小编给大家分享一下pandas中时序数据分组运算的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
我们在使用pandas分析处理时间序列数据时,经常需要对原始时间粒度下的数据,按照不同的时间粒度进行分组聚合运算,譬如基于每个交易日的股票收盘价,计算每个月的最低和最高收盘价。
而在pandas中,针对不同的应用场景,我们可以使用resample()、groupby()以及Grouper()来非常高效快捷地完成此类任务。

在pandas中根据具体任务场景的不同,对时间序列进行分组聚合可通过以下两类方式实现:
resample原始的意思是「重采样」,可分为「上采样」与「下采样」,而我们通常情况下使用的都是「下采样」,也就是从高频的数据中按照一定规则计算出更低频的数据,就像我们一开始说的对每日数据按月汇总那样。
如果你熟悉pandas中的groupby()分组运算,那么你就可以很快地理解resample()的使用方式,它本质上就是在对时间序列数据进行“分组”,最基础的参数为rule,用于设置按照何种方式进行重采样,就像下面的例子那样:
import pandas as pd
# 记录了2013-02-08到2018-02-07之间每个交易日苹果公司的股价
AAPL = pd.read_csv('AAPL.csv', parse_dates=['date'])
# 以月为统计窗口计算每月股票最高收盘价
(
AAPL
.set_index('date') # 设置date为index
.resample('M') # 以月为单位
.agg({
'close': ['max', 'min']
})
)

可以看到,在上面的例子中,我们对index为日期时间类型的DataFrame应用resample()方法,传入的参数'M'是resample第一个位置上的参数rule,用于确定时间窗口的规则,譬如这里的字符串'M'就代表「月且聚合结果中显示对应月的最后一天」,常用的固化的时间窗口规则如下表所示:
| 规则 | 说明 |
|---|---|
| W | 星期 |
| M | 月,显示为当月最后一天 |
| MS | 月,显示为当月第一天 |
| Q | 季度,显示为当季最后一天 |
| QS | 季度,显示为当季第一天 |
| A | 年,显示为当年最后一天 |
| AS | 年,显示为当年第一天 |
| D | 日 |
| H | 小时T |
| T或min | 分钟 |
| S | 秒 |
| L或 ms | 毫秒 |
且这些规则都可以在前面添加数字实现倍数效果:
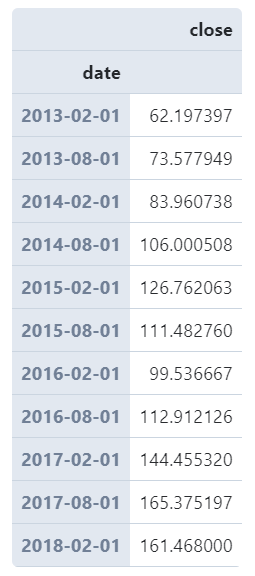
# 以6个月为统计窗口计算每月股票平均收盘价且显示为当月第一天
(
AAPL
.set_index('date') # 设置date为index
.resample('6MS') # 以6个月为单位
.agg({
'close': 'mean'
})
)
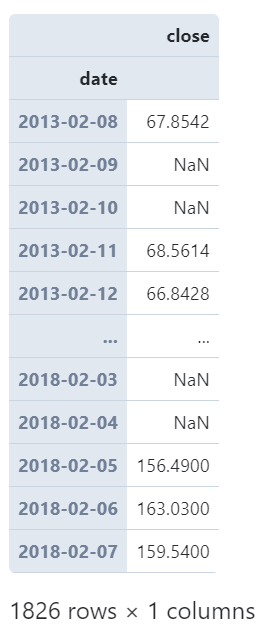
且resample()非常贴心之处在于它会自动帮你对齐到规整的时间单位上,譬如我们这里只有交易日才会有记录,如果我们设置的时间单位下无对应记录,也会为你保留带有缺失值记录的时间点:
(
AAPL
.set_index('date') # 设置date为index
.resample('1D') # 以1日为单位
.agg({
'close': 'mean'
})
)
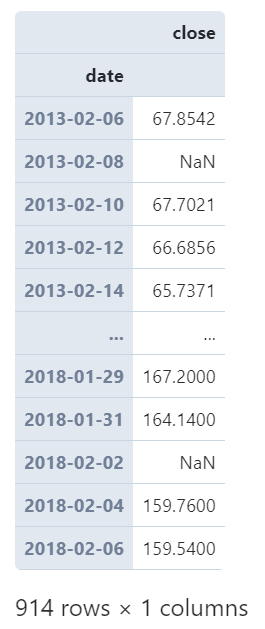
而通过参数closed我们可以为细粒度的时间单位设置区间闭合方式,譬如我们以2日为单位,将closed设置为'right'时,从第一行记录开始计算所落入的时间窗口时,其对应为时间窗口的右边界,从而影响后续所有时间单元的划分方式:
(
AAPL
.set_index('date') # 设置date为index
.resample('2D', closed='right')
.agg({
'close': 'mean'
})
)
而即使你的数据框index不是日期时间类型,也可以使用参数on来传入日期时间列名实现同样的效果。
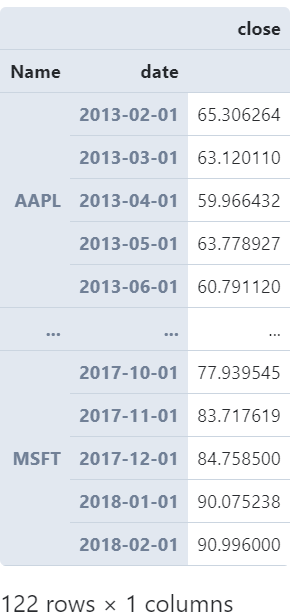
有些情况下,我们不仅仅需要利用时间类型列来分组,也可能需要包含时间类型在内的多个列共同进行分组,这种情况下我们就可以使用到Grouper()。
它通过参数freq传入等价于resample()中rule的参数,并利用参数key指定对应的时间类型列名称,但是可以帮助我们创建分组规则后传入groupby()中:
# 分别对苹果与微软每月平均收盘价进行统计
(
pd
.read_csv('AAPL&MSFT.csv', parse_dates=['date'])
.groupby(['Name', pd.Grouper(freq='MS', key='date')])
.agg({
'close': 'mean'
})
)
且在此种混合分组模式下,我们可以非常方便的配合apply、transform等操作,这里就不再赘述。
以上是“pandas中时序数据分组运算的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





