如何通过Serverless 轻松识别验证码,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
前言
Serverless 概念自被提出就倍受关注,尤其是近些年来 Serverless 焕发出了前所未有的活力,各领域的工程师都在试图将 Serverless 架构与自身工作相结合,以获取到 Serverless 架构所带来的“技术红利”。
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序。可以防止恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断地登陆尝试。实际上验证码是现在很多网站通行的方式,我们利用比较简易的方式实现了这个功能。CAPTCHA 的问题由计算机生成并评判,但是这个问题只有人类才能解答,计算机是无法解答的,所以回答出问题的用户就可以被认为是人类。说白了,验证码就是用来验证的码,验证是人访问的还是机器访问的“码”。
那么人工智能领域中的验证码识别与 Serverless 架构会碰撞出哪些火花呢?本文将通过 Serverless 架构和卷积神经网络(CNN)算法,实现验证码识别功能。
浅谈验证码
验证码的发展,可以说是非常迅速的,从开始的单纯数字验证码,到后来的数字+字母验证码,再到后来的数字+字母+中文的验证码以及图形图像验证码,单纯的验证码素材已经越来越多了。从验证码的形态来看,也是各不相同,输入、点击、拖拽以及短信验证码、语音验证码……
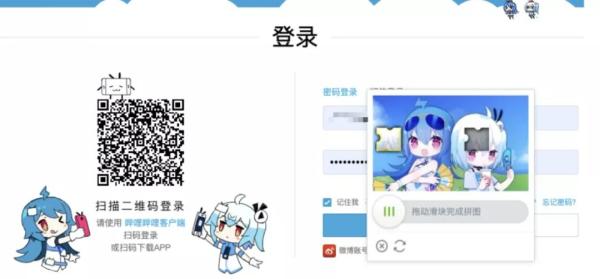
Bilibili 的登录验证码就包括了多种模式,例如滑动滑块进行验证:
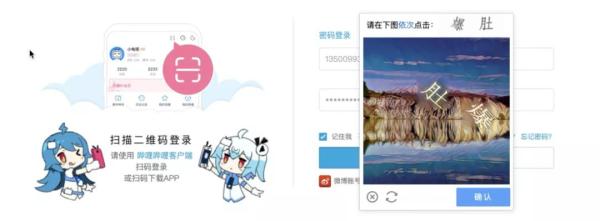
例如,通过依次点击文字进行验证:
而百度贴吧、知乎、以及 Google 等相关网站的验证码又各不相同,例如选择正着写的文字、选择包括指定物体的图片以及按顺序点击图片中的字符等。
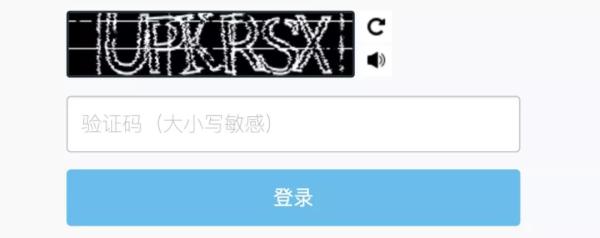
验证码的识别可能会根据验证码的类型而不太一致,当然最简单的验证码可能就是最原始的文字验证码了:

即便是文字验证码,也是存在很多差异的,例如简单的数字验证码、简单的数字+字母验证码、文字验证码、验证码中包括计算、简单验证码中增加一些干扰成为复杂验证码等。
验证码识别
1. 简单验证码识别
验证码识别是一个古老的研究领域,简单说就是把图片上的文字转化为文本的过程。最近几年,随着大数据的发展,广大爬虫工程师在对抗反爬策略时,对验证码的识别要求也越来越高。在简单验证码的时代,验证码的识别主要是针对文本验证码,通过图像的切割,对验证码每一部分进行裁剪,然后再对每个裁剪单元进行相似度对比,获得最可能的结果,最后进行拼接,例如将验证码:

进行二值化等操作:

完成之后再进行切割:

切割完成再进行识别,最后进行拼接,这样的做法是,针对每个字符进行识别,相对来说是比较容易的。
但是随着时间的发展,在这种简单验证码逐渐无法满足判断“是人还是机器”的问题时,验证码进行了一次小升级,即验证码上面增加了一些干扰线,或者验证码进行了严重的扭曲,增加了强色块干扰,例如 Dynadot 网站的验证码:
不仅有图像扭曲重叠,还有干扰线和色块干扰。这个时候想要识别验证码,简单的切割识别就很难获得良好的效果了,这时通过深度学习反而可以获得不错的效果。
2. 基于 CNN 的验证码识别
卷积神经网络(Convolutional Neural Network,简称 CNN),是一种前馈神经网络,人工神经元可以响应周围单元,进行大型图像处理。卷积神经网络包括卷积层和池化层。

如图所示,左图是传统的神经网络,其基本结构是:输入层、隐含层、输出层。右图则是卷积神经网络,其结构由输入层、输出层、卷积层、池化层、全连接层构成。卷积神经网络其实是神经网络的一种拓展,而事实上从结构上来说,朴素的 CNN 和朴素的 NN 没有任何区别(当然,引入了特殊结构的、复杂的 CNN 会和 NN 有着比较大的区别)。相对于传统神经网络,CNN 在实际效果中让我们的网络参数数量大大地减少,这样我们可以用较少的参数,训练出更加好的模型,典型的事半功倍,而且可以有效地避免过拟合。同样,由于 filter 的参数共享,即使图片进行了一定的平移操作,我们照样可以识别出特征,这叫做 “平移不变性”。因此,模型就更加稳健了。
1)验证码生成
验证码的生成是非常重要的一个步骤,因为这一部分的验证码将会作为我们的训练集和测试集,同时最终我们的模型可以识别什么类型的验证码,也是和这部分有关。
# coding:utf-8 import random import numpy as np from PIL import Image from captcha.image import ImageCaptcha CAPTCHA_LIST = [eve for eve in "0123456789abcdefghijklmnopqrsruvwxyzABCDEFGHIJKLMOPQRSTUVWXYZ"] CAPTCHA_LEN = 4 # 验证码长度 CAPTCHA_HEIGHT = 60 # 验证码高度 CAPTCHA_WIDTH = 160 # 验证码宽度 randomCaptchaText = lambda char=CAPTCHA_LIST, size=CAPTCHA_LEN: "".join([random.choice(char) for _ in range(size)]) def genCaptchaTextImage(width=CAPTCHA_WIDTH, height=CAPTCHA_HEIGHT, save=None): image = ImageCaptcha(width=width, height=height) captchaText = randomCaptchaText() if save: image.write(captchaText, './img/%s.jpg' % captchaText) return captchaText, np.array(Image.open(image.generate(captchaText))) print(genCaptchaTextImage(save=True))通过上述代码,可以生成简单的中英文验证码:
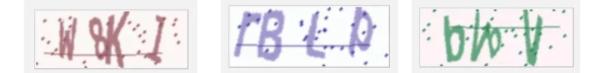
2)模型训练
模型训练的代码如下(部分代码来自网络)。
util.py 文件,主要是一些提取出来的公有方法:
# -*- coding:utf-8 -*- import numpy as np from captcha_gen import genCaptchaTextImage from captcha_gen import CAPTCHA_LIST, CAPTCHA_LEN, CAPTCHA_HEIGHT, CAPTCHA_WIDTH # 图片转为黑白,3维转1维 convert2Gray = lambda img: np.mean(img, -1) if len(img.shape) > 2 else img # 验证码向量转为文本 vec2Text = lambda vec, captcha_list=CAPTCHA_LIST: ''.join([captcha_list[int(v)] for v in vec]) def text2Vec(text, captchaLen=CAPTCHA_LEN, captchaList=CAPTCHA_LIST): """ 验证码文本转为向量 """ vector = np.zeros(captchaLen * len(captchaList)) for i in range(len(text)): vector[captchaList.index(text[i]) + i * len(captchaList)] = 1 return vector def getNextBatch(batchCount=60, width=CAPTCHA_WIDTH, height=CAPTCHA_HEIGHT): """ 获取训练图片组 """ batchX = np.zeros([batchCount, width * height]) batchY = np.zeros([batchCount, CAPTCHA_LEN * len(CAPTCHA_LIST)]) for i in range(batchCount): text, image = genCaptchaTextImage() image = convert2Gray(image) # 将图片数组一维化 同时将文本也对应在两个二维组的同一行 batchX[i, :] = image.flatten() / 255 batchY[i, :] = text2Vec(text) return batchX, batchY # print(getNextBatch(batch_count=1))model_train.py 文件,主要是进行模型训练。在该文件中,定义了模型的基本信息,例如该模型是三层卷积神经网络,原始图像大小是 60*160,在第一次卷积后变为 60*160, 第一池化后变为 30*80;第二次卷积后变为 30*80 ,第二次池化后变为 15*40;第三次卷积后变为 15*40 ,第三次池化后变为7*20。经过三次卷积和池化后,原始图片数据变为 7*20 的平面数据,同时项目在进行训练的时候,每隔 100 次进行一次数据测试,计算一次准确度:
# -*- coding:utf-8 -*- import tensorflow.compat.v1 as tf from datetime import datetime from util import getNextBatch from captcha_gen import CAPTCHA_HEIGHT, CAPTCHA_WIDTH, CAPTCHA_LEN, CAPTCHA_LIST tf.compat.v1.disable_eager_execution() variable = lambda shape, alpha=0.01: tf.Variable(alpha * tf.random_normal(shape)) conv2d = lambda x, w: tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') maxPool2x2 = lambda x: tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') optimizeGraph = lambda y, y_conv: tf.train.AdamOptimizer(1e-3).minimize( tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_conv))) hDrop = lambda image, weight, bias, keepProb: tf.nn.dropout( maxPool2x2(tf.nn.relu(conv2d(image, variable(weight, 0.01)) + variable(bias, 0.1))), keepProb) def cnnGraph(x, keepProb, size, captchaList=CAPTCHA_LIST, captchaLen=CAPTCHA_LEN): """ 三层卷积神经网络 """ imageHeight, imageWidth = size xImage = tf.reshape(x, shape=[-1, imageHeight, imageWidth, 1]) hDrop1 = hDrop(xImage, [3, 3, 1, 32], [32], keepProb) hDrop2 = hDrop(hDrop1, [3, 3, 32, 64], [64], keepProb) hDrop3 = hDrop(hDrop2, [3, 3, 64, 64], [64], keepProb) # 全连接层 imageHeight = int(hDrop3.shape[1]) imageWidth = int(hDrop3.shape[2]) wFc = variable([imageHeight * imageWidth * 64, 1024], 0.01) # 上一层有64个神经元 全连接层有1024个神经元 bFc = variable([1024], 0.1) hDrop3Re = tf.reshape(hDrop3, [-1, imageHeight * imageWidth * 64]) hFc = tf.nn.relu(tf.matmul(hDrop3Re, wFc) + bFc) hDropFc = tf.nn.dropout(hFc, keepProb) # 输出层 wOut = variable([1024, len(captchaList) * captchaLen], 0.01) bOut = variable([len(captchaList) * captchaLen], 0.1) yConv = tf.matmul(hDropFc, wOut) + bOut return yConv def accuracyGraph(y, yConv, width=len(CAPTCHA_LIST), height=CAPTCHA_LEN): """ 偏差计算图,正确值和预测值,计算准确度 """ maxPredictIdx = tf.argmax(tf.reshape(yConv, [-1, height, width]), 2) maxLabelIdx = tf.argmax(tf.reshape(y, [-1, height, width]), 2) correct = tf.equal(maxPredictIdx, maxLabelIdx) # 判断是否相等 return tf.reduce_mean(tf.cast(correct, tf.float32)) def train(height=CAPTCHA_HEIGHT, width=CAPTCHA_WIDTH, ySize=len(CAPTCHA_LIST) * CAPTCHA_LEN): """ cnn训练 """ accRate = 0.95 x = tf.placeholder(tf.float32, [None, height * width]) y = tf.placeholder(tf.float32, [None, ySize]) keepProb = tf.placeholder(tf.float32) yConv = cnnGraph(x, keepProb, (height, width)) optimizer = optimizeGraph(y, yConv) accuracy = accuracyGraph(y, yConv) saver = tf.train.Saver() with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 初始化 step = 0 # 步数 while True: batchX, batchY = getNextBatch(64) sess.run(optimizer, feed_dict={x: batchX, y: batchY, keepProb: 0.75}) # 每训练一百次测试一次 if step % 100 == 0: batchXTest, batchYTest = getNextBatch(100) acc = sess.run(accuracy, feed_dict={x: batchXTest, y: batchYTest, keepProb: 1.0}) print(datetime.now().strftime('%c'), ' step:', step, ' accuracy:', acc) # 准确率满足要求,保存模型 if acc > accRate: modelPath = "./model/captcha.model" saver.save(sess, modelPath, global_step=step) accRate += 0.01 if accRate > 0.90: break step = step + 1 train()当完成了这部分之后,我们可以通过本地机器对模型进行训练,为了提升训练速度,我将代码中的 accRate 部分设置为:
if accRate > 0.90: break也就是说,当准确率超过 90% 之后,系统就会自动停止,并且保存模型。
接下来可以进行训练:

训练时间可能会比较长,训练完成之后,可以根据结果绘图,查看随着 Step 的增加,准确率的变化曲线:
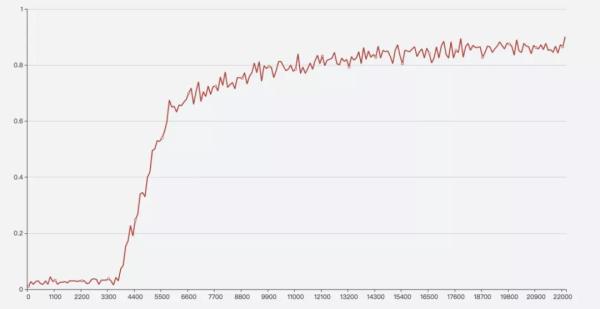
横轴表示训练的 Step,纵轴表示准确率
3. 基于 Serverless 架构的验证码识别
将上面的代码部分进行进一步整合,按照函数计算的规范进行编码:
# -*- coding:utf-8 -*- # 核心后端服务 import base64 import json import uuid import tensorflow as tf import random import numpy as np from PIL import Image from captcha.image import ImageCaptcha # Response class Response: def __init__(self, start_response, response, errorCode=None): self.start = start_response responseBody = { 'Error': {"Code": errorCode, "Message": response}, } if errorCode else { 'Response': response } # 默认增加uuid,便于后期定位 responseBody['ResponseId'] = str(uuid.uuid1()) print("Response: ", json.dumps(responseBody)) self.response = json.dumps(responseBody) def __iter__(self): status = '200' response_headers = [('Content-type', 'application/json; charset=UTF-8')] self.start(status, response_headers) yield self.response.encode("utf-8") CAPTCHA_LIST = [eve for eve in "0123456789abcdefghijklmnopqrsruvwxyzABCDEFGHIJKLMOPQRSTUVWXYZ"] CAPTCHA_LEN = 4 # 验证码长度 CAPTCHA_HEIGHT = 60 # 验证码高度 CAPTCHA_WIDTH = 160 # 验证码宽度 # 随机字符串 randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num)) randomCaptchaText = lambda char=CAPTCHA_LIST, size=CAPTCHA_LEN: "".join([random.choice(char) for _ in range(size)]) # 图片转为黑白,3维转1维 convert2Gray = lambda img: np.mean(img, -1) if len(img.shape) > 2 else img # 验证码向量转为文本 vec2Text = lambda vec, captcha_list=CAPTCHA_LIST: ''.join([captcha_list[int(v)] for v in vec]) variable = lambda shape, alpha=0.01: tf.Variable(alpha * tf.random_normal(shape)) conv2d = lambda x, w: tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') maxPool2x2 = lambda x: tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') optimizeGraph = lambda y, y_conv: tf.train.AdamOptimizer(1e-3).minimize( tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_conv))) hDrop = lambda image, weight, bias, keepProb: tf.nn.dropout( maxPool2x2(tf.nn.relu(conv2d(image, variable(weight, 0.01)) + variable(bias, 0.1))), keepProb) def genCaptchaTextImage(width=CAPTCHA_WIDTH, height=CAPTCHA_HEIGHT, save=None): image = ImageCaptcha(width=width, height=height) captchaText = randomCaptchaText() if save: image.write(captchaText, save) return captchaText, np.array(Image.open(image.generate(captchaText))) def text2Vec(text, captcha_len=CAPTCHA_LEN, captcha_list=CAPTCHA_LIST): """ 验证码文本转为向量 """ vector = np.zeros(captcha_len * len(captcha_list)) for i in range(len(text)): vector[captcha_list.index(text[i]) + i * len(captcha_list)] = 1 return vector def getNextBatch(batch_count=60, width=CAPTCHA_WIDTH, height=CAPTCHA_HEIGHT): """ 获取训练图片组 """ batch_x = np.zeros([batch_count, width * height]) batch_y = np.zeros([batch_count, CAPTCHA_LEN * len(CAPTCHA_LIST)]) for i in range(batch_count): text, image = genCaptchaTextImage() image = convert2Gray(image) # 将图片数组一维化 同时将文本也对应在两个二维组的同一行 batch_x[i, :] = image.flatten() / 255 batch_y[i, :] = text2Vec(text) return batch_x, batch_y def cnnGraph(x, keepProb, size, captchaList=CAPTCHA_LIST, captchaLen=CAPTCHA_LEN): """ 三层卷积神经网络 """ imageHeight, imageWidth = size xImage = tf.reshape(x, shape=[-1, imageHeight, imageWidth, 1]) hDrop1 = hDrop(xImage, [3, 3, 1, 32], [32], keepProb) hDrop2 = hDrop(hDrop1, [3, 3, 32, 64], [64], keepProb) hDrop3 = hDrop(hDrop2, [3, 3, 64, 64], [64], keepProb) # 全连接层 imageHeight = int(hDrop3.shape[1]) imageWidth = int(hDrop3.shape[2]) wFc = variable([imageHeight * imageWidth * 64, 1024], 0.01) # 上一层有64个神经元 全连接层有1024个神经元 bFc = variable([1024], 0.1) hDrop3Re = tf.reshape(hDrop3, [-1, imageHeight * imageWidth * 64]) hFc = tf.nn.relu(tf.matmul(hDrop3Re, wFc) + bFc) hDropFc = tf.nn.dropout(hFc, keepProb) # 输出层 wOut = variable([1024, len(captchaList) * captchaLen], 0.01) bOut = variable([len(captchaList) * captchaLen], 0.1) yConv = tf.matmul(hDropFc, wOut) + bOut return yConv def captcha2Text(image_list): """ 验证码图片转化为文本 """ with tf.Session() as sess: saver.restore(sess, tf.train.latest_checkpoint('model/')) predict = tf.argmax(tf.reshape(yConv, [-1, CAPTCHA_LEN, len(CAPTCHA_LIST)]), 2) vector_list = sess.run(predict, feed_dict={x: image_list, keepProb: 1}) vector_list = vector_list.tolist() text_list = [vec2Text(vector) for vector in vector_list] return text_list x = tf.placeholder(tf.float32, [None, CAPTCHA_HEIGHT * CAPTCHA_WIDTH]) keepProb = tf.placeholder(tf.float32) yConv = cnnGraph(x, keepProb, (CAPTCHA_HEIGHT, CAPTCHA_WIDTH)) saver = tf.train.Saver() def handler(environ, start_response): try: request_body_size = int(environ.get('CONTENT_LENGTH', 0)) except (ValueError): request_body_size = 0 requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8")) imageName = randomStr(10) imagePath = "/tmp/" + imageName print("requestBody: ", requestBody) reqType = requestBody.get("type", None) if reqType == "get_captcha": genCaptchaTextImage(save=imagePath) with open(imagePath, 'rb') as f: data = base64.b64encode(f.read()).decode() return Response(start_response, {'image': data}) if reqType == "get_text": # 图片获取 print("Get pucture") imageData = base64.b64decode(requestBody["image"]) with open(imagePath, 'wb') as f: f.write(imageData) # 开始预测 img = Image.open(imageName) img = img.resize((160, 60), Image.ANTIALIAS) img = img.convert("RGB") img = np.asarray(img) image = convert2Gray(img) image = image.flatten() / 255 return Response(start_response, {'result': captcha2Text([image])})在这个函数部分,主要包括两个接口:
获取验证码:用户测试使用,生成验证码
获取验证码识别结果:用户识别使用,识别验证码
这部分代码,所需要的依赖内容如下:
tensorflow==1.13.1 numpy==1.19.4 scipy==1.5.4 pillow==8.0.1 captcha==0.3另外,为了更加简单的来体验,提供测试页面,测试页面的后台服务使用 Python Web Bottle 框架:
# -*- coding:utf-8 -*- import os import json from bottle import route, run, static_file, request import urllib.request url = "http://" + os.environ.get("url") @route('/') def index(): return static_file("index.html", root='html/') @route('/get_captcha') def getCaptcha(): data = json.dumps({"type": "get_captcha"}).encode("utf-8") reqAttr = urllib.request.Request(data=data, url=url) return urllib.request.urlopen(reqAttr).read().decode("utf-8") @route('/get_captcha_result', method='POST') def getCaptcha(): data = json.dumps({"type": "get_text", "image": json.loads(request.body.read().decode("utf-8"))["image"]}).encode( "utf-8") reqAttr = urllib.request.Request(data=data, url=url) return urllib.request.urlopen(reqAttr).read().decode("utf-8") run(host='0.0.0.0', debug=False, port=9000)该后端服务,所需依赖:
bottle==0.12.19前端页面代码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>验证码识别测试系统</title> <link href="https://www.bootcss.com/p/layoutit/css/bootstrap-combined.min.css" rel="stylesheet"> <script> var image = undefined function getCaptcha() { const xmlhttp = window.XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHTTP"); xmlhttp.open("GET", '/get_captcha', false); xmlhttp.onreadystatechange = function () { if (xmlhttp.readyState == 4 && xmlhttp.status == 200) { image = JSON.parse(xmlhttp.responseText).Response.image document.getElementById("captcha").src = "data:image/png;base64," + image document.getElementById("getResult").style.visibility = 'visible' } } xmlhttp.setRequestHeader("Content-type", "application/json"); xmlhttp.send(); } function getCaptchaResult() { const xmlhttp = window.XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHTTP"); xmlhttp.open("POST", '/get_captcha_result', false); xmlhttp.onreadystatechange = function () { if (xmlhttp.readyState == 4 && xmlhttp.status == 200) { document.getElementById("result").innerText = "识别结果:" + JSON.parse(xmlhttp.responseText).Response.result } } xmlhttp.setRequestHeader("Content-type", "application/json"); xmlhttp.send(JSON.stringify({"image": image})); } </script> </head> <body> <div class="container-fluid" style="margin-top: 10px"> <div class="row-fluid"> <div class="span12"> <center> <h4> 验证码识别测试系统 </h4> </center> </div> </div> <div class="row-fluid"> <div class="span2"> </div> <div class="span8"> <center> <img src="" id="captcha"/> <br><br> <p id="result"></p> </center> <fieldset> <legend>操作:</legend> <button class="btn" onclick="getCaptcha()">获取验证码</button> <button class="btn" onclick="getCaptchaResult()" id="getResult" style="visibility: hidden">识别验证码 </button> </fieldset> </div> <div class="span2"> </div> </div> </div> </body> </html>准备好代码之后,开始编写部署文件:
Global: Service: Name: ServerlessBook Description: Serverless图书案例 Log: Auto Nas: Auto ServerlessBookCaptchaDemo: Component: fc Provider: alibaba Access: release Extends: deploy: - Hook: s install docker Path: ./ Pre: true Properties: Region: cn-beijing Service: ${Global.Service} Function: Name: serverless_captcha Description: 验证码识别 CodeUri: Src: ./src/backend Excludes: - src/backend/.fun - src/backend/model Handler: index.handler Environment: - Key: PYTHONUSERBASE Value: /mnt/auto/.fun/python MemorySize: 3072 Runtime: python3 Timeout: 60 Triggers: - Name: ImageAI Type: HTTP Parameters: AuthType: ANONYMOUS Methods: - GET - POST - PUT Domains: - Domain: Auto ServerlessBookCaptchaWebsiteDemo: Component: bottle Provider: alibaba Access: release Extends: deploy: - Hook: pip3 install -r requirements.txt -t ./ Path: ./src/website Pre: true Properties: Region: cn-beijing CodeUri: ./src/website App: index.py Environment: - Key: url Value: ${ServerlessBookCaptchaDemo.Output.Triggers[0].Domains[0]} Detail: Service: ${Global.Service} Function: Name: serverless_captcha_website整体的目录结构:
| - src # 项目目录 | | - backend # 项目后端,核心接口 | | - index.py # 后端核心代码 | | - requirements.txt # 后端核心代码依赖 | | - website # 项目前端,便于测试使用 | | - html # 项目前端页面 | | - index.html # 项目前端页面 | | - index.py # 项目前端的后台服务(bottle框架) | | - requirements.txt # 项目前端的后台服务依赖完成之后,我们可以在项目目录下,进行项目的部署:
s deploy
部署完成之后,打开返回的页面地址:

点击获取验证码,即可在线生成一个验证码:

此时点击识别验证码,即可进行验证码识别:

由于模型在训练的时候,填写的目标准确率是 90%,所以可以认为在海量同类型验证码测试之后,整体的准确率在 90% 左右。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/ltHLbC_ZlpfCpwgmRxU35g



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



