这篇文章主要讲解了“索引失效底层原理是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“索引失效底层原理是什么”吧!
单值索引B+树图
单值索引在B+树的结构里,一个节点只存一个键值对

联合索引
开局一张图,由数据库的a字段和b字段组成一个联合索引。
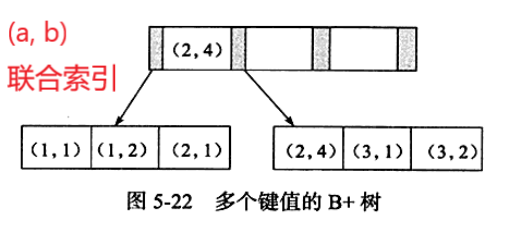
从本质上来说,联合索引也是一个B+树,和单值索引不同的是,联合索引的键值对不是1,而是大于1个。
a, b 排序分析
a顺序:1,1,2,2,3,3
b顺序:1,2,1,4,1,2
大家可以发现a字段是有序排列,b字段是无序排列(因为B+树只能选一个字段来构建有序的树)
一不小心又会发现,在a相等的情况下,b字段是有序的。
大家想想平时编程中我们要对两个字段排序,是不是先按照第一个字段排序,如果第一个字段出现相等的情况,就用第二个字段排序。这个排序方式同样被用到了B+树里。
分析最佳左前缀原理
先举一个遵循最佳左前缀法则的例子
select * from testTable where a=1 and b=2分析如下:
首先a字段在B+树上是有序的,所以我们可以通过二分查找法来定位到a=1的位置。
其次在a确定的情况下,b是相对有序的,因为有序,所以同样可以通过二分查找法找到b=2的位置。
再来看看不遵循最佳左前缀的例子
select * from testTable where b=2分析如下:
我们来回想一下b有顺序的前提:在a确定的情况下。
现在你的a都飞了,那b肯定是不能确定顺序的,在一个无序的B+树上是无法用二分查找来定位到b字段的。
所以这个时候,是用不上索引的。大家懂了吗?

范围查询右边失效原理
举例
select * from testTable where a>1 and b=2分析如下:
首先a字段在B+树上是有序的,所以可以用二分查找法定位到1,然后将所有大于1的数据取出来,a可以用到索引。
b有序的前提是a是确定的值,那么现在a的值是取大于1的,可能有10个大于1的a,也可能有一百个a。
大于1的a那部分的B+树里,b字段是无序的(开局一张图),所以b不能在无序的B+树里用二分查找来查询,b用不到索引。
like索引失效原理
where name like "a%" where name like "%a%" where name like "%a"我们先来了解一下%的用途
%放在右边,代表查询以"a"开头的数据,如:abc
两个%%,代表查询数据中包含"a"的数据,如:cab、cba、abc
%放在左边,代表查询以"a"为结尾的数据,如cba
为什么%放在右边有时候能用到索引
%放右边叫做:前缀
%%叫做:中缀
%放在左边叫做:后缀
没错,这里依然是最佳左前缀法则这个概念

大家可以看到,上面的B+树是由字符串组成的。
字符串的排序方式:先按照第一个字母排序,如果第一个字母相同,就按照第二个字母排序。。。以此类推
开始分析
一、%号放右边(前缀)
由于B+树的索引顺序,是按照首字母的大小进行排序,前缀匹配又是匹配首字母。所以可以在B+树上进行有序的查找,查找首字母符合要求的数据。所以有些时候可以用到索引。
二、%号放左边
是匹配字符串尾部的数据,我们上面说了排序规则,尾部的字母是没有顺序的,所以不能按照索引顺序查询,就用不到索引。
三、两个%%号
这个是查询任意位置的字母满足条件即可,只有首字母是进行索引排序的,其他位置的字母都是相对无序的,所以查找任意位置的字母是用不上索引的。
感谢各位的阅读,以上就是“索引失效底层原理是什么”的内容了,经过本文的学习后,相信大家对索引失效底层原理是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://segmentfault.com/a/1190000037495198



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



