这篇文章将为大家详细讲解有关如何进行数据库高可用架构的思路分析,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
数据库高可用架构对于我们这些应用端开发的人来说是一个比较陌生的领域,是在具体的数据库产品之上搭建的环境,需要像DBA这样对数据库产品有足够的了解才能有所涉及,虽然不能深入其中,但可以通过一些经典的高可用架构学习其中的思想。就我所了解到的有以下几种:
MySQL Replication
MySQL Cluster
Oracle RAC
IBM HACMP
Oracle ASM
MySQL Replication
MySQL Replication就是通过异步复制多个copy以达到提高可用性的目的,常规的复制架构有以下几种:
Master-Slaves
Master-Master
Master-Master-Salves
1)Master-Slaves
Master- Slaves是最常用的提高可用的方法,特别是在互联网应用中,读远远大于写,因此提高读的可用性是首当其中的,Master-Slaves就是让写的操作集中在一台数据库Master上,然后这个Master会把更新的操作复制到其他数据库Slaves上,读的操作都发生在Slaves上,架构图如下所示:
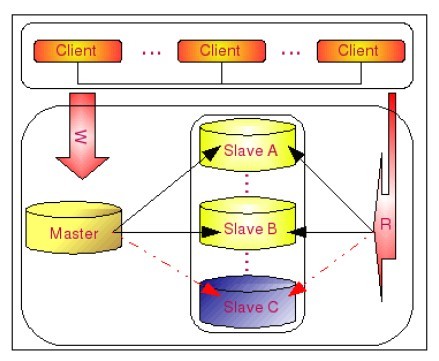
如上图在SlaveC不可用时,读和写都不会中断,等SlaveC恢复后会自动同步丢失的数据,又能重新投入运转,可维护性非常好。但如果Master有问题就麻烦了,因此它只解决了读的高可用性,但不保证写的高可用性。
2)Master-Master
为解决上面谈的写的高可用性,MySQL提供了Master-Master的复制架构,如下所示:
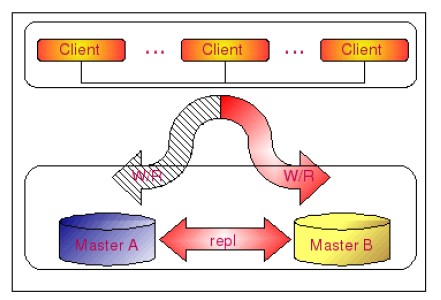
一般说来都向MasterA写,MasterA同步数据到MasterB,当MasterA有问题时,会自动切换到MasterB,等MasterA恢复时,MasterB同步数据到MasterA
3)Master-Master-Salves
Master-Master-Salves是结合上面两种方案,是一种同时提供读和写高可用的复制架构,如下图所示:
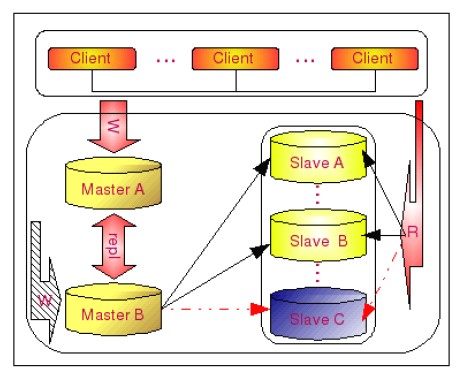
MySQL Cluster
MySQL Cluster主要由三个部分组成:
SQL服务器节点
NDB数据存储节点
监控和管理节点
三个部门的组成结构如下图所示:
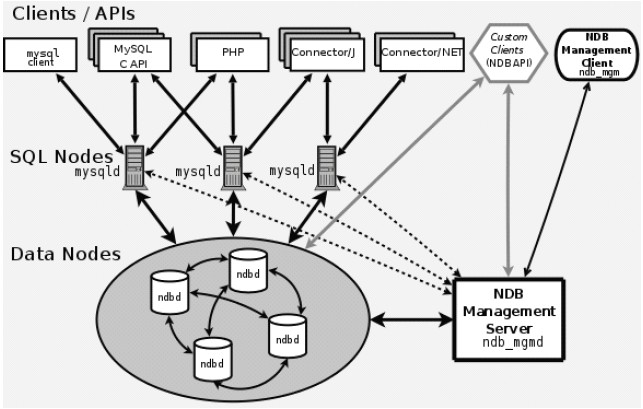
这样的分层也是由MySQL本身把SQL处理和存储分开的架构相关系的。
这样一来MySQL Cluster就可以分别在SQL处理和存储两个层次上做高可用的复制策略。在SQL处理层次上,比较容易做集群,因为这些SQL处理是无状态性的,完全可以通过增加机器的方式增强可用性。在存储层次上,通过对每个节点进行备份的形式增加存储的可用性,这类似与MySQL Replication,结构图如下所示:
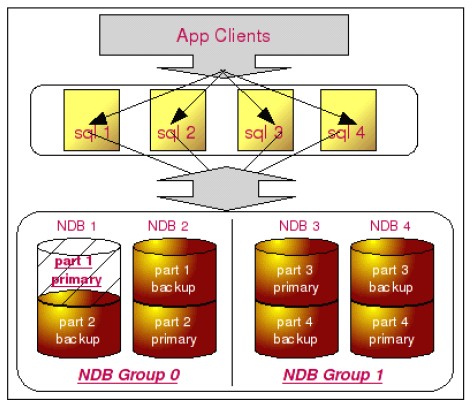
Oracle RAC
Oracle RAC和MySQL Cluster有些相似,但主要集中在SQL处理层的高可用性,而在存储上体现不多,结构图如下所示:
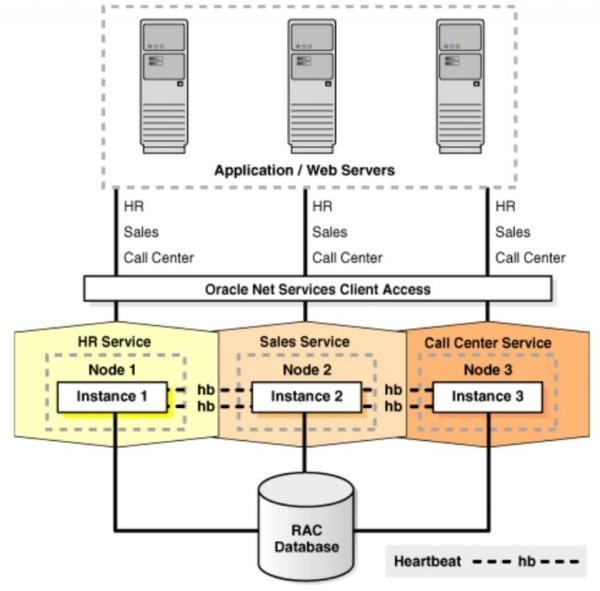
它的主要优点就是对应用透明,并且通过Heartbeat检测可用性非常高,主要缺点就是存储是共享的,存储上可扩展能力不足。
IBM HACMP
IBM HACMP与Oracle RAC也是类似,主要用于双机互备,运行流程如下所示:
1)作为双机系统的两台服务器(主机A和B)同时运行在Hacmp环境中;
2)服务器除正常运行自机的应用外,同时又作为对方的备份主机;
3)两台主机系统(A和B)在整个运行过程中,通过 “心跳线”相互监测对方的运行情况(包括系统的软硬件运行、网络通讯和应用运行情况等);
4)一旦发现对方主机的运行不正常(出故障)时,故障机上的应用就会立即停止运行,本机(故障机的备份机)就会立即在自己的机器上启动故障机上的应用,把故障机的应用及其资源(包括用到的IP地址和磁盘空间等)接管过来,使故障机上的应用在本机继续运行;
5)应用和资源的接管过程由Ha软件自动完成,无需人工干预;
6)当两台主机正常工作时,也可以根据需要将其中一台机上的应用人为切换到另一台机(备份机)上运行。
Oracle ASM
Oracle ASM主要提供存储的可扩展性,通过自动化的存储管理加上后端可扩展性的存储阵列达到高可用性,结构图如下所示:
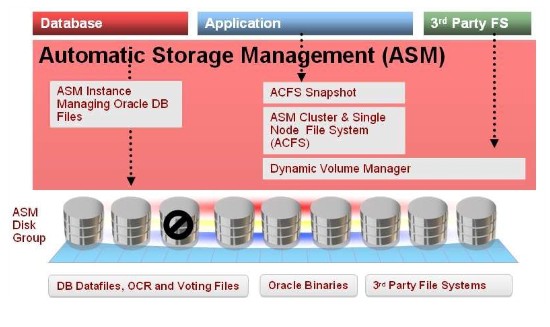
因此,可以尝试把Oracle RAC和ASM组合起来使用,同时提供SQL处理和存储的高可用性,这也是MySQL Cluster想达到的效果。
关于如何进行数据库高可用架构的思路分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



