这篇文章主要介绍“Flink与数据库集成方法是什么”,在日常操作中,相信很多人在Flink与数据库集成方法是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Flink与数据库集成方法是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
JDBC-Connector 的重构
FLINK-15782 :Rework JDBC Sinks[1] (重写 JDBC Sink)
FLINK-17537:Refactor flink-jdbc connector structure[2] (重构 flink-jdbc 连接器的结构)
FLIP-95: New TableSource and TableSink interfaces[3] (新的 TableSource 和 TableSink 接口)

FLIP-122:New Connector Property Keys for New Factory[4](新的连接器参数)
FLIP-87:Primary key Constraints in Table API[5] (Table API 接口中的主键约束问题)
JDBC Catalog
// The supported methods by Postgres Catalog.PostgresCatalog.databaseExists(String databaseName)PostgresCatalog.listDatabases()PostgresCatalog.getDatabase(String databaseName)PostgresCatalog.listTables(String databaseName)PostgresCatalog.getTable(ObjectPath tablePath)PostgresCatalog.tableExists(ObjectPath tablePath)JDBC Dialect
https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/table/connectors/jdbc.html#data-type-mapping
实践 Demo
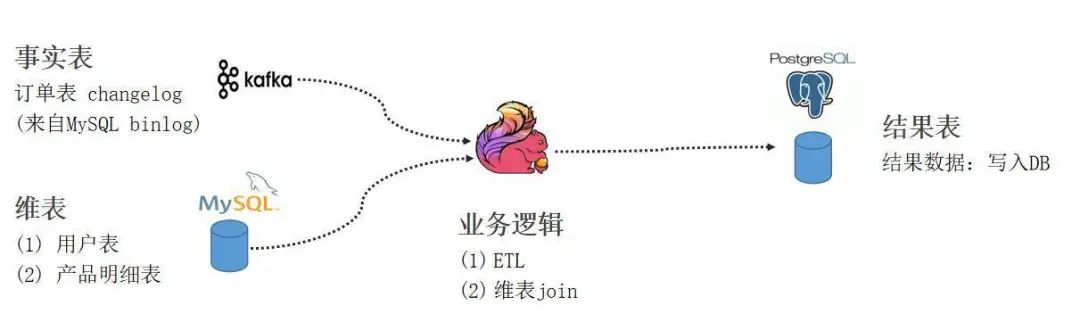
https://github.com/leonardBang/flink-sql-etl
问答环节
到此,关于“Flink与数据库集成方法是什么”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/2828172/blog/4662629



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



