这篇文章跟大家分析一下“如何进行编译服务器性能优化实战”。内容详细易懂,对“如何进行编译服务器性能优化实战”感兴趣的朋友可以跟着小编的思路慢慢深入来阅读一下,希望阅读后能够对大家有所帮助。下面跟着小编一起深入学习“如何进行编译服务器性能优化实战”的知识吧。
背景
随着企业SDK在多条产品线的广泛使用,随着SDK开发人员的增长,每日往SDK提交的补丁量与日俱增,自动化提交代码检查的压力已经明显超过了通用服务器的负载。于是向公司申请了一台专用服务器,用于SDK构建检查。
$ cat /proc/cpuinfo | grep ^proccessor | wc -l 48 $ free -h total used free shared buffers cached Mem: 47G 45G 1.6G 20M 7.7G 25G -/+ buffers/cache: 12G 35G Swap: 0B 0B 0B $ df 文件系统 容量 已用 可用 已用% 挂载点 ...... /dev/sda1 98G 14G 81G 15% / /dev/vda1 2.9T 1.8T 986G 65% /home
这是KVM虚拟的服务器,提供了CPU 48线程,实际可用47G内存,磁盘空间约达到3TB。
由于独享服务器所有资源,设置了十来个worker并行编译,从提交补丁到发送编译结果的速度杠杠的。但是在补丁提交非常多的时候,速度瞬间就慢了下去,一次提交触发的编译甚至要1个多小时。通过top看到CPU负载并不高,难道是IO瓶颈?找IT要到了root权限,干起来!
由于认知的局限性,如有考虑不周的地方,希望一起交流学习
整体认识IO栈
如果有完整的IO栈的认识,无疑有助于更细腻的优化IO。循着IO栈从上往下的顺序,我们逐层分析可优化的地方。
在网上有Linux完整的IO栈结构图,但太过完整反而不容易理解。按我的认识,简化过后的IO栈应该是下图的模样。
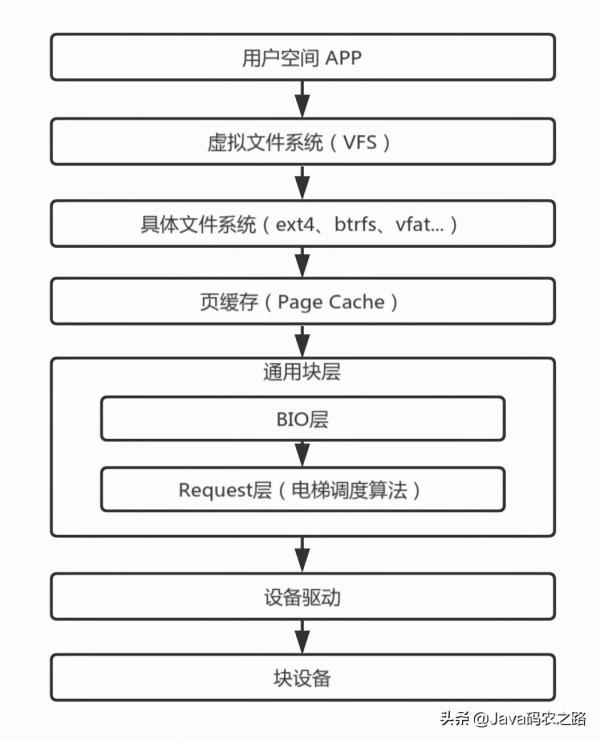
用户空间:除了用户自己的APP之外,也隐含了所有的库,例如常见的C库。我们常用的IO函数,例如open()/read()/write()是系统调用,由内核直接提供功能实现,而fopen()/fread()/fwrite()则是C库实现的函数,通过封装系统调用实现更高级的功能。
虚拟文件系统:屏蔽具体文件系统的差异,向用户空间提供统一的入口。具体的文件系统通过register_filesystem()向虚拟文件系统注册挂载钩子,在用户挂载具体的文件系统时,通过回调挂载钩子实现文件系统的初始化。虚拟文件系统提供了inode来记录文件的元数据,dentry记录了目录项。对用户空间,虚拟文件系统注册了系统调用,例如SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)注册了open()的系统调用。
具体的文件系统:文件系统要实现存储空间的管理,换句话说,其规划了哪些空间存储了哪些文件的数据,就像一个个收纳盒,A文件保存在这个块,B文件则放在哪个块。不同的管理策略以及其提供的不同功能,造就了各式各样的文件系统。除了类似于vfat、ext4、btrfs等常见的块设备文件系统之外,还有sysfs、procfs、pstorefs、tempfs等构建在内存上的文件系统,也有yaffs,ubifs等构建在Flash上的文件系统。
页缓存:可以简单理解为一片存储着磁盘数据的内存,不过其内部是以页为管理单元,常见的页大小是4K。这片内存的大小不是固定的,每有一笔新的数据,则申请一个新的内存页。由于内存的性能远大于磁盘,为了提高IO性能,我们就可以把IO数据缓存在内存,这样就可以在内存中获取要的数据,不需要经过磁盘读写的漫长的等待。申请内存来缓存数据简单,如何管理所有的页缓存以及如何及时回收缓存页才是精髓。
通用块层:通用块层也可以细分为bio层和request层。页缓存以页为管理单位,而bio则记录了磁盘块与页之间的关系,一个磁盘块可以关联到多个不同的内存页中,通过submit_bio()提交bio到request层。一个request可以理解为多个bio的集合,把多个地址连续的bio合并成一个request。多个request经过IO调度算法的合并和排序,有序地往下层提交IO请求。
设备驱动与块设备:不同块设备有不同的使用协议,而特定的设备驱动则是实现了特定设备需要的协议以正常驱使设备。对块设备而言,块设备驱动需要把request解析成一个个设备操作指令,在协议的规范下与块设备通信来交换数据。
形象点来说,发起一次IO读请求的过程是怎么样的呢?
用户空间通过虚拟文件系统提供的统一的IO系统调用,从用户态切到内核态。虚拟文件系统通过调用具体文件系统注册的回调,把需求传递到具体的文件系统中。紧接着具体的文件系统根据自己的管理逻辑,换算到具体的磁盘块地址,从页缓存寻找块设备的缓存数据。读操作一般是同步的,如果在页缓存没有缓存数据,则向通用块层发起一次磁盘读。通用块层合并和排序所有进程产生的的IO请求,经过设备驱动从块设备读取真正的数据。最后是逐层返回。读取的数据既拷贝到用户空间的buffer中,也会在页缓存中保留一份副本,以便下次快速访问。
如果 页缓存没命中,同步都会一路通到 块设备,而对于 异步写,则是把数据放到 页缓存后返回,由内核回刷进程在合适时候回刷到 块设备。
根据这个流程,考虑到我没要到KVM host的权限,我只能着手从Guest端的IO栈做优化,具体包括以下几个方面:
交换分区(swap)
文件系统(ext4)
页缓存(Page Cache)
Request层(IO调度算法)
由于源码以及编译的临时文件都不大但数量极其多,对随机IO的要求非常高。要提高随机IO的性能,在不改变硬件的情况下,需要缓存更多数据,以实现合并更多的IO请求。
咨询ITer得知,服务器都有备用电源,能确保不会掉电停机。出于这样的情况,我们可以尽可能优化速度,而不用担心掉电导致数据丢失问题。
总的来说,优化的核心思路是尽可能多的使用内存缓存数据,尽可能减小不必要的开销,例如文件系统为了保证数据一致性使用日志造成的开销。
交换分区
交换分区的存在,可以让内核在内存压力大时,把内核认为一些不常用的内存置换到交换分区,以此腾出更多的内存给系统。在物理内存容量不足且运行吃内存的应用时,交换分区的作用效果是非常明显的。
然而本次优化的服务器反而不应该使用交换分区。为什么呢?服务器总内存达到47G,且服务器除了Jenkins slave进程外没有大量吃内存的进程。从内存的使用情况来看,绝大部分内存都是被cache/buffer占用,是可丢弃的文件缓存,因此内存是充足的,不需要通过交换分区扩大虚拟内存。
# free -h total used free shared buffers cached Mem: 47G 45G 1.6G 21M 18G 16G -/+ buffers/cache: 10G 36G
交换分区也是磁盘的空间,从交换分区置入置出数据可也是要占用IO资源的,与本次IO优化目的相悖,因此在此服务器中,需要取消swap分区。
查看系统状态发现,此服务器并没使能swap。
# cat /proc/swaps Filename Type Size Used Priority #
文件系统
用户发起一次读写,经过了虚拟文件系统(VFS)后,交给了实际的文件系统。
首先查询分区挂载情况:
# mount ... /dev/sda1 on on / type ext4 (rw) /dev/vda1 on /home type ext4 (rw) ...
此服务器主要有两个块设备,分别是 sda和 vda。sda 是常见的 SCSI/IDE 设备,我们个人PC上如果使用的机械硬盘,往往就会是 sda 设备节点。vda 是 virtio 磁盘设备。由于本服务器是 KVM 提供的虚拟机,不管是 sda 还是 vda,其实都是虚拟设备,差别在于前者是完全虚拟化的块设备,后者是半虚拟化的块设备。从网上找到的资料来看,使用半虚拟化的设备,可以实现Host与Guest更高效的协作,从而实现更高的性能。在此例子中,sda 作为根文件系统使用,vda 则是用于存储用户数据,在编译时,主要看的是 vda 分区的IO情况。
vda 使用 ext4 文件系统。ext4 是目前常见的Linux上使用的稳定的文件系统,查看其超级块信息:
# dumpe2fs /dev/vda1 ... Filesystem features: has_journal dir_index ... ... Inode count: 196608000 Block count: 786431991 Free inodes: 145220571 Block size: 4096 ...
我猜测ITer使用的默认参数格式化的分区,为其分配了块大小为4K,inode数量达到19660万个且使能了日志。
块大小设为4K无可厚非,适用于当前源文件偏小的情况,也没必要为了更紧凑的空间降低块大小。空闲 inode 达到 14522万,空闲占比达到 73.86%。当前 74% 的空间使用率,inode只使用了26.14%。一个inode占256B,那么10000万个inode占用23.84G。inode 实在太多了,造成大量的空间浪费。可惜,inode数量在格式化时指定,后期无法修改,当前也不能简单粗暴地重新格式化。
我们能做什么呢?我们可以从日志和挂载参数着手优化
日志是为了保证掉电时文件系统的一致性,(ordered日志模式下)通过把元数据写入到日志块,在写入数据后再修改元数据。如果此时掉电,通过日志记录可以回滚文件系统到上一个一致性的状态,即保证元数据与数据是匹配的。然而上文有说,此服务器有备用电源,不需要担心掉电,因此完全可以把日志取消掉。
# tune2fs -O ^has_journal /dev/vda1 tune2fs 1.42.9 (4-Feb-2014) The has_journal feature may only be cleared when the filesystem is unmounted or mounted read-only.
可惜失败了。由于时刻有任务在执行,不太好直接umount或者-o remount,ro,无法在挂载时取消日志。既然取消不了,咱们就让日志减少损耗,就需要修改挂载参数了。
ext4挂载参数: data
ext4有3种日志模式,分别是ordered,writeback,journal。他们的差别网上有很多资料,我简单介绍下:
jorunal:把元数据与数据一并写入到日志块。性能差不多折半,因为数据写了两次,但最安全
writeback: 把元数据写入日志块,数据不写入日志块,但不保证数据先落盘。性能最高,但由于不保证元数据与数据的顺序,也是掉电最不安全的
ordered:与writeback相似,但会保证数据先落盘,再是元数据。这种性能以保证足够的安全,这是大多数PC上推荐的默认的模式
在不需要担心掉电的服务器环境,我们完全可以使用writeback的日志模式,以获取最高的性能。
# mount -o remount,rw,data=writeback /home mount: /home not mounted or bad option # dmesg [235737.532630] EXT4-fs (vda1): Cannot change data mode on remount
沮丧,又是不能动态改,干脆写入到/etc/config,只能寄希望于下次重启了。
# cat /etc/fstab UUID=... /home ext4 defaults,rw,data=writeback...
ext4挂载参数:noatime
Linux上对每个文件都记录了3个时间戳
时间戳全称含义atimeaccess time访问时间,就是最近一次读的时间mtimedata modified time数据修改时间,就是内容最后一次改动时间ctimestatus change time文件状态(元数据)的改变时间,比如权限,所有者等
我们编译执行的Make可以根据修改时间来判断是否要重新编译,而atime记录的访问时间其实在很多场景下都是多余的。所以,noatime应运而生。不记录atime可以大量减少读造成的元数据写入量,而元数据的写入往往产生大量的随机IO。
# mount -o ...noatime... /home
ext4挂载参数:nobarrier
这主要是决定在日志代码中是否使用写屏障(write barrier),对日志提交进行正确的磁盘排序,使易失性磁盘写缓存可以安全使用,但会带来一些性能损失。从功能来看,跟writeback和ordered日志模式非常相似。没研究过这方面的源码,说不定就是一回事。不管怎么样,禁用写屏障毫无疑问能提高写性能。
# mount -o ...nobarrier... /home
ext4挂载参数:delalloc
delalloc是 delayed allocation 的缩写,如果使能,则ext4会延缓申请数据块直至超时。为什么要延缓申请呢?在inode中采用多级索引的方式记录了文件数据所在的数据块编号,如果出现大文件,则会采用 extent 区段的形式,分配一片连续的块,inode中只需要记录开始块号与长度即可,不需要索引记录所有的块。这除了减轻inode的压力之外,连续的块可以把随机写改为顺序写,加快写性能。连续的块也符合 局部性原理,在预读时可以加大命中概率,进而加快读性能。
# mount -o ...delalloc... /home
ext4挂载参数:inode_readahead_blks
ext4从inode表中预读的indoe block最大数量。访问文件必须经过inode获取文件信息、数据块地址。如果需要访问的inode都在内存中命中,就不需要从磁盘中读取,毫无疑问能提高读性能。其默认值是32,表示最大预读 32 × block_size 即 64K 的inode数据,在内存充足的情况下,我们毫无疑问可以进一步扩大,让其预读更多。
# mount -o ...inode_readahead_blks=4096... /home
ext4挂载参数:journal_async_commit
commit块可以不等待descriptor块,直接往磁盘写。这会加快日志的速度。
# mount -o ...journal_async_commit... /home
ext4挂载参数:commit
ext4一次缓存多少秒的数据。默认值是5,表示如果此时掉电,你最多丢失5s的数据量。设置更大的数据,就可以缓存更多的数据,相对的掉电也有可能丢失更多的数据。在此服务器不怕掉电的情况,把数值加大可以提高性能。
# mount -o ...commit=1000... /home
ext4挂载参数汇总
最终在不能umount情况下,我执行的调整挂载参数的命令为:
mount -o remount,rw,noatime,nobarrier,delalloc,inode_readahead_blks=4096,journal_async_commit,commit=1800 /home
此外,在/etc/fstab中也对应修改过来,避免重启后优化丢失
# cat /etc/fstab UUID=... /home ext4 defaults,rw,noatime,nobarrier,delalloc,inode_readahead_blks=4096,journal_async_commit,commit=1800,data=writeback 0 0 ...
页缓存
页缓存在FS与通用块层之间,其实也可以归到通用块层中。为了提高IO性能,减少真实的从磁盘读写的次数,Linux内核设计了一层内存缓存,把磁盘数据缓存到内存中。由于内存以4K大小的 页 为单位管理,磁盘数据也以页为单位缓存,因此也称为页缓存。在每个缓存页中,都包含了部分磁盘信息的副本。
如果因为之前读写过或者被预读加载进来,要读取数据刚好在缓存中命中,就可以直接从缓存中读取,不需要深入到磁盘。不管是同步写还是异步写,都会把数据copy到缓存,差别在于异步写只是copy且把页标识脏后直接返回,而同步写还会调用类似fsync()的操作等待回写,详细可以看内核函数generic_file_write_iter()。异步写产生的脏数据会在“合适”的时候被内核工作队列writeback进程回刷。
那么,什么时候是合适的时候呢?最多能缓存多少数据呢?对此次优化的服务器而言,毫无疑问延迟回刷可以在频繁的删改文件中减少写磁盘次数,缓存更多的数据可以更容易合并随机IO请求,有助于提升性能。
在/proc/sys/vm中有以下文件与回刷脏数据密切相关:
配置文件功能默认值dirty_background_ratio触发回刷的脏数据占可用内存的百分比0dirty_background_bytes触发回刷的脏数据量10dirty_bytes触发同步写的脏数据量0dirty_ratio触发同步写的脏数据占可用内存的百分比20dirty_expire_centisecs脏数据超时回刷时间(单位:1/100s)3000dirty_writeback_centisecs回刷进程定时唤醒时间(单位:1/100s)500
对上述的配置文件,有几点要补充的:
XXX_ratio 和 XXX_bytes 是同一个配置属性的不同计算方法,优先级 XXX_bytes > XXX_ratio
可用内存并不是系统所有内存,而是free pages + reclaimable pages
脏数据超时表示内存中数据标识脏一定时间后,下次回刷进程工作时就必须回刷
回刷进程既会定时唤醒,也会在脏数据过多时被动唤醒。
dirty_background_XXX与dirty_XXX的差别在于前者只是唤醒回刷进程,此时应用依然可以异步写数据到Cache,当脏数据比例继续增加,触发dirty_XXX的条件,不再支持应用异步写。
更完整的功能介绍,可以看内核文档Documentation/sysctl/vm.txt,也可看我写的一篇总结博客《Linux 脏数据回刷参数与调优》
对当前的案例而言,我的配置如下:
dirty_background_ratio = 60 dirty_ratio = 80 dirty_writeback_centisecs = 6000 dirty_expire_centisecs = 12000
这样的配置有以下特点:
当脏数据达到可用内存的60%时唤醒回刷进程
当脏数据达到可用内存的80%时,应用每一笔数据都必须同步等待
每隔60s唤醒一次回刷进程
内存中脏数据存在时间超过120s则在下一次唤醒时回刷
当然,为了避免重启后丢失优化结果,我们在/etc/sysctl.conf中写入:
# cat /etc/sysctl.conf ... vm.dirty_background_ratio = 60 vm.dirty_ratio = 80 vm.dirty_expire_centisecs = 12000 vm.dirty_writeback_centisecs = 6000
Request层
在异步写的场景中,当脏页达到一定比例,就需要通过通用块层把页缓存里的数据回刷到磁盘中。bio层记录了磁盘块与内存页之间的关系,在request层把多个物理块连续的bio合并成一个request,然后根据特定的IO调度算法对系统内所有进程产生的IO请求进行合并、排序。那么都有什么IO调度算法呢?
网上检索IO调度算法,大量的资料都在描述Deadline,CFQ,NOOP这3种调度算法,却没有备注这只是单队列上适用的调度算法。在最新的代码上(我分析的代码版本为 5.7.0),已经完全切换到multi-queue的新架构上了,支持的IO调度算法就成了mq-deadline,BFQ,Kyber,none。
关于不同IO调度算法的优劣,网上有非常多的资料,本文不再累述。
在《Linux-storage-stack-diagram_v4.10》 对 Block Layer 的描述可以形象阐述单队列与多队列的差异。
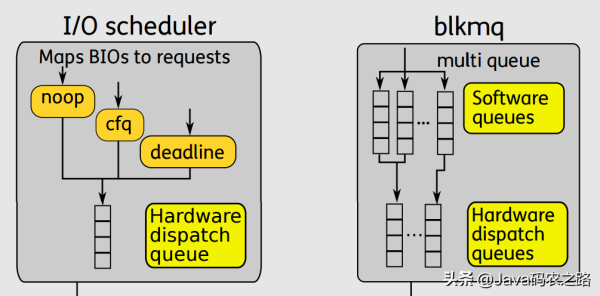

单队列的架构,一个块设备只有一个全局队列,所有请求都要往这个队列里面塞,这在多核高并发的情况下,尤其像服务器动则32个核的情况下,为了保证互斥而加的锁就导致了非常大的开销。此外,如果磁盘支持多队列并行处理,单队列的模型不能充分发挥其优越的性能。
多队列的架构下,创建了Software queues和Hardware dispatch queues两级队列。Software queues是每个CPU core一个队列,且在其中实现IO调度。由于每个CPU一个单独队列,因此不存在锁竞争问题。Hardware Dispatch Queues的数量跟硬件情况有关,每个磁盘一个队列,如果磁盘支持并行N个队列,则也会创建N个队列。在IO请求从Software queues提交到Hardware Dispatch Queues的过程中是需要加锁的。理论上,多队列的架构的效率最差也只是跟单队列架构持平。
咱们回到当前待优化的服务器,当前使用的是什么IO调度器呢?
# cat /sys/block/vda/queue/scheduler none # cat /sys/block/sda/queue/scheduler noop [deadline] cfq
这服务器的内核版本是
# uname -r 3.13.0-170-generic
查看Linux内核git提交记录,发现在 3.13.0 的内核版本上还没有实现适用于多队列的IO调度算法,且此时还没完全切到多队列架构,因此使用单队列的 sda 设备依然存在传统的noop,deadline和cfq调度算法,而使用多队列的 vda 设备(virtio)的IO调度算法只有none。为了使用mq-deadline调度算法把内核升级的风险似乎很大。因此IO调度算法方面没太多可优化的。
但Request层优化只能这样了?既然IO调度算法无法优化,我们是否可以修改queue相关的参数?例如加大Request队列的长度,加大预读的数据量。
在/sys/block/vda/queue中有两个可写的文件nr_requests和read_ahead_kb,前者是配置块层最大可以申请的request数量,后者是预读最大的数据量。默认情况下,
nr_request = 128 read_ahead_kb = 128
我扩大为
nr_request = 1024 read_ahead_kb = 512
优化效果
优化后,在满负荷的情况下,查看内存使用情况:
# cat /proc/meminfo MemTotal: 49459060 kB MemFree: 1233512 kB Buffers: 12643752 kB Cached: 21447280 kB Active: 19860928 kB Inactive: 16930904 kB Active(anon): 2704008 kB Inactive(anon): 19004 kB Active(file): 17156920 kB Inactive(file): 16911900 kB ... Dirty: 7437540 kB Writeback: 1456 kB
可以看到,文件相关内存(Active(file) + Inactive(file) )达到了32.49GB,脏数据达到7.09GB。脏数据量比预期要少,远没达到dirty_background_ratio和dirty_ratio设置的阈值。因此,如果需要缓存更多的写数据,只能延长定时唤醒回刷的时间dirty_writeback_centisecs。这个服务器主要用于编译SDK,读的需求远大于写,因此缓存更多的脏数据没太大意义。
我还发现Buffers达到了12G,应该是ext4的inode占用了大量的缓存。如上分析的,此服务器的ext4有大量富余的inode,在缓存的元数据里,无效的inode不知道占比多少。减少inode数量,提高inode利用率,说不定可以提高inode预读的命中率。
优化后,一次使能8个SDK并行编译,走完一次完整的编译流程(包括更新代码,抓取提交,编译内核,编译SDK等),在没有进入错误处理流程的情况下,用时大概13分钟。
关于如何进行编译服务器性能优化实战就分享到这里啦,希望上述内容能够让大家有所提升。如果想要学习更多知识,请大家多多留意小编的更新。谢谢大家关注一下亿速云网站!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





