们首先查看mydumper版本号
# mydumper --version
mydumper 0.9.1, built against MySQL 5.7.171)mydumper导出数据
# mydumper -h 127.0.0.1 -P 3306 -u root -B news -o /home/sequoiadb
删除原来的数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| news |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> drop database news;
Query OK, 1 row affected (0.13 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)2)myloader 导入数据
可以看到数据已经被删除,利用myloader导入数据
#myloader -h 127.0.0.1 -P 3306 -u root -B news -d /home/sequoiadb
登陆到数据库中查看
# /opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| news |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> use news;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
1 row in set (0.00 sec)
mysql> select count(*) from user_info;
+----------+
| count(*) |
+----------+
| 121 |
+----------+
1 row in set (0.00 sec)mydumper 及 myloader 导入数据没问题,看来巨杉数据库 Sequoiadb 的确支持 MySQL 的兼容工具 mydumper 及 myloader。
迁移 MySQL 数据库数据只需要把 MySQL 数据利用 mydumper 导出之后,在巨杉数据库利用 myloader 导入到巨杉数据库即可。
总结
巨杉数据库采用计算-存储分离的架构,实现了MySQL的100%完整兼容。通过本文,我们也可以看到,巨杉数据库可以支持所有标准MySQL的周边工具,同时分布式可扩展性将大大提升已有应用的扩展性以及整体数据管理能力。因此,巨杉数据库SequoiaDB可以说是传统单点MySQL方案的一种有力替换。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





