这篇文章给大家介绍基于ClickHouse的用户行为大数据架构是怎样的,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
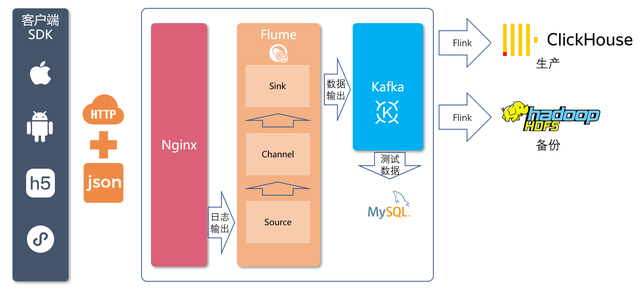
SDK埋点采集行为数据来源终端包括iOS、安卓、Web、H5、微信小程序等。不同终端SDK采用对应平台和主流语言的SDK,埋点采集到的数据通过JSON数据以HTTP POST方式提交到服务端API。
服务端API由数据接入系统组成,采用Nginx来接收通过 API 发送的数据,并且将之写到日志文件上。使用Nginx实现高可靠性与高可扩展性。
对于Nginx打印到文件的日志,会由Flume的 Source 模块来实时读取Nginx日志,并由Channel模块进行数据处理,最终通过Sink模块将处理结果发布到 Kafka中。
Kafka是一个广泛使用的高可用的分布式消息队列,作为数据接入与数据处理两个流程之间的缓冲,同时也作为近期数据的一个备份。
在Flume处理时,根据版本号识别到是测试数据,会写入kafka的测试分支,此分支会将行为日志的JSON数据写入MySQL,为开发人员提供埋点开发调试过程中的确认。对线上业务没有影响。
在Flume识别到生产数据,会写入kafka的生产分支。后端由Flink将Kafka中数据进行必要的ETL与实时维度join操作,形成规范的明细数据,并写回Kafka以便下游与其他业务使用。再通过Flink将明细数据分别写入ClickHouse和Hive打成大宽表,前者作为查询与分析的核心,后者作为备份和数据质量保证。
关于基于ClickHouse的用户行为大数据架构是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





