本篇内容主要讲解“influxdb的原理是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“influxdb的原理是什么”吧!
参考
LSM树详解 https://zhuanlan.zhihu.com/p/181498475
https://www.jianshu.com/p/a3a2f8f5dd65
http://hbasefly.com/2017/12/08/influxdb-1/?qytefg=c4ft23
http://hbasefly.com/2017/11/19/timeseries-database-2/?fypwxu=zot6w
https://blog.fatedier.com/2016/08/05/detailed-in-influxdb-tsm-storage-engine-one/
什么是时序数据库
数据模式: 时序数据随时间增长,相同维度重复取值,指标平滑变化
写入: 持续高并发写入,无更新操作:时序数据库面对的往往是百万甚至千万数量级终端设备的实时数据写入(如摩拜单车2017年全国车辆数为千万级),但数据大多表征设备状态,写入后不会更新
查询: 按不同维度对指标进行统计分析,且存在明显的冷热数据,一般只会频繁查询近期数据
可以看到时序数据库需要解决以下几个问题:
时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
时序数据的读取:如何支持在秒级对上亿数据的分组聚合运算。
成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
LSM树
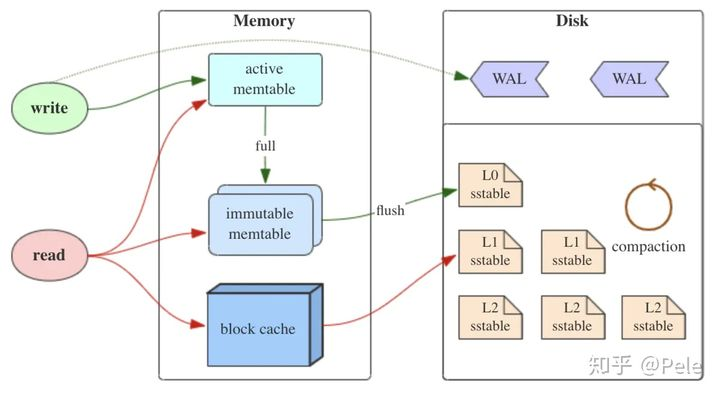
更通俗的讲,LSM树原理就是把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会批量flush到磁盘中独立的文件中以提高IO性能,而为了提高读性能磁盘中的树定期可以做merge操作,合并成一棵大树。
SSTable 就是 MemTable 中的数据在磁盘上的有序存储,其内部数据是根据 key 从小到大排列的。通常为了加快查找的速度,需要在 SSTable 中加入数据索引,可以快读定位到指定的 k-v 数据。 
顾名思义,Immutable Memtable 就是在内存中只读的 MemTable,由于内存是有限的,通常我们会设置一个阀值,当 MemTable 占用的内存达到阀值后就自动转换为 Immutable Memtable,Immutable Memtable 和 MemTable 的区别就是它是只读的,系统此时会生成新的 MemTable 供写操作继续写入。之所以要使用 Immutable Memtable,就是为了避免将 MemTable 中的内容序列化到磁盘中时会阻塞写操作。
MemTable 对应的就是 WAL 文件,是该文件内容在内存中的存储结构,通常用 SkipList 来实现。MemTable 提供了 k-v 数据的写入、删除以及读取的操作接口。其内部将 k-v 对按照 key 值有序存储,这样方便之后快速序列化到 SSTable 文件中,仍然保持数据的有序性。
MemTable
Immutable Memtable
SSTable
TSM(Time-Structured Merge Tree)
InfluxDB底层的存储引擎经历了从LevelDB到BlotDB,再到选择自研TSM的过程,整个选择转变的思考可以在其官网文档里看到。整个思考过程很值得借鉴,对技术选型和转变的思考总是比平白的描述某个产品特性让人印象深刻的多。
它的整个存储引擎选型转变的过程,第一阶段是LevelDB,选型LevelDB的主要原因是其底层数据结构采用LSM,对写入很友好,能够提供很高的写入吞吐量,比较符合时序数据的特性。在LevelDB内,数据是采用KeyValue的方式存储且按Key排序,InfluxDB使用的Key设计是SeriesKey+Timestamp的组合,所以相同SeriesKey的数据是按timestamp来排序存储的,能够提供很高效的按时间范围的扫描。
不过使用LevelDB的一个最大的问题是,InfluxDB支持历史数据自动删除(Retention Policy),在时序数据场景下数据自动删除通常是大块的连续时间段的历史数据删除。LevelDB不支持Range delete也不支持TTL(time to live),所以要删除只能是一个一个key的删除,会造成大量的删除流量压力,且在LSM这种数据结构下,真正的物理删除不是即时的,在compaction时才会生效。
时序数据库结构
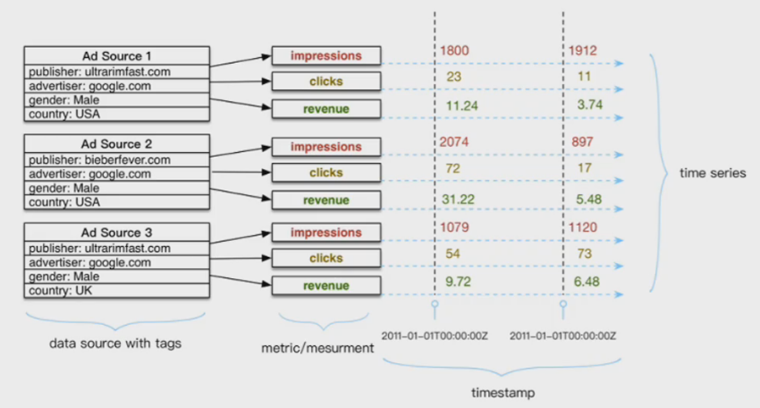
OpenTSDB/HBase
OpenTSDB基于HBase存储时序数据,在HBase层面设计RowKey规则为:metric+timestamp+datasource(tags)
问题一:存在很多无用的字段。一个KeyValue中只有rowkey是有用的,其他字段诸如columnfamily、column、timestamp以及keytype从理论上来讲都没有任何实际意义,但在HBase的存储体系里都必须存在,因而耗费了很大的存储成本。
问题二:数据源和采集指标冗余。KeyValue中rowkey等于metric+timestamp+datasource,试想同一个数据源的同一个采集指标,随着时间的流逝不断吐出采集数据,这些数据理论上共用同一个数据源(datasource)和采集指标(metric),但在HBase的这套存储体系下,共用是无法体现的,因此存在大量的数据冗余,主要是数据源冗余以及采集指标冗余。
问题三:无法有效的压缩。HBase提供了块级别的压缩算法-snappy、gzip等,这些通用压缩算法并没有针对时序数据进行设置,压缩效率比较低。HBase同样提供了一些编码算法,比如FastDiff等等,可以起到一定的压缩效果,但是效果并不佳。效果不佳的主要原因是HBase没有数据类型的概念,没有schema的概念,不能针对特定数据类型进行特定编码,只能选择通用的编码,效果可想而知。
问题四:不能完全保证多维查询能力。HBase本身没有schema,目前没有实现倒排索引机制,所有查询必须指定metric、timestamp以及完整的tags或者前缀tags进行查询,对于后缀维度查询也勉为其难。
influxdb
相比OpenTSDB以及Druid,可能很多童鞋对InfluxDB并不特别熟悉,然而在时序数据库排行榜单上InfluxDB却是遥遥领先。InfluxDB是一款专业的时序数据库,只存储时序数据,因此在数据模型的存储上可以针对时序数据做非常多的优化工作。
为了保证写入的高效,InfluxDB也采用LSM结构,数据先写入内存,当内存容量达到一定阈值之后flush到文件 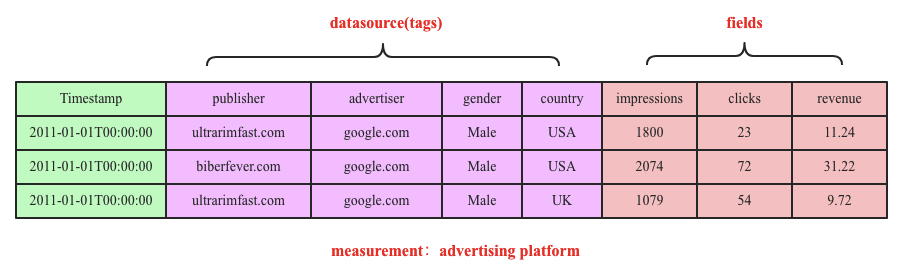 InfluxDB在时序数据模型设计方面提出了一个非常重要的概念:seriesKey,seriesKey实际上就是measurement+datasource(tags).时序数据写入内存之后按照seriesKey进行组织:
InfluxDB在时序数据模型设计方面提出了一个非常重要的概念:seriesKey,seriesKey实际上就是measurement+datasource(tags).时序数据写入内存之后按照seriesKey进行组织: 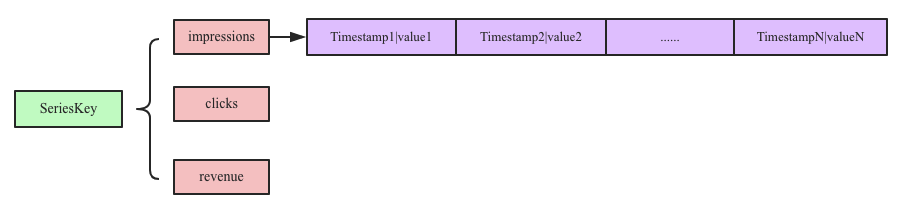
内存中实际上就是一个Map:<SeriesKey+fieldKey, List<Timestamp|Value>>,Map中一个SeriesKey+fieldKey对应一个List,List中存储时间线数据。数据进来之后根据measurement+datasource(tags)拼成SeriesKey,加上fieldKey,再将Timestamp|Value组合值写入时间线数据List中。内存中的数据flush的文件后,同样会将同一个SeriesKey中的时间线数据写入同一个Block块内,即一个Block块内的数据都属于同一个数据源下的同一个field。
将datasource(tags)和metric拼成SeriesKey,不是也不能实现多维查找。确实是这样,不过InfluxDB内部实现了倒排索引机制,即实现了tag到SeriesKey的映射关系,如果用户想根据某个tag查找的话,首先根据tag在倒排索引中找到对应的SeriesKey,再根据SeriesKey定位具体的时间线数据。InfluxDB的这种存储引擎称为TSM,全称为Timestamp-Structure Merge Tree,基本原理类似于LSM。后期笔者将会对InfluxDB的数据写入、文件格式、倒排索引以及数据读取进行专题介绍。
InfluxDB 数据模型 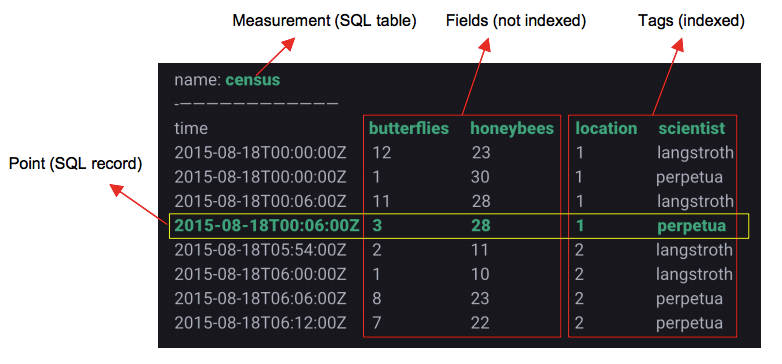
Measurement:从原理上讲更像SQL中表的概念
Tags:维度列
在InfluxDB中,表中Tags组合会被作为记录的主键,因此主键并不唯一,比如上表中第一行和第三行记录的主键都为’location=1,scientist=langstroth’。所有时序查询最终都会基于主键查询之后再经过时间戳过滤完成。
Fields:数值列。数值列存放用户的时序数据
Point:类似SQL中一行记录,而并不是一个点。
InfluxDB 系统架构 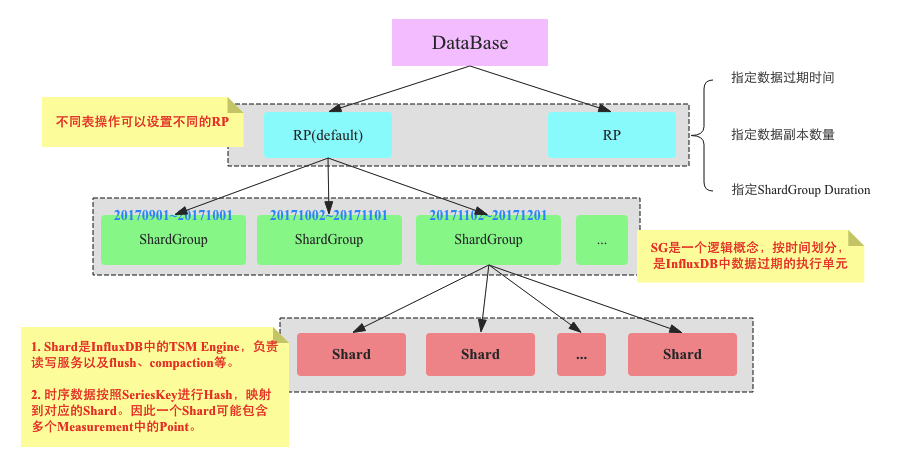
到此,相信大家对“influxdb的原理是什么”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/160697/blog/5036724



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



