这篇文章将为大家详细讲解有关MapReduce+HDFS海量数据去重的策略有哪些,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
随着存储数据信息量的飞速增长,越来越多的人开始关注存储数据的缩减方法。数据压缩、单实例存储和重复数据删除等都是经常使用的存储数据缩减技术。
重复数据删除往往是指消除冗余子文件。不同于压缩,重复数据删除对于数据本身并没有改变,只是消除了相同的数据占用的存储容量。重复数据删除在减少存储、降低网络带宽方面有着显著的优势,并对扩展性有所帮助。
举个简单的例子:在专门为电信运营商定制的呼叫详单去重应用程序中,我们就可以看到删除重复数据的影子。同样的,对于包含相同数据包的通信网络,我们可以使用这种技术来进行优化。
在存储架构中,删除重复数据的一些常用的方法包括:哈希、二进制比较和增量差分。在HadoopSphere这篇文章中,将专注于如何利用MapReduce和HDFS来消除重复的数据。(下面列出的方法中包括一些学者的实验方法,因此把术语定义为策略比较合适)。
策略1:只使用HDFS和MapReduce
Owen O’Malley在一个论坛的帖子中建议使用以下方法:
让你的历史数据按照MD5值进行排序。 运行一个MapReduce的作业,将你的新数据按照MD5进行排序。需要注意的是:你要做所有数据的整体排序,但因为MD5是在整个密钥空间中是均匀分布的,排序就变得很容易。
基本上,你挑选一个reduce作业的数量(如256),然后取MD5值的前N位数据来进行你的reduce作业。由于这项作业只处理你的新数据,这是非常快的。 接下来你需要进行一个map-side join,每一个合并的输入分块都包含一个MD5值的范围。RecordReader读取历史的和新的数据集,并将它们按照一定方式合并。(你可以使用map-side join库)。你的map将新数据和旧数据合并。这里仅仅是一个map作业,所以这也非常快。
当然,如果新的数据足够小,你可以在每一个map作业中将其读入,并且保持新记录(在RAM中做了排序)在合适的数量范围内,这样就可以在RAM中执行合并。这可以让你避免为新数据进行排序的步骤。类似于这种合并的优化,正是Pig和Hive中对开发人员隐藏的大量细节部分。
策略2:使用HDFS和Hbase
在一篇名为“工程云系统中一种新颖的删除重复数据技术”的论文中,Zhe Sun, Jun Shen, Jianming Young共同提出了一种使用HDFS和Hbase的方法,内容如下:
使用MD5和SHA-1哈希函数计算文件的哈希值,然后将值传递给Hbase
将新的哈希值与现有的值域比较,如果新值已经存在于Hbase去重复表中,HDFS会检查链接的数量,如果数量不为零时,哈希值对应的计数器将增加1。如果数量是零或哈希值在之前的去重复表中不存在,HDFS会要求客户端上传文件并更新文件的逻辑路径。
HDFS将存储由用户上传的源文件,以及相应的链接文件,这些链接文件是自动生成的。链接文件中记录了源文件的哈希值和源文件的逻辑路径。
要注意使用这种方法中的一些关键点:
文件级的重复数据删除需要保持索引数量尽可能小,这样可以有高效的查找效率。
MD5和SHA-1需要结合使用从而避免偶发性的碰撞。
策略3:使用HDFS,MapReduce和存储控制器
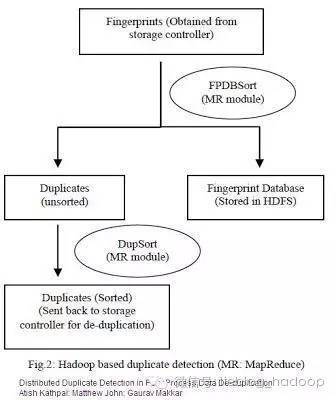
由Netapp的工程师AshishKathpal、GauravMakkar以及Mathew John三人联合,在一篇名为“在后期处理重复数据删除的分布式重复检测方式”的文章中,提出通过使用HadoopMapReduce的重复检测机制来替代Netapp原有的重复检测环节,文中提到的基于重复检测的Hadoop工作流包含如下几个环节:
将数据指纹(Fingerprint)由存储控制器迁移到HDFS
生成数据指纹数据库,并在HDFS上***存储该数据库
使用MapReduce从数据指纹记录集中筛选出重复记录,并将去重复后的数据指纹表保存回存储控制器。
数据指纹是指存储系统中文件块经过计算后的哈希索引,通常来说数据指纹要比它代表的数据块体积小的多,这样就可以减少分布式检测时网络中的数据传输量。
策略4:使用Streaming,HDFS,MapReduce
对于Hadoop和Streaming的应用集成,基本上包含两种可能的场景。以IBM Infosphere Streams和BigInsights集成为例,场景应该是:
1. Streams到Hadoop的流程:通过控制流程,将Hadoop MapReduce模块作为数据流分析的一部分,对于Streams的操作需要对更新的数据进行检查并去重,并可以验证MapReduce模型的正确性。
众所周知,在数据摄入的时候对数据进行去重复是最有效的,因此在Infosphere Streams中对于某个特定时间段或者数量的记录会进行去重复,或者识别出记录的增量部分。接着,经过去重的数据将会发送给Hadoop BigInsights用于新模型的建立。

2. Hadoop到Streams的流程:在这种方式中,Hadoop MapReduce用于移除历史数据中的重复数据,之后MapReduce模型将会更新。MapReduce模型作为Streams中的一部分被集成,针对mid-stream配置一个操作符(operator),从而对传入的数据进行处理。
策略5:结合块技术使用MapReduce
在莱比锡大学开发的一个原型工具Dedoop(Deduplication with Hadoop)中,MapReduce应用于大数据中的实体解析处理,到目前为止,这个工具囊括了MapReduce在重复数据删除技术中最为成熟的应用方式。
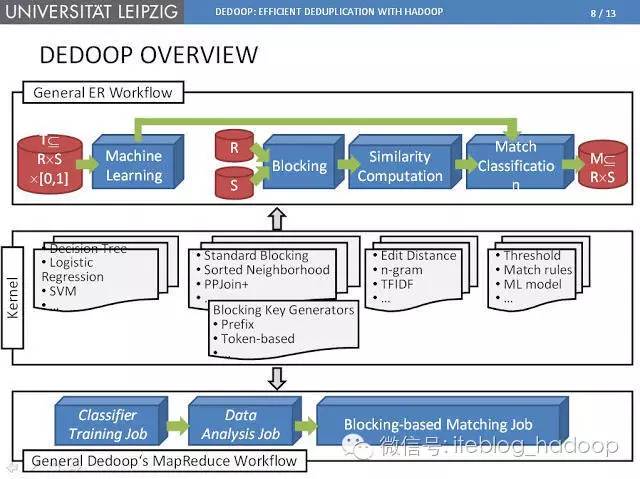
基于实体匹配的分块是指将输入数据按照类似的数据进行语义分块,并且对于相同块的实体进行限定。
实体解析处理分成两个MapReduce作业:分析作业主要用于统计记录出现频率,匹配作业用于处理负载均衡以及近似度计算。另外,匹配作业采用“贪婪模式”的负载均衡调控,也就是说匹配任务按照任务处理数据大小的降序排列,并做出最小负载的Reduce作业分配。
Dedoop还采用了有效的技术来避免多余的配对比较。它要求MR程序必须明确定义出哪个Reduce任务在处理哪个配对比较,这样就无需在多个节点上进行相同的配对比较。
关于“MapReduce+HDFS海量数据去重的策略有哪些”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/X79DOUtXCa6SH1VoM8DP3A



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



