这篇文章将为大家详细讲解有关Spark Remote Shuffle Service最佳实践的示例分析,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
经过近半年的上线、运营,趣头条大数据团队和阿里云 EMR 团队共同开发的 RSS 可以完美解决 Spark Shuffle 面临的技术挑战,为集群的稳定性和容器化的落地提供强有力的保证,其业务价值主要体现在以下方面:
降本增效效果明显
SLA显著提升
作业执行效率显著提升
架构灵活性显著提升
业务场景与现状

当前大数据平台的挑战和思考
近半年大数据平台主要的业务指标是降本增效,一方面业务方希望离线平台每天能够承载更多的作业,另一方面我们自身有降本的需求,如何在降本的前提下支撑更多地业务量对于每个技术人都是非常大地挑战。熟悉Spark的同学应该非常清楚,在大规模集群场景下,Spark Shuffle在实现上有比较大的缺陷,体现在以下的几个方面:
Spark Shuffle Fetch过程存在大量的网络小包,现有的External Shuffle Service设计并没有非常细致的处理这些RPC请求,大规模场景下会有很多connection reset发生,导致FetchFailed,从而导致stage重算。
Spark Shuffle Fetch过程存在大量的随机读,大规模高负载集群条件下,磁盘IO负载高、CPU满载时常发生,极容易发生FetchFailed,从而导致stage重算。
重算过程会放大集群的繁忙程度,抢占机器资源,导致恶性循环严重,SLA完不成,需要运维人员手动将作业跑在空闲的Label集群。
计算和Shuffle过程架构不能拆开,不能把Shuffle限定在指定的集群内,不能利用部分SSD机器。
M*N次的shuffle过程:对于10K mapper,5K reducer级别的作业,基本跑不完。
NodeManager和Spark Shuffle Service是同一进程,Shuffle过程太重,经常导致NodeManager重启,从而影响Yarn调度稳定性。
以上的这些问题对于Spark研发同学是非常痛苦的,好多作业每天运行时长方差会非常大,而且总有一些无法完成的作业,要么业务进行拆分,要么跑到独有的Yarn集群中。除了现有面临的挑战之外,我们也在积极构建下一代基础架构设施,随着云原生Kubernetes概念越来越火,Spark社区也提供了Spark on Kubernetes版本,相比较于Yarn来说,Kubernetes能够更好的利用云原生的弹性,提供更加丰富的运维、部署、隔离等特性。但是Spark on Kubernetes目前还存在很多问题没有解决,包括容器内的Shuffle方式、动态资源调度、调度性能有限等等。我们针对Kubernetes在趣头条的落地,主要有以下几个方面的需求:
实时集群、OLAP集群和Spark集群之前都是相互独立的,怎样能够将这些资源形成统一大数据资源池。通过Kubernetes的天生隔离特性,更好的实现离线业务与实时业务混部,达到降本增效目的。
公司的在线业务都运行在Kubernetes集群中,如何利用在线业务和大数据业务的不同特点进行错峰调度,达成ECS的总资源量最少。
希望能够基于Kubernetes来包容在线服务、大数据、AI等基础架构,做到运维体系统一化。
因为趣头条的大数据业务目前全都部署在阿里云上,阿里云EMR团队和趣头条的大数据团队进行了深入技术共创,共同研发了Remote Shuffle Service(以下简称RSS),旨在解决Spark on Yarn层面提到的所有问题,并为Spark跑在Kubernetes上提供Shuffle基础组件。
Remote Shuffle Service设计与实现
基于上述背景,我们与阿里云EMR团队共同开发了Remote Shuffle Service。RSS可以提供以下的能力,完美的解决了Spark Shuffle面临的技术挑战,为我们集群的稳定性和容器化的落地提供了强有力的保证,主要体现在以下几个方面:
高性能服务器的设计思路,不同于Spark原有Shuffle Service,RPC更轻量、通用和稳定。
两副本机制,能够保证的Shuffle fetch极小概率(低于0.01%)失败。
合并shuffle文件,从M*N次shuffle变成N次shuffle,顺序读HDD磁盘会显著提升shuffle heavy作业性能。
减少Executor计算时内存压力,避免map过程中Shuffle Spill。
计算与存储分离架构,可以将Shuffle Service部署到特殊硬件环境中,例如SSD机器,可以保证SLA极高的作业。
完美解决Spark on Kubernetes方案中对于本地磁盘的依赖。
Spark RSS架构包含三个角色: Master, Worker, Client。Master和Worker构成服务端,Client以不侵入的方式集成到Spark ShuffleManager里(RssShuffleManager实现了ShuffleManager接口)。
Master的主要职责是资源分配与状态管理。
Worker的主要职责是处理和存储Shuffle数据。
Client的主要职责是缓存和推送Shuffle数据。
整体流程如下所示(其中ResourceManager和MetaService是Master的组件),如图2。

图2 RSS整体架构图
3.2.2 实现流程
下面重点来讲一下实现的流程:
RSS采用Push Style的shuffle模式,每个Mapper持有一个按Partition分界的缓存区,Shuffle数据首先写入缓存区,每当某个Partition的缓存满了即触发PushData。
Driver先和Master发生StageStart的请求,Master接受到该RPC后,会分配对应的Worker Partition并返回给Driver,Shuffle Client得到这些元信息后,进行后续的推送数据。
Client开始向主副本推送数据。主副本Worker收到请求后,把数据缓存到本地内存,同时把该请求以Pipeline的方式转发给从副本,从而实现了2副本机制。
为了不阻塞PushData的请求,Worker收到PushData请求后会以纯异步的方式交由专有的线程池异步处理。根据该Data所属的Partition拷贝到事先分配的buffer里,若buffer满了则触发flush。RSS支持多种存储后端,包括DFS和Local。若后端是DFS,则主从副本只有一方会flush,依靠DFS的双副本保证容错;若后端是Local,则主从双方都会flush。
在所有的Mapper都结束后,Driver会触发StageEnd请求。Master接收到该RPC后,会向所有Worker发送CommitFiles请求,Worker收到后把属于该Stage buffer里的数据flush到存储层,close文件,并释放buffer。Master收到所有响应后,记录每个partition对应的文件列表。若CommitFiles请求失败,则Master标记此Stage为DataLost。
在Reduce阶段,reduce task首先向Master请求该Partition对应的文件列表,若返回码是DataLost,则触发Stage重算或直接abort作业。若返回正常,则直接读取文件数据。
总体来讲,RSS的设计要点总结为3个层面:
采用PushStyle的方式做shuffle,避免了本地存储,从而适应了计算存储分离架构。
按照reduce做聚合,避免了小文件随机读写和小数据量网络请求。
做了2副本,提高了系统稳定性。
对于RSS系统,容错性是至关重要的,我们分为以下几个维度来实现:
PushData失败
当PushData失败次数(Worker挂了,网络繁忙,CPU繁忙等)超过MaxRetry后,Client会给Master发消息请求新的Partition Location,此后本Client都会使用新的Location地址,该阶段称为Revive。
若Revive是因为Client端而非Worker的问题导致,则会产生同一个Partition数据分布在不同Worker上的情况,Master的Meta组件会正确处理这种情形。
若发生WorkerLost,则会导致大量PushData同时失败,此时会有大量同一Partition的Revive请求打到Master。为了避免给同一个Partition分配过多的Location,Master保证仅有一个Revive请求真正得到处理,其余的请求塞到pending queue里,待Revive处理结束后返回同一个Location。
Worker宕机
当发生WorkerLost时,对于该Worker上的副本数据,Master向其peer发送CommitFile的请求,然后清理peer上的buffer。若Commit Files失败,则记录该Stage为DataLost;若成功,则后续的PushData通过Revive机制重新申请Location。
数据去重
Speculation task和task重算会导致数据重复。解决办法是每个PushData的数据片里编码了所属的mapId,attemptId和batchId,并且Master为每个map task记录成功commit的attemtpId。read端通过attemptId过滤不同的attempt数据,并通过batchId过滤同一个attempt的重复数据。
多副本
RSS目前支持DFS和Local两种存储后端。
在DFS模式下,ReadPartition失败会直接导致Stage重算或abort job。在Local模式,ReadPartition失败会触发从peer location读,若主从都失败则触发Stage重算或abort job。
大家可以看到RSS的设计中Master是一个单点,虽然Master的负载很小,不会轻易地挂掉,但是这对于线上稳定性来说无疑是一个风险点。在项目的最初上线阶段,我们希望可以通过SubCluster的方式进行workaround,即通过部署多套RSS来承载不同的业务,这样即使RSS Master宕机,也只会影响有限的一部分业务。但是随着系统的深入使用,我们决定直面问题,引进高可用Master。主要的实现如下:
首先,Master目前的元数据比较多,我们可以将一部分与ApplD+ShuffleId本身相关的元数据下沉到Driver的ShuffleManager中,由于元数据并不会很多,Driver增加的内存开销非常有限。
另外,关于全局负载均衡的元数据和调度相关的元数据,我们利用Raft实现了Master组件的高可用,这样我们通过部署3或5台Master,真正的实现了大规模可扩展的需求。
实际效果与分析
团队针对TeraSort,TPC-DS以及大量的内部作业进行了测试,在Reduce阶段减少了随机读的开销,任务的稳定性和性能都有了大幅度提升。
图3是TeraSort的benchmark,以10T Terasort为例,Shuffle量压缩后大约5.6T。可以看出该量级的作业在RSS场景下,由于Shuffle read变为顺序读,性能会有大幅提升。
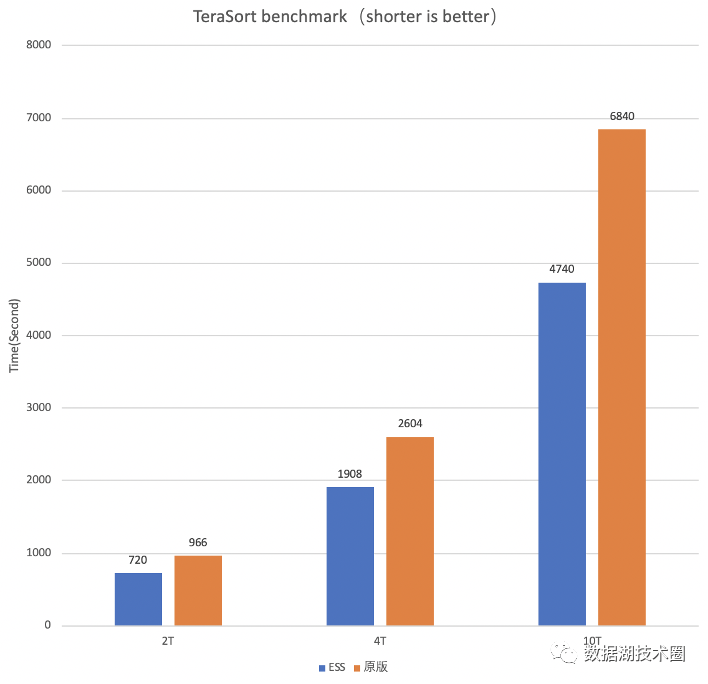
图3 TeraSort性能测试(RSS性能更好)
图4是一个线上实际脱敏后的Shuffle heavy大作业,之前在混部集群中很小概率可以跑完,每天任务SLA不能按时达成,分析原因主要是由于大量的FetchFailed导致stage进行重算。使用RSS之后每天可以稳定的跑完,2.1T的shuffle也不会出现任何FetchFailed的场景。在更大的数据集性能和SLA表现都更为显著。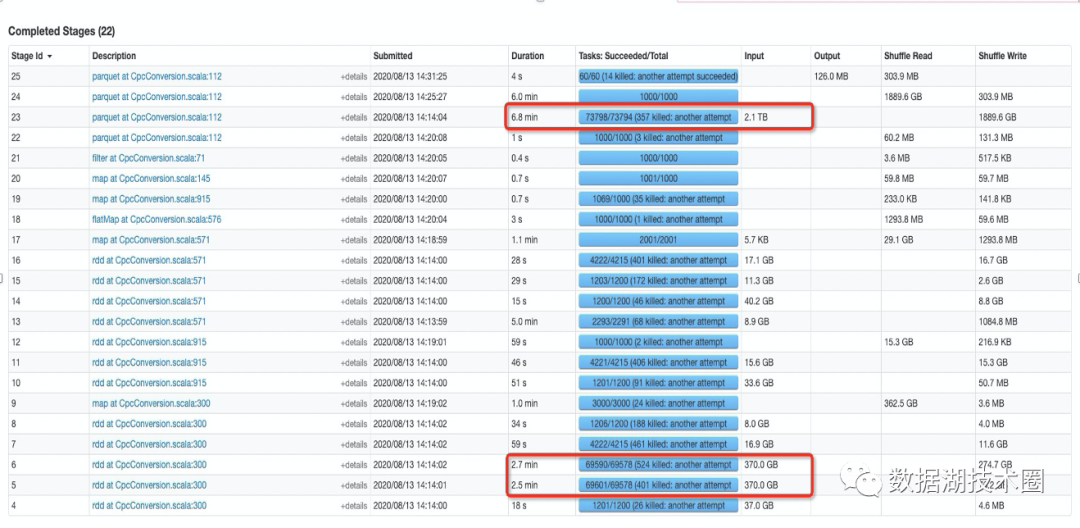
图4 实际业务的作业stage图(使用RSS保障稳定性和性能)
在大数据团队和阿里云EMR团队的共同努力下,经过近半年的上线、运营RSS,以及和业务部门的长时间测试,业务价值主要体现在以下方面:
降本增效效果明显,在集群规模小幅下降的基础上,支撑了更多的计算任务,TCO成本下降20%。
SLA显著提升,大规模Spark Shuffle任务从跑不完到能跑完,我们能够将不同SLA级别作业合并到同一集群,减小集群节点数量,达到统一管理,缩小成本的目的。原本业务方有一部分SLA比较高的作业在一个独有的Yarn集群B中运行,由于主Yarn集群A的负载非常高,如果跑到集群A中,会经常的挂掉。利用RSS之后可以放心的将作业跑到主集群A中,从而释放掉独有Yarn集群B。
作业执行效率显著提升,跑的慢 -> 跑的快。我们比较了几个典型的Shuffle heavy作业,一个重要的业务线作业原本需要3小时,RSS版本需要1.6小时。抽取线上5~10个作业,大作业的性能提升相当明显,不同作业平均下来有30%以上的性能提升,即使是shuffle量不大的作业,由于比较稳定不需要stage重算,长期运行平均时间也会减少10%-20%。
架构灵活性显著提升,升级为计算与存储分离架构。Spark在容器中运行的过程中,将RSS作为基础组件,可以使得Spark容器化能够大规模的落地,为离线在线统一资源、统一调度打下了基础。
关于Spark Remote Shuffle Service最佳实践的示例分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4588146/blog/4782284



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



