这篇文章将为大家详细讲解有关大数据中基于用户画像的Clustering分析是怎样的,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
聚类(Clustering),顾名思义就是“物以类聚,人以群分”,其主要思想是按照特定标准把数据集聚合成不同的簇,使同一簇内的数据对象的相似性尽可能大,同时,使不在同一簇内的数据对象的差异性尽可能大。通俗地说,就是把相似的对象分到同一组。
聚类算法通常不使用训练数据,只要计算对象间的相似度即可应用算法。这在机器学习领域中被称为无监督学习。
某大型保险企业拥有海量投保客户数据,由于大数据技术与相关人才的紧缺,企业尚未建立统一的数据仓库与运营平台,积累多年的数据无法发挥应有的价值。企业期望搭建用户画像,对客户进行群体分析与个性化运营,以此激活老客户,挖掘百亿续费市场。众安科技数据团队对该企业数据进行建模,输出用户画像并搭建智能营销平台。再基于用户画像数据进行客户分群研究,制订个性化运营策略。
本文重点介绍聚类算法的实践。
Step 1 数据预处理
任何大数据项目中,前期数据准备都是一项繁琐无趣却又十分重要的工作。
首先,对数据进行标准化处理,处理异常值,补全缺失值,为了顺利应用聚类算法,还需要使用户画像中的所有标签以数值形式体现。
其次要对数值指标进行量纲缩放,使各指标具有相同的数量级,否则会使聚类结果产生偏差。
接下来要提取特征,即把最初的特征集降维,从中选择有效特征放进聚类算法里跑。众安科技为该保险公司定制的用户画像中,存在超过200个标签,为不同的运营场景提供了丰富的多维度数据支持。但这么多标签存在相关特征,假如存在两个高度相关的特征,相当于将同一个特征的权重放大两倍,会影响聚类结果。
我们可以通过关联规则分析(Association Rules)发现并排除高度相关的特征,也可以通过主成分分析(Principal Components Analysis,简称PCA)进行降维。这里不详细展开,有兴趣的读者可以自行了解。
Step 2 确定聚类个数
层次聚类是十分常用的聚类算法,是根据每两个对象之间的距离,将距离最近的对象两两合并,合并后产生的新对象再进行两两合并,以此类推,直到所有对象合为一类。
Ward方法在实际应用中分类效果较好,应用较广。它主要基于方差分析思想,理想情况下,同类对象之间的离差平方和尽可能小,不同类对象之间的离差平方和应该尽可能大。该方法要求样品间的距离必须是欧氏距离。
值得注意的是,在R中,调用ward方法的名称已经从“ward”更新为“ward.D”。
library(proxy) Dist <- dist(data,method='euclidean') #欧式距离 clusteModel <- hclust(Dist, method='ward.D') plot(clusteModel)
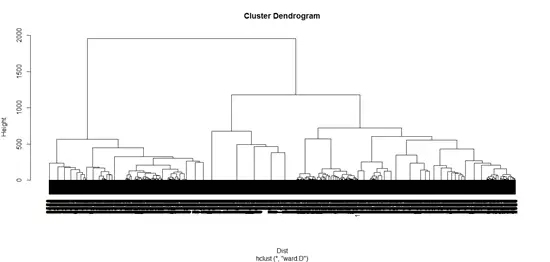
根据R绘制的层次聚类图像,我们对该企业的客户相似性有一个直观了解,然而单凭肉眼,仍然难以判断具体的聚类个数。这时我们通过轮廓系数法进一步确定聚类个数。
轮廓系数旨在对某个对象与同类对象的相似度和与不同类对象的相似度做对比。轮廓系数取值在-1到1之间,轮廓系数越大时,表示对应簇的数量下,聚类效果越好。
library(fpc) K <- 3:8 round <- 30 # 避免局部*** rst <- sapply(K,function(i){ print(paste("K=",i)) mean(sapply(1:round,function(r){ print(paste("Round",r)) result<- kmeans(data, i) stats<- cluster.stats(dist(data), result$cluster) stats$avg.silwidth })) }) plot(K,rst,type='l',main='轮廓系数与K的关系',ylab='轮廓系数')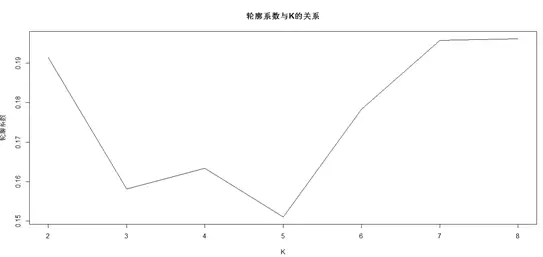
在轮廓系数的实际应用中,不能单纯取轮廓系数***的K值,还需要考虑聚类结果的分布情况(避免出现超大群体),以及从商业角度是否易于理解与执行,据此综合分析,探索合理的K值。
综上,根据分析研究,确定K的取值为7。
Step 3 聚类
K-means是基于距离的聚类算法,十分经典,简单而高效。其主要思想是选择K个点作为初始聚类中心, 将每个对象分配到最近的中心形成K个簇,重新计算每个簇的中心,重复以上迭代步骤,直到簇不再变化或达到指定迭代次数为止。K-means算法缺省使用欧氏距离来计算。
library(proxy) library(cluster) clusteModel <- kmeans(data, centers = 7, nstart =10) clusteModel$size result_df <- data.frame(data,clusteModel$cluster) write.csv(result_df, file ="clusteModel.csv", row.names = T, quote = T)
Step 4 聚类结果分析
对聚类结果(clusteModel.csv)进行数据分析,总结群体特征:
cluster=1:当前价值低,未来价值高。(5.6%)
cluster=2:当前价值中,未来价值高。(5.4%)
cluster=3:当前价值高,未来价值高。(18%)
cluster=4:当前价值高,未来价值中低。(13.6%)
cluster=5:高价值,稳定群。(14%)
cluster=6:当前价值低,未来价值未知(可能信息不全导致)。(2.1%)
cluster=7:某一特征的客户群体(该特征为业务重点发展方向)。(41.3%)
根据分析师与业务团队的讨论结果,将cluster=1与cluster=6进行合并,最终得到6个客户群体,并针对客户群体制订运营策略。
客户分群与运营策略
(业务敏感信息打码)

关于大数据中基于用户画像的Clustering分析是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





