这篇文章跟大家分析一下“Apache Kylin优化中如何进行聚合组原理解析”。内容详细易懂,对“Apache Kylin优化中如何进行聚合组原理解析”感兴趣的朋友可以跟着小编的思路慢慢深入来阅读一下,希望阅读后能够对大家有所帮助。下面跟着小编一起深入学习“Apache Kylin优化中如何进行聚合组原理解析”的知识吧。
“随着维度数目的增加,Cuboid 的数量会爆炸式地增长。为了缓解 Cube 的构建压力,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等。”
众所周知,Apache Kylin 的主要工作就是为源数据构建 N 个维度的 Cube,实现聚合的预计算。理论上而言,构建 N 个维度的 Cube 会生成 2N 个 Cuboid, 如图 1 所示,构建一个 4 个维度(A,B,C, D)的 Cube,需要生成 16 个Cuboid。
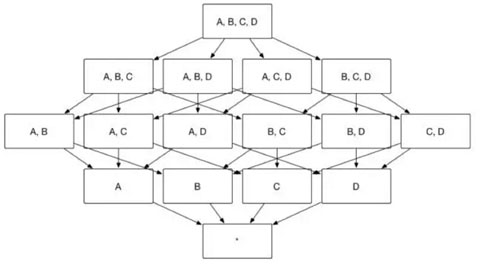
图1
随着维度数目的增加 Cuboid 的数量会爆炸式地增长,不仅占用大量的存储空间还会延长 Cube 的构建时间。为了缓解 Cube 的构建压力,减少生成的 Cuboid 数目,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等,本系列将深入讲解这些高级设置的含义及其适用的场景。
本文将着重介绍聚合组的实现原理与应用场景实例。
聚合组(Aggregation Group)
用户根据自己关注的维度组合,可以划分出自己关注的组合大类,这些大类在 Apache Kylin 里面被称为聚合组。例如图 1 中展示的 Cube,如果用户仅仅关注维度 AB 组合和维度 CD 组合,那么该 Cube 则可以被分化成两个聚合组,分别是聚合组 AB 和聚合组 CD。如图 2 所示,生成的 Cuboid 数目从 16 个缩减成了 8 个。
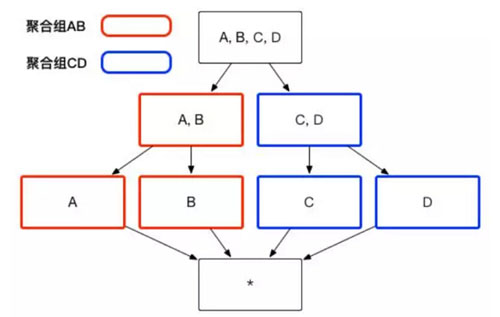
图2
用户关心的聚合组之间可能包含相同的维度,例如聚合组 ABC 和聚合组 BCD 都包含维度 B 和维度 C。这些聚合组之间会衍生出相同的 Cuboid,例如聚合组 ABC 会产生 Cuboid BC,聚合组 BCD 也会产生 Cuboid BC。这些 Cuboid不会被重复生成,一份 Cuboid 为这些聚合组所共有,如图 3 所示。
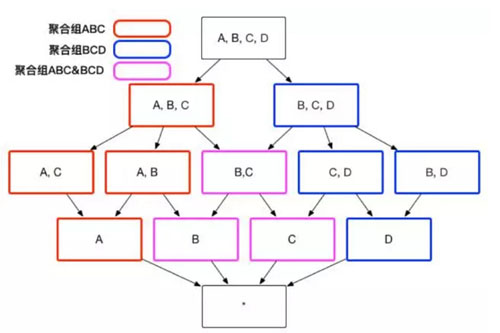
图3
有了聚合组用户就可以粗粒度地对 Cuboid 进行筛选,获取自己想要的维度组合。
应用实例
假设创建一个交易数据的 Cube,它包含了以下一些维度:顾客 ID buyer_id 交易日期 cal_dt、付款的方式 pay_type 和买家所在的城市 city。有时候,分析师需要通过分组聚合 city、cal_dt 和 pay_type 来获知不同消费方式在不同城市的应用情况;有时候,分析师需要通过聚合 city 、cal_dt 和 buyer_id,来查看顾客在不同城市的消费行为。在上述的实例中,推荐建立两个聚合组,包含的维度和方式如图 4 :
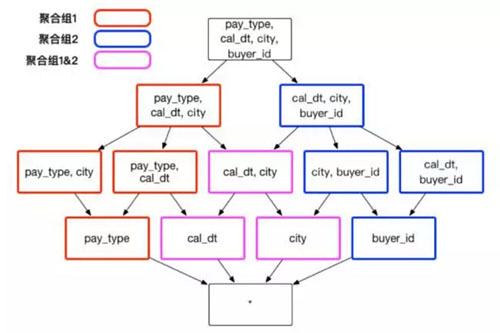
聚合组 1: [cal_dt, city, pay_type]
聚合组 2: [cal_dt, city, buyer_id]
在不考虑其他干扰因素的情况下,这样的聚合组将节省不必要的 3 个 Cuboid: [pay_type, buyer_id]、[city, pay_type, buyer_id] 和 [cal_dt, pay_type, buyer_id] 等,节省了存储资源和构建的执行时间。
Case 1:
SELECT cal_dt, city, pay_type, count(*) FROM table GROUP BY cal_dt, city, pay_type 则将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case2:
SELECT cal_dt, city, buy_id, count(*) FROM table GROUP BY cal_dt, city, buyer_id 则将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case3 如果有一条不常用的查询:
SELECT pay_type, buyer_id, count(*) FROM table GROUP BY pay_type, buyer_id 则没有现成的完全匹配的 Cuboid。
此时,Apache Kylin 会通过在线计算的方式,从现有的 Cuboid 中计算出最终结果。
Apache Kylin 作为一种多维分析工具,其采用预计算的方法,利用空间换取时间,提高查询效率。
关于Apache Kylin优化中如何进行聚合组原理解析就分享到这里啦,希望上述内容能够让大家有所提升。如果想要学习更多知识,请大家多多留意小编的更新。谢谢大家关注一下亿速云网站!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





