本篇内容介绍了“如何理解Oracle归档日志比联机重做日志小很多的情况”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
1:检查参数ARCHIVE_LAG_TARGET
ARCHIVE_LAG_TARGET参数可以设置一个时间,通过时间限制,指定数据库强制进行Log Switch进行归档。如果这个参数设置过小,有可能导致联机重做日志还没有写满就切换了,这样就有可能导致归档日志远小于联机重做日志(redo log)。
SQL> show parameter archive_lag_target; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ archive_lag_target integer 0 SQL>如果参数archive_lag_target为0,那么可以排除这方面的因素。
2:检查是否存在人为切换redo log的可能性。
一些命令可以引起重做日志的切换,具体请见下面
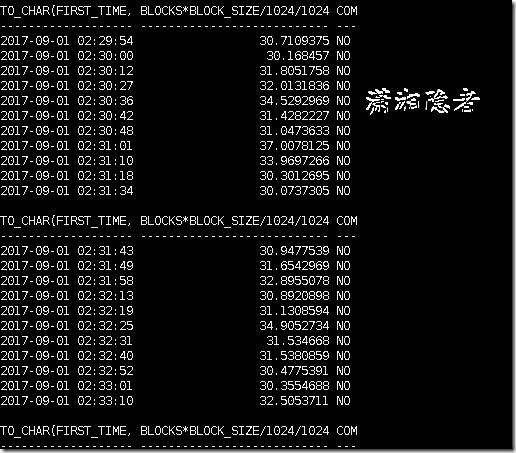
SQL> alter system archive log current; #归档命令也会造成日志切换 SQL> alter system switch logfile; #直接切换日志组 RMAN> backup archivelog all; RMAN> backup database plus archivelog; SELECT TO_CHAR(FIRST_TIME, 'YYYY-MM-DD HH24:MI:SS'), BLOCKS * BLOCK_SIZE / 1024 / 1024, COMPRESSED FROM V$ARCHIVED_LOG;如下案例的截图如下所示,从截图看归档日志的大小在31M左右徘徊。另外,可以看到没有启用归档日志压缩选项(其实ORACLE不支持归档日志压缩,这个后面说明)。从归档日志大小的规律可以看出,这个不是某个重做日志切换命令引起的。
3:一些Bug引起的,如下metalink文档所示:
BUG 9272059 - REDO LOG SWITCH AT 1/8 OF SIZE DUE TO CMT CPU'S BUG 10354739 - REDOLOGSIZE NOT COMPLETLY USED BUG 12317474 - FREQUENT REDO LOG SWITCHES GENERATING SMALL SIZED ARCHIVELOGS BUG 5450861 - ARCHIVE LOGS ARE GENERATED WITH A SMALLER SIZE THAN THE REDO LOG FILES BUG 7016254 - DECREASE CONTROL FILE ENQUEUE WAIT AT LOG SWITCH4:跟CPU个数CPU_COUNT以及log_buffer、redo log size有关。
归档日志的大小是真实的在线日志文件的使用量,也就是在线日志文件切换前其中写入的内容的大小。为了更好的并行,减少冲突,提高并发,减少redo allocation latch的等待,ORACLE会将redo buffer分成若干小的buffer,每份小的buffer叫strand。按每16个CPU分一股(strand),每一股独立从redo buffer以及redo log中分配一块空间,当这一块redo buffer用完,会写入redo log并且继续从redo log中分配相同大小的空间,如果无法分配空闲空间就会进行日志切换,而不管其他strand是否写完。
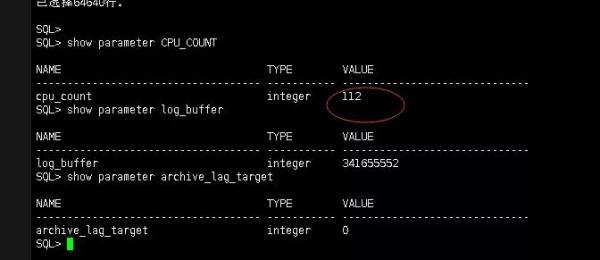
如上所示CPU_COUNT为112,那么 112/16=7 ,那么redo buffer和 redo log 都可以分成7部分
SQL> select 112.0/16 from dual; 112.0/16 ---------- 7 SQL> select 341655552/1024/1024/7 from dual; --log buffer 341655552/1024/1024/7 --------------------- 46.546875 SQL> select 200/7 from dual; --redo log size 200/7 ---------- 28.5714286 SQL>当log buffer的大小是325.828125M(341655552),分成7股(strand)的话,每个strand还是325.828125M/7=46.546875M。而redo log的大小是200M的时候,redo log中的空间会按strand的个数平均分配,也就是每块200M/7=28.5714286M。
这样,当每个strand中的内容写到28M多左右的时候,就会日志切换,而不是46M。相当于log buffer中的一部分空间被浪费了。所以你看到的归档日志基本是30M左右大小(其中一股(strand)28.6再加上其它各股也有部分内容写入,所以归档日志的大小就是一个波动的范围)
其它各个特殊场景分析,可以参考“归档日志的大小比在线日志的大小小很多[1]”这篇文章的介绍。当然这篇文章分析过程还忽略了其它各股其实也是有部分数据的。这个需要特别注意。
如果你对这个机制不是很清楚,上面链接的这篇博客已经不可访问了,下面是我摘抄的部分内容到此,方便大家深入理解:
比如CPU的个数是64个,则会有64/16=4个strand
例1):当log buffer的大小和redo log file的大小都是256M的时候,则每个strand都是256M/4=64M。每一个redo log file被启用时,会预先将redo log file中的大小分配出4个64M与log buffer对应,如图:
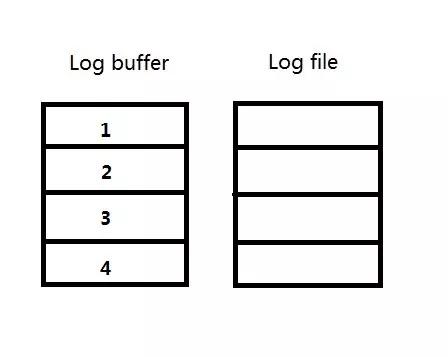
因为log buffer的大小和redo log file的大小都是256M,则redo log file没有剩余的未分配的空间了。
每个进程产生的redo会分配到log buffer上的1,2,3,4其中的某一个strand上,单个进程只能对应一个strand, 这样当数据库中只有某些进程(比如极端的情况,只有某一个进程)产生的redo很多的时候,其中一个strand会快速写满,比如图中的strand 1:
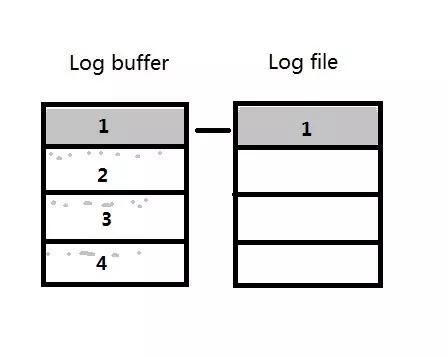
写满之后LGWR会将log buffer中strand 1的内容写入到redo log file中,并且试图从redo log file中分配一个新的64M空间,发现没有了,则将所有strand中的内容写入日志,并作日志切换。
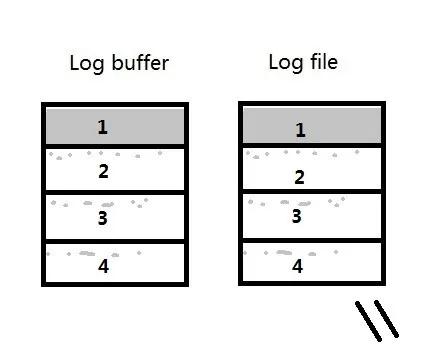
这样,可能会导致redo log file只写入了一个strand的内容,其他部分几乎是空的,则产生的archive log会只接近64M,而不是256M。当CPU_COUNT很大时,这个差值会更大。
例2):当log buffer的大小是256M,而redo log file的大小是1G的时候,每个strand还是256M/4=64M。每一个redo log file被启用时,会预先将redo log file中的大小分配出4个64M与log buffer对应,如图:
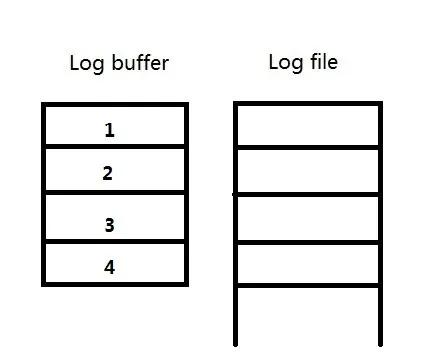
这时,redo log file中还有1G-256M=768M剩余的未分配的空间。
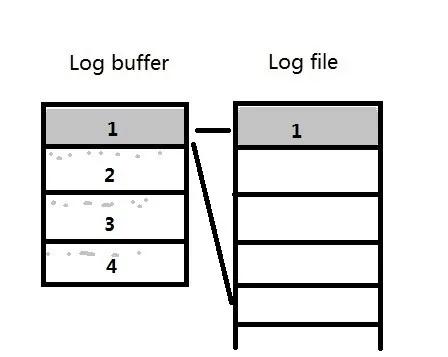
如果strand 1写满之后,LGWR会将log buffer中strand 1的内容写入到redo log file中,并且试图从redo log file中分配一个新的64M空间,然后不断往下写。 图片
直到redo log file中再没有可分配空间了,则将所有strand中的内容写入日志,并作日志切换。
例3):当log buffer的大小是256M,而redo log file的大小是100M的时候,每个strand还是256M/4=64M。但是redo log file中的空间会按strand的个数平均分配,也就是每块100M/4=25M。
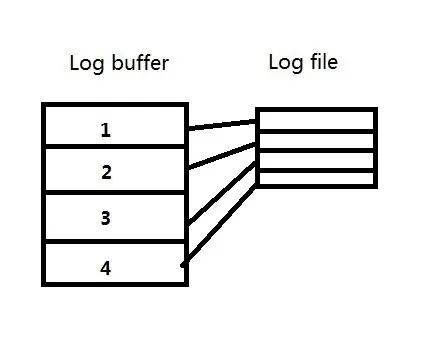
这样,当每个strand中的内容写到25M的时候,就会日志切换,而不是64M。相当于log buffer中的一部分空间被浪费了。
5:检查是否开启归档日志压缩
此功能的目的是在归档传输到远程或者归档存储到磁盘之前进行压缩,以便减少归档日志传输的时间和占用的磁盘空间。可以使用下面脚本检查。
SELECT NAME, ARCHIVELOG_COMPRESSION FROM V$DATABASE; SELECT TO_CHAR(FIRST_TIME, 'YYYY-MM-DD HH24:MI:SS'), BLOCKS * BLOCK_SIZE / 1024 / 1024, COMPRESSED FROM V$ARCHIVED_LOG; SQL> SELECT NAME, 2 ARCHIVELOG_COMPRESSION 3 FROM V$DATABASE; NAME ARCHIVEL --------- -------- GSPP DISABLED起初,估计很多人都会被这个所迷惑,其实ORACLE 10g 、 11g都是不支持归档日志压缩的,也没有明确的官方文档说明,其实归档日志压缩本来是ORACLE 10g计划引入的新特性,不幸的是这个计划放弃了,而且ORACLE 11g也不支持。
Archive compression was a planned new feature for 10G, but unfortunately it was withdrawn and it is still not available in 11g .This feature is expected in future releases
最后大家可以去metalink上看看Archived redolog is (significant) smaller than the redologfile. (文档 ID 1356604.1)这篇文章,官方文档不愧是官方文档,最全面的阐述了归档日志比重做日志小的原因。
Archived redolog is (significant) smaller than the redologfile. (文档 ID 1356604.1)
There are 2 possible causes for this : 1. Documented and designed behaviour due to explicit forcing an archive creation before the redolog file is full SQL> alter system switch logfile; SQL> alter system archive log current; RMAN> backup archivelog all; RMAN> backup database plus archivelog; ARCHIVE_LAG_TARGET : limits the amount of data that can be lost and effectively increases the availability of the standby database by forcing a log switch after the specified amount of time elapses. you can see this aswell in RAC with an idle/low-load instance. >2. Undocumented, but designed behaviour : BUG 9272059 - REDO LOG SWITCH AT 1/8 OF SIZE DUE TO CMT CPU'S BUG 10354739 - REDOLOGSIZE NOT COMPLETLY USED BUG 12317474 - FREQUENT REDO LOG SWITCHES GENERATING SMALL SIZED ARCHIVELOGS BUG 5450861 - ARCHIVE LOGS ARE GENERATED WITH A SMALLER SIZE THAN THE REDO LOG FILES BUG 7016254 - DECREASE CONTROL FILE ENQUEUE WAIT AT LOG SWITCH Explanation : As per Bug: 5450861 (closed as 'Not a Bug'): * The archive logs do not have to be even in size. This was decided a very long time ago, when blank padding the archive logs was stopped, for a very good reason - in order to save disk space. * The log switch does not occur when a redo log file is 100% full. There is an internal algorithm that determines the log switch moment. This also has a very good reason - doing the log switch at the last moment could incur performance problems (for various reasons, out of the scope of this note). As a result, after the log switch occurs, the archivers are copying only the actual information from the redo log files. Since the redo logs are not 100% full after the log switch and the archive logs are not blank padded after the copy operation has finished, this results in uneven, smaller files than the original redo log files. There are a number of factors which combine to determine the log switch frequency. These are the most relevant factors in this case: a) RDBMS parameter LOG_BUFFER_SIZE If this is not explicitly set by the DBA then we use a default; at instance startup the RDBMS calculates the number of shared redo strands as ncpus/16, and the size of each strand is 128Kb * ncpus (where ncpus is the number of CPUs in the system). The log buffer size is the number of stands multiplied by the strand size. The calculated or specified size is rounded up to a multiple of the granule size of a memory segment in the SGA. For 11.2 if SGA size >= 128GB then granule size is 512MB 64GB <= SGA size < 128GB then granule size is 256MB 32GB <= SGA size < 64GB then granule size is 128MB 16GB <= SGA size < 32GB then granule size is 64MB 8GB <= SGA size < 16GB then granule size is 32MB 1GB <= SGA size < 8GB then granule size is 16MB SGA size < 1GB then granule size is 4MB There are some minimums and maximums enforced. b) System load Initially only one redo strand is used, ie the number of "active" redo strands is 1, and all the processes copy their redo into that one strand. When/if there is contention for that strand then the number of active redo strands is raised to 2. As contention for the active strands increases, the number of active strands increases. The maxmum possible number of active redo strands is the number of strands initially allocated in the log buffer. (This feature is called "dynamic strands", and there is a hidden parameter to disable it which then allows processes to use all the strands from the outset). c) Log file size This is the logfile size decided by the DBA when the logfiles are created. d) The logfile space reservation algorithm When the RDBMS switches into a new online redo logfile, all the log buffer redo strand memory is "mapped" to the logfile space. If the logfile is larger than the log buffer then each strand will map/reserve its strand size worth of logfile space, and the remaining logfile space (the "log residue") is still available. If the logfile is smaller than the log buffer, then the whole logfile space is divided/mapped/reserved equally among all the strands, and there is no unreserved space (ie no log residue). When any process fills a strand such that all the reserved underlying logfile space for that strand is used, AND there is no log residue, then a log switch is scheduled. Example : 128 CPU's so the RDBMS allocates a log_buffer of size 128Mb containing 8 shared strands of size 16Mb. It may be a bit larger than 128Mb as it rounds up to an SGA granule boundary. The logfiles are 100Mb, so when the RDBMS switches into a new online redo logfile each strand reserves 100Mb/8 = 25600 blocks and there is no log residue. If there is low system load, only one of the redo strands will be active/used and when 25600 blocks of that strand are filled then a log switch will be scheduled - the created archive logs have a size around 25600 blocks. With everything else staying the same (128 cpu's and low load), using a larger logfile would not really reduce the amount of unfilled space when the log switches are requested, but it would make that unfilled space less significant as a percentage of the total logfile space, eg - with a 100Mb logfile, the log switch happens with 7 x 16Mb logfile space unfilled (ie the logfile is 10% full when the log switch is requested) - with a 1Gb logfile, the log switch would happen with 7 x 16Mb logfile space unfilled (ie the logfile is 90% full when the log switch is requested) With a high CPU_COUNT, a low load and a redo log file size smaller than the redolog buffer, you may see small archived log files because of log switches at about 1/8 of the size of the define log file size. This is because CPU_COUNT defines the number of redo strands (ncpus/16). With a low load only a single strand may be used. With redo log file size smaller than the redolog buffer, the log file space is divided over the available strands. When for instance only a single active strand is used, a log switch can already occur when that strand is filled.“如何理解Oracle归档日志比联机重做日志小很多的情况”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/a90ReKSNecOHhgtrF-Qi4A



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



