еҰӮдҪ•зҗҶи§ЈSQL Server SQLжҖ§иғҪдјҳеҢ–дёӯзҡ„еҸӮж•°еҢ–
еҰӮдҪ•зҗҶи§ЈSQL Server SQLжҖ§иғҪдјҳеҢ–дёӯзҡ„еҸӮж•°еҢ–пјҢеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
ж•°жҚ®еә“еҸӮж•°еҢ–зҡ„жЁЎејҸ
ж•°жҚ®еә“зҡ„еҸӮж•°еҢ–жңүдёӨз§Қж–№ејҸпјҢз®ҖеҚ•пјҲsimpleпјүе’ҢејәеҲ¶пјҲforcedпјүпјҢй»ҳи®Өзҡ„еҸӮж•°еҢ–й»ҳи®ӨжҳҜвҖңз®ҖеҚ•вҖқпјҢз®ҖеҚ•жЁЎејҸдёӢпјҢеҰӮжһңжҜҸж¬ЎеҸ‘иҝҮжқҘзҡ„SQLпјҢйҷӨйқһе®Ңе…ЁдёҖж ·пјҢеҗҰеҲҷе°ұйҮҚзј–иҜ‘е®ғпјҲзү№ж®Ҡжғ…еҶөдјҡиҮӘеҠЁеҸӮж•°еҢ–пјҢжӯЈжҳҜжң¬ж–ҮжғіиҜҙзҡ„йҮҚзӮ№пјү
ејәеҲ¶жЁЎејҸе°ұжҳҜе°Ҷadhoc SQLејәеҲ¶еҸӮж•°еҢ–пјҢйҒҝе…ҚжҜҸж¬ЎиҝҗиЎҢзҡ„ж—¶еҖҷеӣ дёәеҸӮж•°еҖјзҡ„дёҚеҗҢиҖҢйҮҚзј–иҜ‘пјҢиҝҷйҮҢдёҚиҜҰз»ҶиҜҙжҳҺгҖӮ
иҝҷйҰ–е…ҲиҰҒж„ҹи°ўвҖңжҪҮж№ҳйҡҗиҖ…вҖқеӨ§зҘһзҡ„жҸҗзӨәпјҢеҪ“ж—¶д№ҹжҳҜйҒҮеҲ°дёҖдёӘе®һйҷ…й—®йўҳпјҢеҸ‘зҺ°жү§иЎҢи®ЎеҲ’еҜ№ж•°жҚ®иЎҢзҡ„йў„дј°пјҢжҖҺд№ҲйғҪдёҚеҜ№пјҢжңүи§ӮеҜҹеҲ°ж— и®әжҖҺд№Ҳж”№еҸҳеҸӮж•°пјҢSQLиҜӯеҸҘжү§иЎҢеүҚйғҪжІЎжңүйҮҚзј–иҜ‘пјҢз–‘жғ‘дәҶеҘҪдёҖдјҡпјҢиҝҷдёӘй—®йўҳжӯЈжҳҜз®ҖеҚ•еҸӮж•°еҢ–жЁЎејҸдёӢпјҢеҜ№жҹҗдәӣSQLиҮӘеҠЁеҸӮж•°еҢ–йҖ жҲҗжү§иЎҢи®ЎеҲ’йҮҚз”Ёеј•иө·зҡ„пјҢд№ҹжҳҜжң¬ж–ҮжғіиЎЁиҫҫзҡ„йҮҚзӮ№гҖӮ
иҝҷдёӘй—®йўҳд№ӢеүҚе°ұеҶҷиҝҮпјҢеҪ“ж—¶д№ҹеҸӘжҳҜзңӢд№ҰдёҠзҗҶи®әдёҠиҝҷд№ҲиҜҙзҡ„пјҢжІЎжңүжғіеҲ°е…¶еёҰжқҘзҡ„еҪұе“ҚпјҢиҜҘеҸӮж•°жҳҜдёҖдёӘж•°жҚ®зә§еҲ«зҡ„йҖүйЎ№пјҢи®ҫзҪ®жғ…еҶөеҸҜд»ҘеҸӮиҖғдёӢеӣҫ
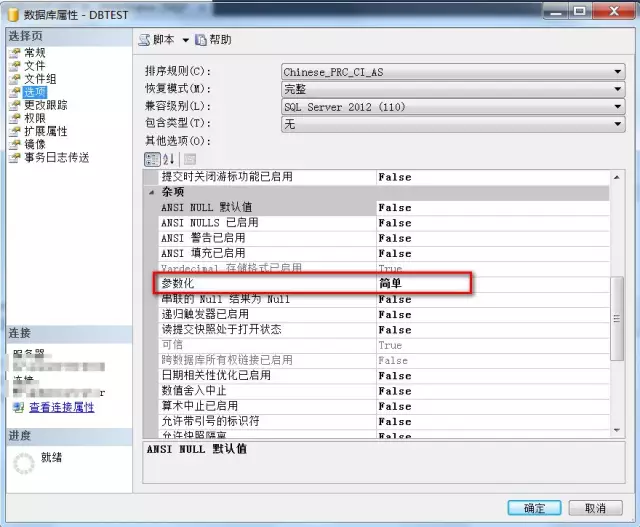
д»Җд№Ҳжғ…еҶөдёӢдјҡиҮӘеҠЁеҸӮж•°еҢ–
з®ҖеҚ•еҸӮж•°еҢ–жЁЎејҸдёӢпјҢеҜ№дәҺжңүдё”еҸӘжңүдёҖз§Қжү§иЎҢж–№ејҸзҡ„Adhoc SQLиҜӯеҸҘпјҢSQL ServerдјҡиҮӘеҠЁеҸӮж•°еҢ–е®ғпјҢд»ҺиҖҢиҫҫеҲ°йҮҚз”Ёжү§иЎҢи®ЎеҲ’зҡ„зӣ®зҡ„гҖӮ
究з«ҹе“Әдәӣзұ»еһӢзҡ„SQLдјҡиў«иҮӘеҠЁеҸӮж•°еҢ–пјҢеҗҺйқўдјҡдёҫдҫӢиҜҙжҳҺгҖӮ
иҮӘеҠЁеҸӮж•°еҢ–дјҡеӯҳеңЁе“Әдәӣй—®йўҳ
еңЁз®ҖеҚ•жЁЎејҸдёӢпјҢSQLеҜ№дәҺжҹҗдәӣSQLдјҡиҮӘеҠЁеҸӮж•°еҢ–д»–пјҢйҒҝе…ҚжҜҸж¬ЎйғҪйҮҚзј–иҜ‘гҖӮ
SQL Server иҮӘеҠЁеҸӮж•°еҢ–SQLиҜӯеҸҘзҡ„иЎҢдёәпјҢиғҪеӨҹйҒҝе…ҚдёҖдәӣйҮҚзј–иҜ‘пјҢеҺҹжң¬д№ҹжҳҜеҮәдәҺвҖңеҘҪж„ҸвҖқпјҢдҪҶжҳҜиҝҷз§ҚвҖңеҘҪж„ҸвҖқеҫҖеҫҖдёҚдёҖе®ҡжҖ»жҳҜз»ҷжҲ‘们еёҰжқҘеҘҪеӨ„гҖӮ
дёҫдҫӢиҜҙжҳҺд»Җд№Ҳжғ…еҶөдёӢдјҡиҮӘеҠЁеҸӮж•°еҢ–
е…ҲйҖ дёҖдёӘз®ҖеҚ•зҡ„жөӢиҜ•зҺҜеўғ
create table TestAuotParameter ( id int not null, col2 varchar(50) ) GO declare @i int=0 while @i100000 begin insert into TestAuotParameter values (@i, NEWID()) set @i=@i+1 end GO create unique index idx_id on TestAuotParameter(id) GO
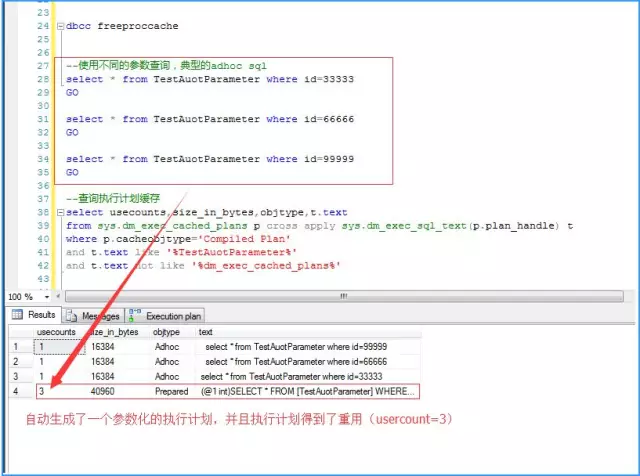
д№ӢжүҖд»ҘиҮӘеҠЁеҸӮж•°еҢ–дәҶSQLиҜӯеҸҘпјҢе°ұжҳҜеӣ дёәselect * from TestAuotParameter where id=33333 пјҲ66666,99999пјүиҝҷеҸҘSQLиҜӯеҸҘпјҢеңЁеҪ“еүҚзҡ„ж•°жҚ®йҮҸдёӢе’Ң***зҙўеј•зҡ„зү№зӮ№пјҢеҶіе®ҡдәҶжңүдё”еҸӘжңүдёҖз§Қй«ҳж•Ҳзҡ„жү§иЎҢж–№ејҸпјҲд№ҹе°ұжҳҜзҙўеј•жҹҘжүҫпјүиҝҷйҮҢиҜҙжңүдё”еҸӘжңүдёҖз§Қж–№ејҸжҳҜиЎЁдёӯж•°жҚ®йҮҸзӣёеҜ№иҫғеӨҡпјҢеҸҲеӣ дёәidx_idиҝҷдёӘзҙўеј•жҳҜuniqueзҡ„гҖӮеҰӮжһңдёҚжҳҜuniqueзҡ„пјҢйӮЈд№Ҳжғ…еҶөе°ұдёҚеҗҢдәҶпјҢдёӢйқўжқҘи§ЈйҮҠд»Җд№ҲжҳҜжңүдё”еҸӘжңүдёҖз§Қй«ҳж•Ҳзҡ„жү§иЎҢи®ЎеҲ’
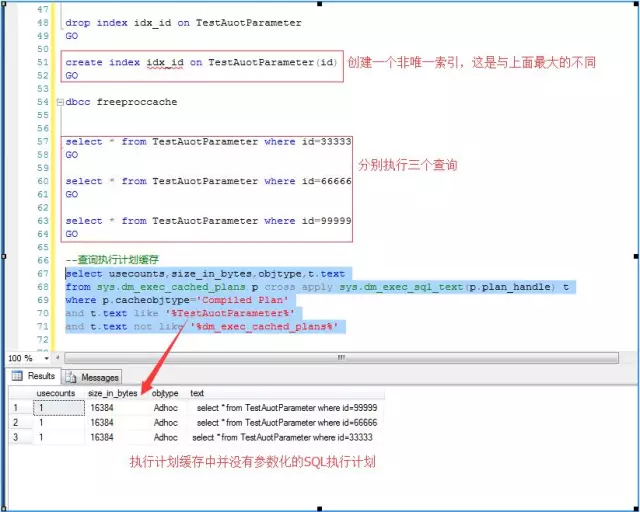
еҰӮдёӢжҲӘеӣҫпјҡеҗҢж ·зҡ„жөӢиҜ•пјҢжҲ‘еҲ йҷӨidдёҠзҡ„***зҙўеј•пјҢеҲӣе»әдёәйқһ***зҙўеј•пјҢеҶҚеҒҡеҗҢж ·зҡ„жөӢиҜ•пјҢе°ұдјҡеҸ‘зҺ°жү§иЎҢеҗҢж ·зҡ„SQL并没жңүиў«иҮӘеҠЁеҸӮж•°еҢ–
иҝҷйҮҢи§ЈйҮҠдёҖдёӢеҺҹеӣ пјҢзҙўеј•зұ»еһӢжҖҺд№Ҳи·ҹжү§иЎҢи®ЎеҲ’зј“еӯҳжүҜдёҠдәҶпјҹ
еҜ№дәҺйқһ***зҙўеј•пјҢжңүеҸҜиғҪдҪңеҒҡеј•жҹҘжүҫжҳҜй«ҳж•Ҳзҡ„пјҢжңүеҸҜиғҪеҒҡе…ЁиЎЁжү«жҸҸжҳҜй«ҳж•Ҳзҡ„пјҲжҜ”еҰӮжҹҗдёӘIDзҡ„ж•°жҚ®еҲҶеёғзҡ„зү№еҲ«еӨҡпјүжӯӨж—¶жү§иЎҢи®ЎеҲ’жңүеҸҜиғҪжҳҜеӨҡж ·зҡ„пјҢдёҚд»…д»…еҸӘжңүдёҖз§Қж–№ејҸпјҢжүҖд»Ҙе°ұдёҚдјҡиҮӘеҠЁеҸӮж•°еҢ–SQL
иҮӘеҠЁеҸӮж•°еҢ–еӯҳеңЁзҡ„й—®йўҳ
иҮӘеҠЁеҸӮж•°еҢ–еҘҪеӨ„并дёҚз”ЁеӨҡиҜҙпјҢеӣ дёәеҸҜд»ҘйҮҚз”Ёзј“еӯҳзҡ„жү§иЎҢи®ЎеҲ’пјҢйҒҝе…ҚдәҶжҜҸж¬ЎеҸӮж•°еҖјдёҚдёҖж ·е°ұйҮҚзј–иҜ‘зҡ„й—®йўҳгҖӮиҜҙеҲ°жү§иЎҢи®ЎеҲ’йҮҚз”ЁпјҢдёҚеҫ—дёҚиҜҙзҡ„дёҖдёӘиҜқйўҳе°ұжҳҜparameter sniffпјҢеҳҙзҡ®еӯҗйғҪзЈЁз ҙзҡ„й—®йўҳдәҶ
жІЎй”ҷпјҢиҮӘеҠЁеҸӮж•°еҢ–еӣ дёәдёҚеҗҢеҸӮж•°дјҡйҮҚз”Ё***ж¬Ўзј–иҜ‘з”ҹжҲҗзҡ„жү§иЎҢи®ЎеҲ’пјҢеҫҲжңүеҸҜиғҪйҖ жҲҗparameter sniffй—®йўҳпјҢд»ҘеҸҠparameter sniffиЎҚз”ҹеҮәжқҘзҡ„е…¶д»–й—®йўҳ
еҗҢж ·з”ЁдёҖдёӘдҫӢеӯҗжқҘеҒҡжј”зӨәпјҢиҜҘй—®йўҳжҳҜжңҖиҝ‘еңЁи§ӮеҜҹжү§иЎҢи®ЎеҲ’з»ҹи®ЎдҝЎжҒҜпјҲstatisticsпјүйў„дј°й—®йўҳж—¶йҒҮеҲ°зҡ„дёҖдёӘй—®йўҳпјҢи®©жҲ‘еӣ°жғ‘дәҶеҘҪдёҖдјҡпјҢиҝҷйҮҢеҶҚж¬Ўж„ҹи°ўжҪҮж№ҳйҡҗиҖ…гҖӮ
иҜҘй—®йўҳеҗҢж ·д№ҹжҳҜеӣ дёәиҮӘеҠЁеҸӮж•°еҢ–дәҶSQLиҜӯеҸҘпјҢйҖ жҲҗжү§иЎҢи®ЎеҲ’йҮҚз”ЁпјҢд»ҺиҖҢйҖ жҲҗдёҖдёӘжһҒе…¶з®ҖеҚ•зҡ„SQLжү§иЎҢж•ҲзҺҮеңЁжҹҗдәӣжғ…еҶөдёӢиҫғдҪҺзҡ„жғ…еҶөпјҢдёәд»Җд№ҲиҮӘеҠЁеҢ–еҸӮж•°зҡ„еҺҹеӣ и·ҹдёҠиҝ°зұ»дјјпјҢйғҪжҳҜжңүдё”еҸӘжңүдёҖз§Қжү§иЎҢж–№ејҸпјҲзҙўеј•жҹҘжүҫпјүзҡ„жғ…еҶөдёӢпјҢдёҚеҗҢеҸӮж•°жү§иЎҢи®ЎеҲ’йҮҚз”ЁйҖ жҲҗеҜ№ж•°жҚ®иЎҢзҡ„й”ҷиҜҜйў„дј°гҖӮжөӢиҜ•д№ӢеүҚжё…з©әдёҖдёӢзј“еӯҳжү§иЎҢи®ЎеҲ’пјҢи§ӮеҜҹдёҚеҗҢжҹҘиҜўжқЎд»¶дёӢзҡ„е®һйҷ…жү§иЎҢи®ЎеҲ’еҜ№ж•°жҚ®иЎҢзҡ„йў„дј°
еҰӮдёӢжҹҘиҜўжқЎд»¶пјҡ
1пјҢеҲқе§ӢжҹҘиҜўжқЎд»¶дёәпјҡCreateDate>’2016-6-1′ and CreateDate

2пјҢе°ҶжҹҘиҜўжқЎд»¶жӣҙж–°дёәпјҡCreateDate>’2016-6-1′ and CreateDate

3пјҢе°ҶжҹҘиҜўжқЎд»¶жӣҙж–°дёәпјҡCreateDate>’2016-6-1′ and CreateDate
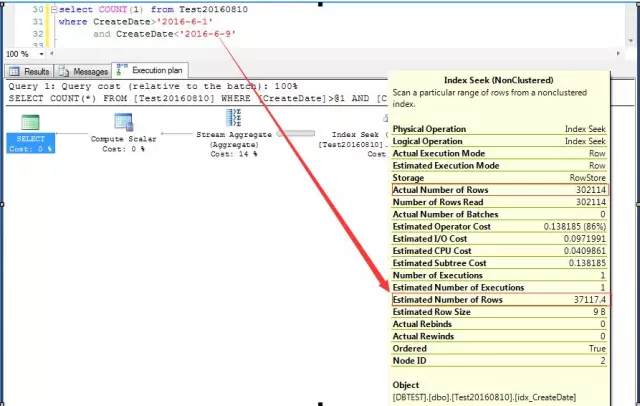
еҸ‘зҺ°жІЎжңүпјҢеӣ дёәжҹҘиҜўж—¶й—ҙж®өжңүеҸҳеҢ–пјҢе®һйҷ…иЎҢж•°д№ҹжңүеҸҳеҢ–пјҢдҪҶжҳҜдёҚз®Ўе®һйҷ…иЎҢж•°еӨҡе°‘пјҢйў„дј°иЎҢж•°жҖ»жҳҜдёә***ж¬Ўжү§иЎҢйў„дј°зҡ„иЎҢж•°гҖӮ
иҝҷиӮҜе®ҡдёҚеҜ№еҗ§пјҹйҡҸдҫҝеёҰе…Ҙд»Җд№ҲжқЎд»¶пјҢйў„дј°иЎҢж•°йғҪжҳҜ37117пјҢеҪ“ж—¶дёҖдёӢеӯҗи’ҷдәҶпјҢжҖҺд№ҲжҜҸж¬Ўжү§иЎҢSQLеҜ№ж•°жҚ®иЎҢзҡ„йў„дј°йғҪжҳҜдёҖж ·зҡ„пјҹ
е…¶е®һиҝҷдёӘй—®йўҳи·ҹдёҖејҖе§ӢдёҫдҫӢзҡ„дёҖж ·пјҢйғҪжҳҜSQLиҜӯеҸҘиў«иҮӘеҠЁеҸӮж•°еҢ–дәҶпјҢеӣ жӯӨйҖ жҲҗдәҶжү§иЎҢи®ЎеҲ’йҮҚз”ЁпјҢжү§иЎҢи®ЎеҲ’йҮҚз”ЁпјҢеҜјиҮҙй”ҷиҜҜең°йў„дј°е®һйҷ…жҹҘиҜўзҡ„ж•°жҚ®иЎҢж•°гҖӮ
еҰӮдҪ•и§ЈеҶіиҮӘеҠЁеҸӮж•°еҢ–йҖ жҲҗй”ҷиҜҜең°йҮҚз”Ёжү§иЎҢи®ЎеҲ’зҡ„й—®йўҳ
еҫҲеӨҡй—®йўҳжүҫеҲ°дәҶзңҹжӯЈзҡ„еҺҹеӣ пјҢи§ЈеҶіиө·жқҘеҫҖеҫҖ并дёҚйҡҫпјҢиҝҷдёӘй—®йўҳзҡ„еҺҹеӣ жҳҜжү§иЎҢи®ЎеҲ’йҮҚз”ЁйҖ жҲҗзҡ„пјҢйӮЈд№ҲжҲ‘们еҸӘйңҖиҰҒи§ЈеҶіжү§иЎҢи®ЎеҲ’йҮҚз”Ёзҡ„й—®йўҳеҚіеҸҜгҖӮд№ҹе°ұжҳҜдёҚи®©д»–йҮҚз”Ёжү§иЎҢи®ЎеҲ’пјҢеҸӘйңҖиҰҒеңЁSQLиҜӯеҸҘдёӯеҠ дёҖдёӘжҸҗзӨәеҚіеҸҜпјҢд№ҹеҚіпјҡselect COUNT(1) from Test20160810 where CreateDate>’2016-6-1′ and CreateDateOPTION(RECOMPILE)
еҺҹеӣ е°ұеңЁдәҺеҠ дёҠOPTION(RECOMPILE)иҝҷдёӘжҹҘиҜўжҸҗзӨәд№ӢеҗҺпјҢдёҚзј“еӯҳSQLзҡ„жү§иЎҢи®ЎеҲ’зј“еӯҳпјҢжІЎжңүдәҶжү§иЎҢи®ЎеҲ’зј“еӯҳпјҢд№ҹе°ұжІЎеҫ—йҮҚз”ЁдәҶ
жҜ”еҰӮиҝҷдёӘжҹҘиҜўпјҢеңЁжҹҘиҜўиҜӯеҸҘдёӯеҠ е…ҘOPTION(RECOMPILE)жҹҘиҜўжҸҗзӨәпјҢи®©е…¶жү§иЎҢд№ӢеүҚйҮҚзј–иҜ‘SQLиҜӯеҸҘпјҢд»–е°ұеҸҜд»ҘжӯЈзЎ®ең°йў„дј°ж•°жҚ®иЎҢдәҶгҖӮ
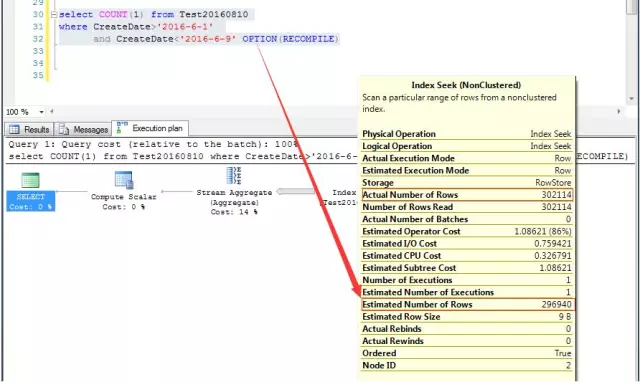
йҖҡиҝҮдёҖдёӘе®һйҷ…жЎҲдҫӢиҜҙжҳҺдәҶд»Җд№ҲжҳҜз®ҖеҚ•еҸӮж•°жЁЎејҸдёӢзҡ„иҮӘеҠЁеҢ–еҸӮж•°пјҢиҮӘеҠЁеҢ–еҸӮж•°дјҡеёҰжқҘе“Әдәӣй—®йўҳпјҢд»ҘеҸҠеҰӮдҪ•и§ЈеҶіпјҢй—®йўҳжң¬иә«йқһеёёз®ҖеҚ•пјҢеҰӮжһңдёҚжіЁж„ҸиҝҳжҳҜдјҡеҒ¶е°”иҝҳжҳҜдјҡеҮәзҺ°еӣ°жғ‘зҡ„гҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ





