这篇文章给大家分享的是有关大数据开发中定时器有哪些的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
何为定时器,说白了就是指定一个延迟时间,到期执行,就像我们早上定的闹铃一样,每天定点提醒我们起床;当然在我们各个系统中也是无处不在,比如定时备份数据,定时拉取文件,定时刷新数据等等;定时器工具也是层出不穷比如Timer,ScheduledExecutorService,Spring Scheduler,HashedWheelTimer(时间轮),Quartz,Xxl-job/Elastic-job等;本文将对这些定时器工具做个简单介绍和对比,都在哪些场景下使用。
Timer可以说是JDK提供最早的一个定时器了,使用简单,功能也相对来说比较简单;可以指定固定时间后触发,固定时间点触发,固定频率触发;
Timer timer = new Timer();
timer.schedule(new TimerTask() {@Overridepublic void run() {
System.out.println(System.currentTimeMillis() + " === task1");
}
}, 1000, 1000);时间默认为毫秒,表示延迟一秒后执行任务,并且频率为1秒执行任务;Timer内部使用TaskQueue存放任务,使用TimerThread单线程用来执行任务:
private final TaskQueue queue = new TaskQueue();private final TimerThread thread = new TimerThread(queue);
TimerThread内部是一个while(true)循环,不停的从TaskQueue中获取任务执行;当然每次添加到TaskQueue中的任务会进行排序,通过nextExecutionTime来进行排序,这样TimerThread每次都可以获取到最近执行的任务;
Timer有两大缺点:
TimerTask中出现未捕获的异常,影响Timer;
因为是单线程执行某个任务执行时间过长会影响其他认为的精确度;
正因为Timer存在的一些缺点,JDK1.5出现了新的定时器ScheduledExecutorService;
JDK1.5提供了线程池的功能,ScheduledExecutorService是一个接口类,具体实现类是ScheduledThreadPoolExecutor继承于ThreadPoolExecutor;
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2);
scheduledExecutorService.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {
System.out.println(Thread.currentThread() + " === " + System.currentTimeMillis() + " === task1");
}
}, 1000, 1000, TimeUnit.MILLISECONDS);比起Timer可以配置多个线程去执行定时任务,同时异常任务并不会中断ScheduledExecutorService,线程池的几个核心配置:
corePoolSize:核心线程数量,如果线程池中的线程少于此数目,则在执行任务时创建,核心线程不会被回收;
maximumPoolSize:允许的最大线程数,当线程数量达到corePoolSize且workQueue队列满了,会创建线程;
keepAliveTime:超过corePoolSize空闲时间;
unit:keepAliveTime的单位;
workQueue:当线程超过corePoolSize,新的任务会被加入到队列中等待;
threadFactory:创建线程的工厂类;
handler:线程池拒绝策略,包括:AbortPolicy,DiscardPolicy,DiscardOldestPolicy,CallerRunsPolicy策略,当然也可以自己扩展;
ScheduledExecutorService中添加的任务会被包装成一个ScheduledFutureTask类,同时将任务放入DelayedWorkQueue队列中是一个BlockingQueue;类似Timer也会根据加入任务触发时间的先后进行排序,然后线程池中的Worker会到Queue中获取任务执行;
Spring提供了xml和注解方式来配置调度任务,如下面xml配置:
<!-- 创建一个调度器 --><task:scheduler id="scheduler" /><!-- 配置任务类的bean --><bean id="helloTask" class="com.spring.task.HelloTask"></bean><task:scheduled-tasks scheduler="scheduler"><!-- 每2秒执行一次 --><task:scheduled ref="helloTask" method="say" cron="0/2 * * * * ?" /></task:scheduled-tasks>
Spring提供了cron表达式的支持,并且可以直接配置执行指定类中的指定方法,对使用者来说更加方便和简单;但是其内部还是使用的ScheduledThreadPoolExecutor线程池;
Netty提供的一个定时器,用于定时发送心跳,使用的是时间轮算法;HashedWheelTimer是一个环形结构,可以类比成一个时钟,整个环形结构由一个个小格组成,每个小格可以存放很多任务,随着时间的流逝,指针转动,然后执行当前指定格子中的任务;任务通过取模的方式决定其应该放在哪个格子,有点类似hashmap;
HashedWheelTimer hashedWheelTimer = new HashedWheelTimer(1000, TimeUnit.MILLISECONDS, 16);
hashedWheelTimer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) throws Exception {
System.out.println(System.currentTimeMillis() + " === executed");
}
}, 1, TimeUnit.SECONDS);其中初始化的三个参数分别是:
tickDuration:每一格的时长;
unit:tickDuration的单位;
ticksPerWheel:时间轮总共有多少格;
如上面实例配置的参数,每一格时长1秒,时间轮总共16格,如果延迟1秒执行,那就放到编号1的格子中,从0开始;如果延迟18秒,那么会放到编号为2的格子中,同时指定remainingRounds=1,表示第几轮被调用,每转一轮remainingRounds-1,知道remainingRounds=0才会被执行;
以上介绍的几种定时器都是进程内的调度,而Quartz提供了分布式调度,所有被调度的任务都可以存放到数据库中,每个业务节点通过抢占式的方式去获取需要执行的任务,其中一个节点出现问题并不影响任务的调度;
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"destroy-method="close"><property name="driverClass" value="com.mysql.jdbc.Driver" /><property name="jdbcUrl" value="jdbc:mysql://localhost:3306/quartz" /><property name="user" value="root" /><property name="password" value="root" /></bean><bean id="scheduler"class="org.springframework.scheduling.quartz.SchedulerFactoryBean"><property name="schedulerName" value="myScheduler"></property><property name="dataSource" ref="dataSource" /><property name="configLocation" value="classpath:quartz.properties" /><property name="triggers"><list><ref bean="firstCronTrigger" /></list></property></bean>
更多关于Quartz的介绍可以参考本人之前的文章:
Spring整合Quartz分布式调度
Quartz数据库表分析
Quartz调度源码分析
基于Netty+Zookeeper+Quartz调度分析
当然Quartz本身也有不足的地方:底层调度依赖数据库的悲观锁,谁先抢到谁调度,这样会导致节点负载不均衡;还有调度和执行耦合在一起,导致调度器会受到业务的影响;
正因为Quartz存在着很多不足的地方,基于Quartz实现的分布式调度解决方案出现了包括Xxl-job/Elastic-job等;
整体思路:调度器和执行器拆成不同的进程,调度器还是依赖Quartz本身的调度方式,但是调度的并不是具体业务的QuartzJobBean,而是统一的一个RemoteQuartzJobBean,在此Bean中通过远程调用执行器去执行具体业务Bean;具体的执行器在启动时注册到注册中心(如Zookeeper)中,调度器可以在注册中心(如Zookeeper)获取执行器信息,并通过相关的负载算法指定具体的执行器去执行;
还提供了运维管理界面,可以管理任务,比如像xxl-job:
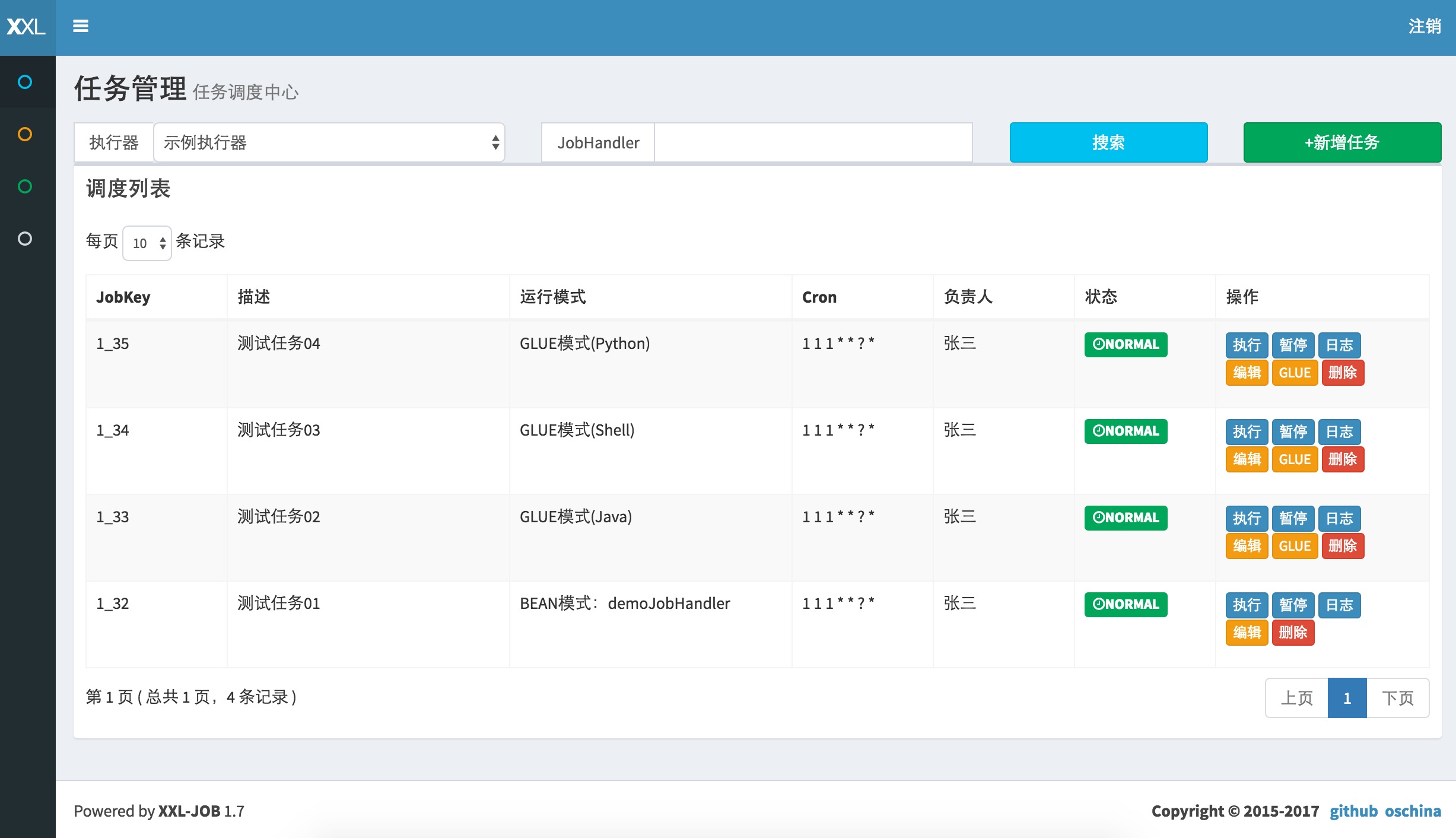
当然还有更多其他的功能,此处就不在介绍了,可以直接去查看官网;
其实整体可以分为两大类:进程内定时器包括和分布式调度器;
进程内定时器:Timer,ScheduledExecutorService,Spring Scheduler,HashedWheelTimer(时间轮);
分布式调度器:Quartz,Xxl-job/Elastic-job;
所以首先根据需要仅仅只需要进程内的定时器,还是需要分布式调度;
其次在进程内Timer基本可以被淘汰了,完全可以使用ScheduledExecutorService来代替,如果系统使用了Spring那当然应该使用Spring Scheduler;
下面重点看看ScheduledExecutorService和HashedWheelTimer,ScheduledExecutorService内部使用的是DelayedWorkQueue,任务的新增、删除会导致性能下降;而HashedWheelTimer并不受任务数量限制,所以如果任务很多并且任务执行时间很短比如心跳,那么HashedWheelTimer是最好的选择;HashedWheelTimer是单线程的,如果任务不多并且执行时间过长,影响精确度,而ScheduledExecutorService可以使用多线程这时候选择ScheduledExecutorService更好;
最后分布式调度器里面Quartz和Xxl-job/Elastic-job,对分布式调度要求不高的情况下才会选择Quartz,不然都应该选择Xxl-job/Elastic-job
感谢各位的阅读!关于“大数据开发中定时器有哪些”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





