这篇文章主要是分享最近在开发中正则的学习心得体会。我们开发,一开始是采用python的正则库,后来为了适应Spring Cloud兼容Java所以正则也相应的修改成为了Java版本,经过测试,Java在匹配速度上相对慢了好多,平台一天需要处理一亿多条日志,但按照当时的处理速度,每天差不多就只能处理了2千多万条,这样的速度,实在扎心,提单申请扩容,那边的负责人说资源不足,好咯,将Java所使用的正则库替换成C++,C++够快了吧,不过,这个库是通过牺牲功能换取性能来实现的。
理论模型是有穷自动机,具体的实现为正则引擎(Regex Engine)分两类确定型有穷自动机(Definite Finite Automata,DFA,其状态都是确定)和非确定型有穷自动机(Non-definite Finite Automate,NFA,其状态在某个时刻是不确定的)。DFA和NFA是可以证明存在等价关系,不过这是两种不同的自动机。在这里,我才不会深入讨论它们的原理。简单地说,DFA 的时间复杂度是线性的。它更稳定,但功能有限。NFA 的时间复杂度相对不稳定。 根据正则表达式的不同,时间有时长,有时短。NFA 的优点是它的功能更强大,所以被 Java、.NET、Perl、Python、Ruby 和 PHP 用来处理正则表达式。 NFA 是怎样进行匹配的呢?我用下面的字符串和表达式作为例子。
text="A lovely cat."
regex="cat"
NFA 匹配是基于正则表达式的。也就是说,NFA 将依次读取正则表达式的匹配符,并将其与目标字符串进行匹配。如果匹配成功,它将转到正则表达式的下一个匹配符。否则,它将继续与目标字符串的下一个字符进行比较。 让我们一步一步地来看一下上面的例子。
为了应对NFA状态不确定,可能会匹配出错误的结果,因此需要“尝试失败-重新选择”的过程,现在,我已经解释了 NFA 是如何进行字符串匹配的——回溯法。我们将使用下面的例子,以便更好的解释回朔法。
text="xyyyyyyz"
regex="xy{1,10}z"
这是一个比较简单的例子。正则表达式以 x 开始,以 z 结束。它们之间有以 1-10 个 y 组成的字符串。NFA 的匹配过程如下:
y{1,10},将它与字符串的第二个字符 y 进行比较。它们又匹配了。y{1,10} 代表 1-10 个 y,基于 NFA 的贪婪特性(即,尽可能地进行匹配),此时它不会读取正则表达式的下一个匹配符,而是仍然使用y{1,10} 与字符串的第三个字符 y 进行比较。它们匹配了。于是继续用 y{1,10} 与字符串的第n个字符 y 进行比较,直到第七个,它们不匹配。 回溯就出现在这里?标志,贪婪模式将变成勉强模式。此时,它将尽可能少地匹配。然而,勉强模式下回溯仍可能出现。+标志,则原来的贪婪模式将变成独占模式。也就是说,它将匹配尽可能多的字符,但不会回溯。text="xyyyyyyz"
regex="xy{1,10}?z"
正则表达式的第一个字符 x 与字符串的第一个字符 x 相匹配。正则表达式的第二个运算符 y{1,10}? 匹配了字符串的第二个字符 y 。由于最小匹配的原则,正则表达式将读取第三个运算符 z,并与字符串第三个字符 y 进行比较。两者不匹配。因此,程序进行回溯并将正则表达式的第二个运算符 y{1,10}? 与字符串的第三个字符 y 进行比较。还是匹配成功了。之后继续匹配,正则表达式的第三个匹配符 c 与字符串的第七个字符 z 正相匹配。匹配结束。
这三种模式,在Python,Java这些常见的开发工具中是比较常用的,然而在C++中并不是合适,我们开发团队经过一次次的修改、优化,在性能调优上才有了质的飞跃。
下面以一份日志为例,介绍利用前面介绍的三种模式所开发出来的模型匹配。
[INFO][08:27:34.260][2b0e7244d940]:LOGIN| client_id=007102| ip=8.8.8.8| uin=66666666 | mailname=123456789@139.com| userip=223.3.3.3|
我们想要的就是将日志中的数据进行提取,获得我们想要的内容,其中包括,clientIP、userID、user、mobileNumber这些,因为还有其他数据描述,后续提高数据挖掘的效率,和对安全风险的分析能力,我们也想对这些日志进行解析。一开始我们使用贪婪模式,也就是常见的使用*,看图中箭头方向,这个步长4635,大概需要11ms,步长其实就是回溯的次数,迭代计算这么多次,对于性能来说确实挺令人失望的,原因已经很明显了,就是由于*导致的,贪婪匹配n次直到和下个符号不匹配为止,因此消耗了大量的计算性能,这个也是我们需要进行优化地方。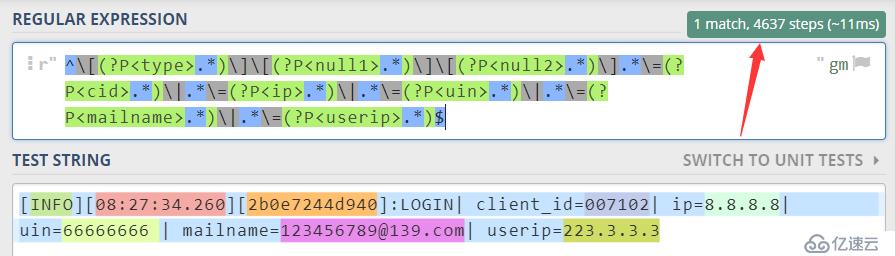
^[(?P<type>.)][(?P<null1>.)][(?P<null2>.)].\=(?P<cid>.)|.\=(?P<ip>.)|.\=(?P<uin>.)|.\=(?P<mailname>.)|.\=(?P<userip>.*)$
接下来开始调优对原来的贪婪模式追加勉强匹配(外文名词翻译真让人抓狂),匹配效果卓著,原因在于勉强模式尽最大努力地减少了回溯次数,在原来的回溯全文之后的基础上,该模式如果遇匹配上了下个字符,立即结束,比如匹配type这个字段,我们的原先的贪婪模式,没遇到一次就会全文都匹配一遍之后在回到起点,确认匹配完成,而勉强模式则是在边界就停下来,比如\],\[等字段。
到了这里我们并不满足,是否还可以更快,对计算资源是否可以更友好?毕竟我们的计算资源很宝贵,于是可以继续尝试使用独占模式。见下图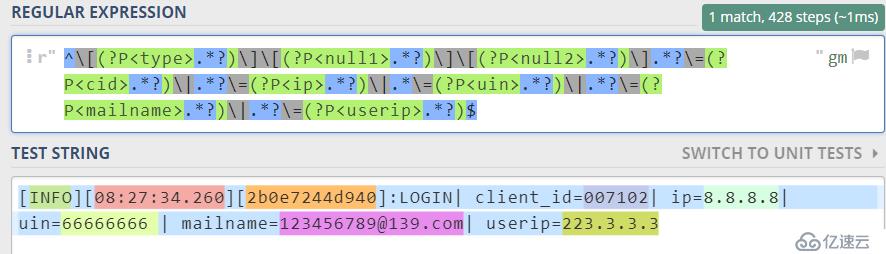
^[(?P<type>.?)][(?P<null1>.?)][(?P<null2>.?)].?\=(?P<cid>.?)|.?\=(?P<ip>.?)|.\=(?P<uin>.?)|.?\=(?P<mailname>.?)|.?\=(?P<userip>.*?)$
在这个模式下我们的表达式性能得到了极大的提升,此时相较于初始版本,性能已经提高了十倍,称之为勉强追加独占模式,该匹配已经匹配了,基本上可以交差给服务器日夜不停工作了。
此时性能看起来已经达到了最优了,但我们要考虑到表达式的健壮性,毕竟在众多的日志里,总会出现有些字段为空(并不是null)的情况,如下图所示,我特意删除一些字段,如果是空格还好,当不是的时候又应该怎么处理咧?
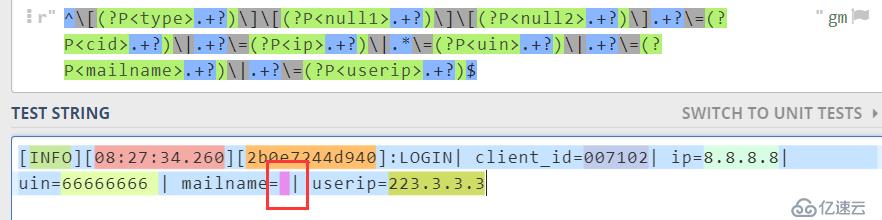
这里需要使用|这个符号,对这样的场景经行适配,此时不管是空的还是有数据的都没啥关系了,我们已经做好了应对准备。
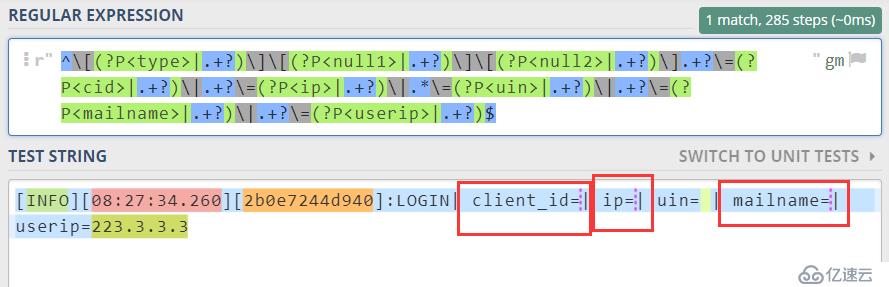
^[(?P<type>.+?)][(?P<null1>.+?)][(?P<null2>.+?)].+?\=(?P<cid>.+?)|.+?\=(?P<ip>.+?)|.*\=(?P<uin>.+?)|.+?\=(?P<mailname>.+?)|.+?\=(?P<userip>.+?)$
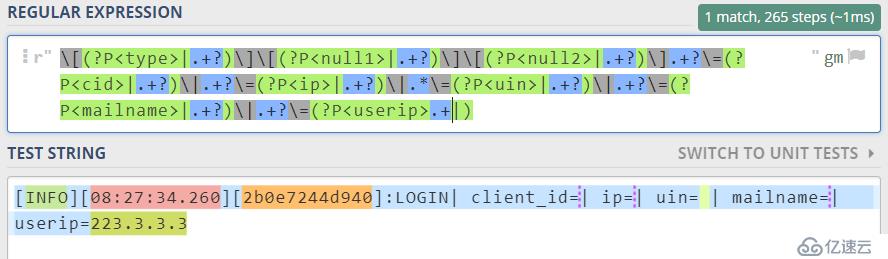
[(?P<type>|.+?)][(?P<null1>|.+?)][(?P<null2>|.+?)].+?\=(?P<cid>|.+?)|.+?\=(?P<ip>|.+?)|.*\=(?P<uin>|.+?)|.+?\=(?P<mailname>|.+?)|.+?\=(?P<userip>.+|)
这里我特意删除^和$这两个字符,考虑到在这个场景下,其实没必要规定起止符,因为我们是全文匹配的,起止符的出现反而需要计算机再验证一次是否到了终点,确定一下自己是不是在起点,有点画蛇添足。
在生产环境中学习很快,尴尬的就是没时间沉淀,生产的过程中遇到了好多我觉得是经典的场景,时间不允许匆匆留在工作笔记中,还没探究出所以然。之前以为我学会了正则,搞爬虫嘛,对正则也是要有一定的理解的,在进行模型分析的这段时间越发看不懂正则,总觉得这个是在写啥,官网说的是啥,看文档,现在写正则舒服很多了,处理日志各种不规范,提供的日志规范和接收到日志70%以上是不匹配的,还有拼写错误 ,各种命名法, 形式翻新,永不重复,这叫一个皮。。。
在线正则测试网站
这个网站可以很明显的提示我们表达式中的错误内容,或者说不符合语法规则的地方。跟我们说明该表达式的性能特点,消耗的资源等信息。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





