本篇内容介绍了“SparkMagic能做什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
适用于Jupyter NoteBook的SparkMagic
Sparkmagic是一个通过Livy REST API与Jupyter Notebook中的远程Spark群集进行交互工作的项目。它提供了一组Jupyter Notebook单元魔术和内核,可将Jupyter变成用于远程集群的集成Spark环境。
SparkMagic能够:
以多种语言运行Spark代码
提供可视化的SQL查询
轻松访问Spark应用程序日志和信息
针对任何远程Spark集群自动创建带有SparkContext和HiveContext的SparkSession
将Spark查询的输出捕获为本地Pandas数据框架,以轻松与其他Python库进行交互(例如matplotlib)
发送本地文件或Pandas数据帧到远程集群(例如,将经过预训练的本地ML模型直接发送到Spark集群)
可以使用以下Dockerfile来构建具有SparkMagic支持的Jupyter Notebook:
FROM jupyter/all-spark-notebook:7a0c7325e470USER$NB_USER RUN pip install --upgrade pip RUN pip install --upgrade --ignore-installed setuptools RUN pip install pandas --upgrade RUN pip install sparkmagic RUN mkdir /home/$NB_USER/.sparkmagic RUN wget https://raw.githubusercontent.com/jupyter-incubator/sparkmagic/master/sparkmagic/example_config.json RUN mv example_config.json /home/$NB_USER/.sparkmagic/config.json RUN sed -i 's/localhost:8998/host.docker.internal:9999/g'/home/$NB_USER/.sparkmagic/config.json RUN jupyter nbextension enable --py --sys-prefix widgetsnbextension RUN jupyter-kernelspec install --user --name SparkMagic $(pip show sparkmagic |grep Location | cut -d" " -f2)/sparkmagic/kernels/sparkkernel RUN jupyter-kernelspec install --user --name PySparkMagic $(pip show sparkmagic| grep Location | cut -d" " -f2)/sparkmagic/kernels/pysparkkernel RUN jupyter serverextension enable --py sparkmagic USER root RUN chown $NB_USER /home/$NB_USER/.sparkmagic/config.json CMD ["start-notebook.sh","--NotebookApp.iopub_data_rate_limit=1000000000"] USER $NB_USER
生成图像并用以下代码标记:
docker build -t sparkmagic
并在Spark Magic支持下启动本地Jupyter容器,以安装当前工作目录:
docker run -ti --name\"${PWD##*/}-pyspark\" -p 8888:8888 --rm -m 4GB --mounttype=bind,source=\"${PWD}\",target=/home/jovyan/work sparkmagic为了能够连接到远程Spark集群上的Livy REST API,必须在本地计算机上使用ssh端口转发。获取你的远程集群的IP地址并运行:
ssh -L 0.0.0.0:9999:localhost:8998REMOTE_CLUSTER_IP
首先,使用启用了SparkMagic的PySpark内核创建一个新的Notebook,如下所示:

在启用了SparkMagic的Notebook中,你可以使用一系列单元魔术来在本地笔记本电脑以及作为集成环境的远程Spark集群中使用。%% help魔术输出所有可用的魔术命令:

可以使用%%configuremagic配置远程Spark应用程序:

如图所示,SparkMagic自动启动了一个远程PySpark会话,并提供了一些有用的链接以连接到Spark UI和日志。
Notebook集成了2种环境:
%%local,可在笔记本电脑和jupyter docker映像提供的anaconda环境中本地执行单元
%%spark,通过远程Spark集群上的PySpark REPL,再通过Livy REST API远程执行单元
首先将以下code cell远程导入SparkSql数据类型;其次,它使用远程SparkSession将Enigma-JHU Covid-19数据集加载到我们的远程Spark集群中。可以在Notebook中看到remote .show()命令的输出:

但这就是魔术开始的地方。可以将数据框注册为Hive表,并使用%%sql魔术对远程群集上的数据执行Hive查询,并在本地Notebook中自动显示结果。这不是什么高难度的事,但对于数据分析人员和数据科学项目早期的快速数据探索而言,这非常方便。

SparkMagic真正有用之处在于实现本地Notebook和远程群集之间无缝传递数据。数据科学家的日常挑战是在与临时集群合作以与其公司的数据湖进行交互的同时,创建并保持其Python环境。
在下例中,我们可以看到如何将seaborn导入为本地库,并使用它来绘制covid_data pandas数据框。
这些数据从何而来?它是由远程Spark集群创建并发送的。神奇的%%spark-o允许我们定义一个远程变量,以在单元执行时转移到本地笔记本上下文。我们的变量covid_data是一个远程集群上的SparkSQL Data Frame,和一个本地JupyterNotebook中的PandasDataFrame。
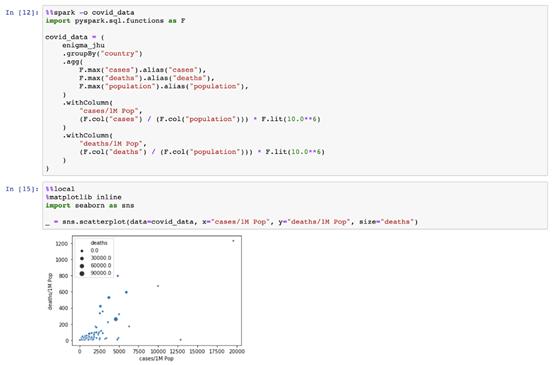
使用Pandas在Jupyter Notebook中聚合远程集群中的大数据以在本地工作的能力对于数据探索非常有帮助。例如,使用Spark将直方图的数据预汇总为bins,以使用预汇总的计数和简单的条形图在Jupyter中绘制直方图。
另一个有用的功能是能够使用魔术%%spark-o covid_data -m sample -r 0.5来采样远程Spark DataFrame。集成环境还允许你使用神奇的%%send_to_spark将本地数据发送到远程Spark集群。
PandasDataFrames和字符串支持的两种数据类型。要将其他更多或更复杂的东西(例如,经过训练的scikit模型用于评分)发送到远程Spark集群,可以使用序列化创建用于传输的字符串表示形式:
import pickle import gzip import base64serialised_model = base64.b64encode( gzip.compress( pickle.dumps(trained_scikit_model) ) ).decode()
但正如你所见,这种短暂的PySpark集群模式有一大诟病:使用Python软件包引导EMR集群,且这个问题不会随着部署生产工作负载而消失。
“SparkMagic能做什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





