如何分析Spark中大数据产品的测试方法与实现,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
Spark作为现在主流的分布式计算框架,已经融入到了很多的产品中作为ETL的解决方案。 而我们如果想要去测试这样的产品就要对分布式计算的原理有个清晰的认知并且也要熟悉分布式计算框架的使用来针对各种ETL场景设计不同的测试数据。 而一般来说我们需要从以下两个角度来进行测试。
ETL能兼容各种不同的数据(不同的数据规模,数据分布和数据类型)
ETL处理数据的正确性
测试数据兼容
ETL是按一定规则针对数据进行清洗,抽取,转换等一系列操作的简写。那么一般来说他要能够处理很多种不同的数据类型。 我们在生产上遇见的bug有很大一部分占比是生产环境遇到了比较极端的数据导致我们的ETL程序无法处理。 比如:
数据拥有大量分片
在分布式计算中,一份数据是由多个散落在HDFS上的文件组成的, 这些文件可能散落在不同的机器上, 只不过HDFS会给使用者一个统一的视图,让使用者以为自己在操作的是一个文件,而不是很多个文件。 这是HDFS这种分布式文件系统的存储方式。 而各种分布式计算框架, 比如hadoop的MapReduce,或者是spark。 就会利用这种特性,直接读取散落在各个机器上文件并保存在那个节点的内存中(理想状态下,如果资源不够可能还是会发生数据在节点间迁移)。
而读取到内存中的数据也是分片的(partition)。 spark默认以128M为单位读取数据,如果数据小于这个值会按一个分片存储,如果大于这个值就继续往上增长分片。 比如一个文件的大小是130M, spark读取它的时候会在内存中分成两个partition(1个128M,1个2M)。 如果这个文件特别小,只有10M,那它也会被当做一个partition存在内存中。 所以如果一份数据存放在HDFS中,这个数据是由10个散落在各个节点的文件组成的。 那么spark在读取的时候,就会至少在内存中有10个partition, 如果每个文件的大小都超过了128M,partition的数量会继续增加。
而在执行计算的时候,这些存储在多个节点内存中的数据会并发的执行数据计算任务。 也就是说我们的数据是存放在多个节点中的内存中的, 我们为每一个partition都执行一个计算任务。 所以我们针对一个特别大的数据的计算任务, 会首先把数据按partition读取到不同节点的不同的内存中, 也就是把数据拆分成很多小的分片放在不同机器的内存中。 然后分别在这些小的分片上执行计算任务。 最后再聚合每个计算任务的结果。 这就是分布式计算的基本原理。
那么这个时候问题就来了, 这种按partition为单位的分布式计算框架。partition的数量决定着并发的数量。 可以理解为,如果数据有100个partition,就会有100个线程针对这份数据做计算任务。所以partition的数量代表着计算的并行程度。 但是不是说partition越多越好,如果明明数据就很小, 我们却拆分了大量的partition的话,反而是比较慢的。 而且所有分片的计算结果最后是要聚合在一个地方的。 这些都会造成网络IO的开销(因为数据是在不同的节点之前传输的)。 尤其是在分布式计算中,我们有shuffle这个性能杀手(不熟悉这个概念的同学请看我之前的文章)。 在大量的分片下执行shuffle将会是一个灾难,因为大量的网络IO会导致集群处于很高的负载甚至瘫痪。 我们曾经碰见过只有500M但是却有7000个分片的数据,那一次的结果是针对这个数据并行执行了多个ETL程序后,整个hadoop集群瘫痪了。 这是在数据预处理的时候忘记做reparation(重新分片)的结果。
数据倾斜
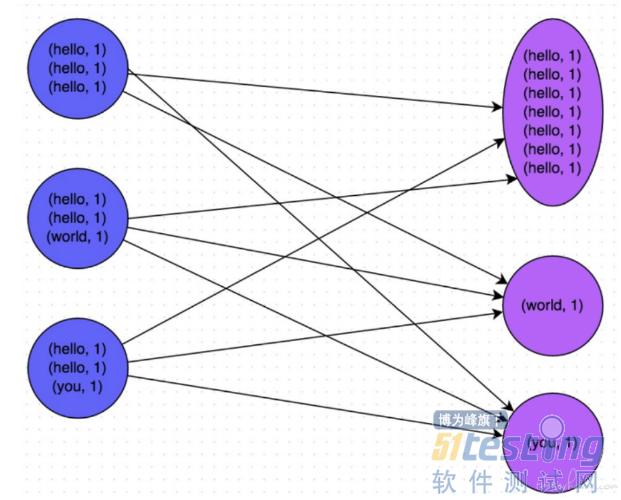
在上面的任务处理中出现了shuffle的操作。shuffle也叫洗牌, 在上面讲partition和分布式计算原理的时候,我们知道分布式计算就是把数据划分很多个数据片存放在很多个不同的节点上, 然后在这些数据片上并发执行同样的计算任务来达到分布式计算的目的,这些任务互相是独立的, 比如我们执行一个count操作, 也就是计算这个数据的行数。 实际的操作其实是针对每个数据分片,也就是partition分别执行count的操作。 比如我们有3个分片分别是A,B,C, 那执行count的时候其实是并发3个线程,每个线程去计算一个partition的行数, 他们都计算完毕后,再汇总到driver程序中, 也就是A,B,C这三个计算任务的计算过程是彼此独立互不干扰的,只在计算完成后进行聚合。
但并不是所有的计算任务都可以这样独立的,比如你要执行一个groupby的sql操作。 就像上面的图中,我要先把数据按单词分组,之后才能做其他的统计计算, 比如统计词频或者其他相关操作。 那么首先spark要做的是根据groupby的字段做哈希,相同值的数据传送到一个固定的partition上。 这样就像上图一样,我们把数据中拥有相同key值的数分配到一个partition, 这样从数据分片上就把数据进行分组隔离。
然后我们要统计词频的话,只需要才来一个count操作就可以了。 shuffle的出现是为了计算能够高效的执行下去, 把相似的数据聚合到相同的partition上就可以方便之后的计算任务依然是独立隔离的并且不会触发网络IO。 这是方便后续计算的设计模式,也就是节省了后续一系列计算的开销。 但代价是shuffle本身的开销,而且很多情况下shuffle本身的开销也是很大的。 尤其是shuffle会因为数据倾斜而出现著名的长尾现象。
根据shuffle的理论,相似的数据会聚合到同一个partition上。 但是如果我们的数据分布不均匀会出现什么情况呢? 比如我们要针对职业这个字段做groupby的操作, 但是如果100W行数据中有90W行的数据都是程序员这个职业的话, 会出现什么情况? 你会发现有90W行的数据都跑到了同一个partition上造成一个巨大的partition。这样就违背了分布式计算的初衷, 分布式计算的初衷就是把数据切分成很多的小数据分布在不同的节点内存中,利用多个节点的并行计算能力来加速计算过程。
但是现在我们绝大部分的数据都汇聚到了一个partition中,这样就又变成了单点计算。 而且这里还有一个特别大的问题, 就是我们在提交任务到hadoop yarn上的时候,申请的资源是固定且平均分配的。 比如我申请10个container去计算这份数据,那这10个container的资源是相等的,哪个也不多,哪个也不少。 但是我们的数据分片的大小却是不一样的, 比如90W行的分片需要5个G的内存,但是其他的数据分片可能1个G就够了。 所以如果我们不知道有数据倾斜的情况出现而导致申请的资源教少,就会导致任务OOM而挂掉。 而如果我们为了巨大的数据分片为每个container都申请了5G的资源, 那又造成了资源浪费。
数据倾斜和shuffle是业界经典难题,很难处理。 在很多大数据产品中都会有根据数据大小自动调整申请资源的功能。而数据倾斜就是这种功能绝对的天敌。 处理不好的话,要不会变成申请过大资源承包集群,要不会申请过小资源导致任务挂掉。 而我们在测试阶段要做的,就是模拟出这种数据倾斜的数据, 然后验证ETL程序的表现。
宽表
列数太多的表就是宽表。比如我见过的最宽的表是1W列的, 尤其在机器学习系统中, 由于要抽取高维特征, 所以在ETL阶段经常会把很多的表拼接成一个很大的宽表。这种宽表是数据可视化的天敌,比如我们的功能是可以随机预览一份数据的100行。 那100*1W这样的数据量要传输到前端并渲染就是个很费事的操作了。尤其是预览本身也是要执行一些计算的。如果加上这份数据本来就有海量分片的话, 要在后台打开这么多的文件,再加上读取这么宽的表的数据。 甚至有可能OOM, 实际上我也确实见过因为这个原因OOM的。 所以这个测试点就是我们故意去造这样的宽表进行测试。
其他的数据类型不一一解释了, 都跟字面的意思差不多。
造数
之所以也使用spark这种分布式框架来造数,而不是单独使用parquet或者hdfs的client是因为我们造的数据除了要符合一些极端场景外,也要保证要有足够的数据量, 毕竟ETL都是面对大数据场景的。 所以利用spark的分布式计算的优势可以在短时间内创建大量数据。 比如我前两天造过一个1亿行,60个G的数据,只用了20分钟。
技术细节
RDD是spark的分布式数据结构。 一份数据被spark读取后会就生成一个RDD,当然RDD就包含了那些partition。 我们创建RDD的方式有两种, 一种是从一个已有的文件中读取RDD,当然这不是我们想要的效果。 所以我们使用第二种, 从内存中的一个List中生成RDD。 如下:
public class Demo { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("data produce") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); SparkSession spark = SparkSession .builder() .appName("Java Spark SQL basic example") .getOrCreate(); List data = new XRange(1000); JavaRDD distData = sc.parallelize(data, 100);上面是我写的一个demo,前面初始化spark conf和spark session的代码可以先忽略不用管。 主要看最后两行, XRange是我仿照python的xrange设计的类。 可以帮我用类似生成器的原理创建一个带有index序列的List。 其实这里我们手动创建一个list也行。 而最后一行就是我们通过spark的API把一个List转换成一个RDD。sc.parallelize的第一个参数是List,而第二个参数就是你要设置的并行度, 也可以理解为你要生成这个数据的partition的数量。 其实如果我们现在想生成这一千行的只有index的数据的话, 再调用这样一个API就可以了:distData.saveAsTextFile("path"); 通过这样一个API就可以直接保存文件了。 当然这样肯定不是我们想要的,因为里面还没有我们要的数据。 所以这个时候我们要出动spark的一个高级接口,dataframe。 dataframe是spark仿照pandas的dataframe的设计开发的高级API。 功能跟pandas很像, 我们可以把一个dataframe就当做一个表来看, 而它也有很多好用的API。 最重要的是我们有一个DataframeWriter类专门用来将dataframe保存成各种各样格式和分区的数据的。 比如可以很方便的保存为scv,txt这种传统数据, 可以很方便保存成parquet和orc这种列式存储的文件格式。 也提供partition by的操作来保存成分区表或者是分桶表。总之它能够帮我们造出各种我们需要的数据。 那么我们如何把一个RDD转换成我们需要的dataframe并填充进我们需要的数据呢。 往下看:
List fields = new ArrayList<>(); String schemaString = "name,age"; fields.add(DataTypes.createStructField("name", DataTypes.StringType, true)); fields.add(DataTypes.createStructField("age", DataTypes.IntegerType, true)); StructType schema = DataTypes.createStructType(fields); // Convert records of the RDD (people) to Rows JavaRDD rowRDD = distData.map( record ->{ RandomStringField randomStringField = new RandomStringField(); randomStringField.setLength(10); BinaryIntLabelField binaryIntLabelField = new BinaryIntLabelField(); return RowFactory.create(randomStringField.gen(), binaryIntLabelField.gen()); }); Dataset dataset =spark.createDataFrame(rowRDD, schema); dataset.persist(); dataset.show(); DataFrameWriter writer = new DataFrameWriter(dataset); writer.mode(SaveMode.Overwrite).partitionBy("age"). parquet("/Users/sungaofei/gaofei");dataframe中每一个数据都是一行,也就是一个Row对象,而且dataframe对于每一列也就是每个schema有着严格的要求。 因为它是一个表么。所以跟数据库的表或者pandas中的表是一样的。要规定好每一列的schema以及每一行的数据。 所以首先我们先定义好schema, 定义每个schema的列名和数据类型。 然后通过DataTypes的API创建schema。 这样我们的列信息就有了。 然后是关键的我们如何把一个RDD转换成dataframe需要的Row并且填充好每一行的数据。 这里我们使用RDD的map方法, 其实dataframe也是一个特殊的RDD, 这个RDD里的每一行都是一个ROW对象而已。 所以我们使用RDD的map方法来填充我们每一行的数据并把这一行数据转换成Row对象。
JavaRDD rowRDD = distData.map( record ->{ RandomStringField randomStringField = new RandomStringField(); randomStringField.setLength(10); BinaryIntLabelField binaryIntLabelField = new BinaryIntLabelField(); return RowFactory.create(randomStringField.gen(), binaryIntLabelField.gen()); });因为之前定义schema的时候只定义了两列, 分别是name和age。 所以在这里我分别用一个随机生成String类型的类和随机生成int类型的类来填充数据。 最后使用RowFactory.create方法来把这两个数据生成一个Row。 map方法其实就是让使用者处理每一行数据的方法, record这个参数就是把行数据作为参数给我们使用。 当然这个例子里原始RDD的每一行都是当初生成List的时候初始化的index序号。 而我们现在不需要它, 所以也就没有使用。 直接返回随机字符串和int类型的数。 然后我们有了这个每一行数据都是Row对象的RDD后。 就可以通过调用下面的API来生成dataframe。
Dataset dataset =spark.createDataFrame(rowRDD, schema);分别把row和schema传递进去,生成dataframe的表。 最后利用DataFrameWriter保存数据。
好了, 这就是造数的基本原理了, 其实也是蛮简单的。 当然要做到严格控制数据分布,数据类型,特征维度等等就需要做很多特殊的处理。 这里就不展开细节了。
测试ETL处理的正确性
输入一份数据,然后判断输出的数据是否是正确的。 只不过我们这是在大数据量下的处理和测试,输入的数据是大数据,ELT输出的也是大数据, 所以就需要一些新的测试手段。 其实这个测试手段也没什么新奇的了, 是我们刚才一直在讲的技术,也就是spark这种分布式计算框架。 我们以spark任务来测试这些ETL程序,这同样也是为了测试自身的效率和性能。 如果单纯使用hdfs client来读取文件的话, 扫描那么大的数据量是很耗时的,这是我们不能接受的。 所以我们利用大数据技术来测试大数据功能就成为了必然。 当然也许有些同学会认为我只是测试功能么,又不是测试算法的处理性能,没必要使用那么大的数据量。 我们用小一点的数据,比如一百行的数据就可以了。 但其实这也是不对的, 因为在分布式计算中, 大数量和小数据量的处理结果可能不是完全一致的, 比如随机拆分数据这种场景在大数据量下可能才能测试出bug。 而且大数据测试还有另外一种场景就是数据监控, 定期的扫描线上数据,验证线上数据是否出现异常。 这也是一种测试场景,而且线上的数据一定是海量的。
废话不多说,直接看下面的代码片段。
@Features(Feature.ModelIde) @Stories(Story.DataSplit) @Description("使用pyspark验证随机拆分中的分层拆分") @Test public void dataRandomFiledTest(){ String script = "# coding: UTF-8\n" + "# input script according to definition of \"run\" interface\n" + "from trailer import logger\n" + "from pyspark import SparkContext\n" + "from pyspark.sql import SQLContext\n" + "\n" + "\n" + "def run(t1, t2, context_string):\n" + " # t2为原始数据, t1为经过数据拆分算子根据字段分层拆分后的数据\n" + " # 由于数据拆分是根据col_20这一列进行的分层拆分, 所以在这里分别\n" + " # 对这2份数据进行分组并统计每一个分组的计数。由于这一列是label\n" + " # 所以其实只有两个分组,分别是0和1\n" + " t2_row = t2.groupby(t2.col_20).agg({\"*\" : \"count\"}).cache()\n" + " t1_row = t1.groupby(t1.col_20).agg({\"*\" : \"count\"}).cache()\n" + " \n" + " \n" + " t2_0 = t2_row.filter(t2_row.col_20 == 1).collect()[0][\"count(1)\"]\n" + " t2_1 = t2_row.filter(t2_row.col_20 == 0).collect()[0][\"count(1)\"]\n" + " \n" + " t1_0 = t1_row.filter(t1_row.col_20 == 1).collect()[0][\"count(1)\"]\n" + " t1_1 = t1_row.filter(t1_row.col_20 == 0).collect()[0][\"count(1)\"]\n" + " \n" + " # 数据拆分算子是根据字段按照1:1的比例进行拆分的。所以t1和t2的每一个分组\n" + " # 都应该只有原始数据量的一半\n" + " if t2_0/2 - t1_0 >1:\n" + " raise RuntimeError(\"the 0 class is not splited correctly\")\n" + " \n" + " if t2_1/2 - t1_1 >1:\n" + " raise RuntimeError(\"the 1 class is not splited correctly\")\n" + "\n" + " return [t1]";我们用来扫描数据表的API仍然是我们之前提到的dataframe。上面的代码片段是我们嵌入spark任务的脚本。 里面t1和t2都是dataframe, 分别代表原始数据和经过数据拆分算法拆分后的数据。 测试的功能是分层拆分。 也就是按某一列按比例抽取数据。 比如说100W行的数据,我按job这个字段分层拆分, 我要求的比例是30%。 也即是说每种职业抽取30%的数据出来,相当于这是一个数据采样的功能。 OK, 所以在测试脚本中,我们分别先把原始表和经过采样的表按这一列进行分组操作, 也就是groupby(col_20)。 这里我选择的是按col_20进行分层拆分。 根据刚才讲的这样的分组操作后会触发shuffle,把有相同职业的数据传到一个数据分片上。 然后我们做count这种操作统计每一个组的行数。 因为这个算法我是按1:1拆分的,也就是按50%采样。 所以最后我要验证拆分后的数据的每一组的行数都是原始数据中该组的一半。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.toutiao.com/a6828103607133405704/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



