这篇文章主要讲解了“Impala与hive的区别是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Impala与hive的区别是什么”吧!
Impala是由Cloudera公司开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase上的PB级大数据,在性能上比Hive高出3~30倍。
Impala的运行需要依赖于Hive的元数据。Impala是参照 Dremel系统进行设计的。
Impala采用了与商用并行关系数据库类似的分布式查询引擎,可以直接与HDFS和HBase进行交互查询。
Impala和Hive采用相同的SQL语法、ODBC驱动程序和用户接口。
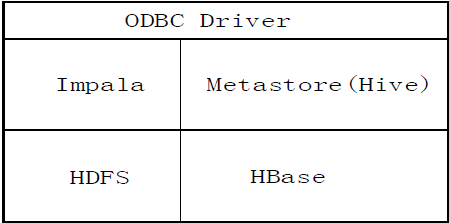
图:Impala与其他组件的关系
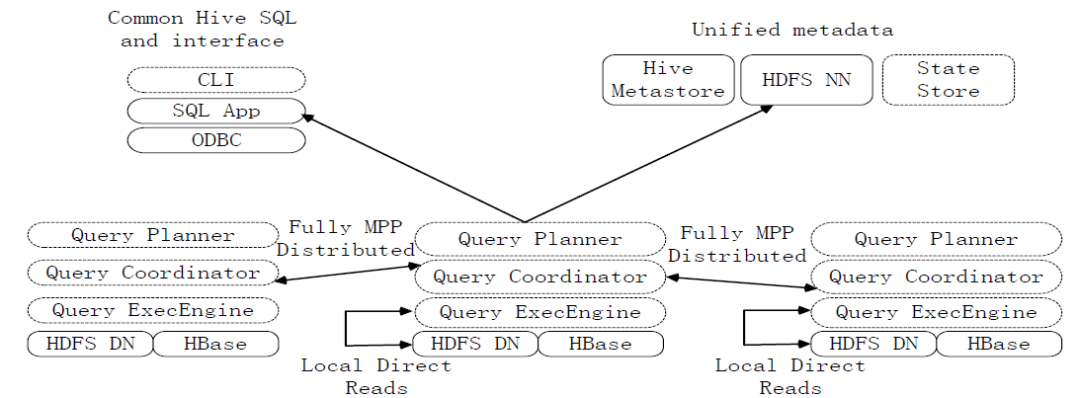
图:Impala系统架构图
Impala和Hive、HDFS、HBase等工具是统一部署在一个Hadoop平台上的。Impala主要由Impalad,State Store和CLI三部分组成。
(1)Impalad
(2)State Store
(3)CLI
说明:Impala中的元数据直接存储在Hive中。Impala采用与Hive相同的元数据、SQL语法、ODBC驱动程序和用户接口,从而使得在一个Hadoop平台上,可以统一部署Hive和Impala等分析工具,同时支持批处理和实时查询。
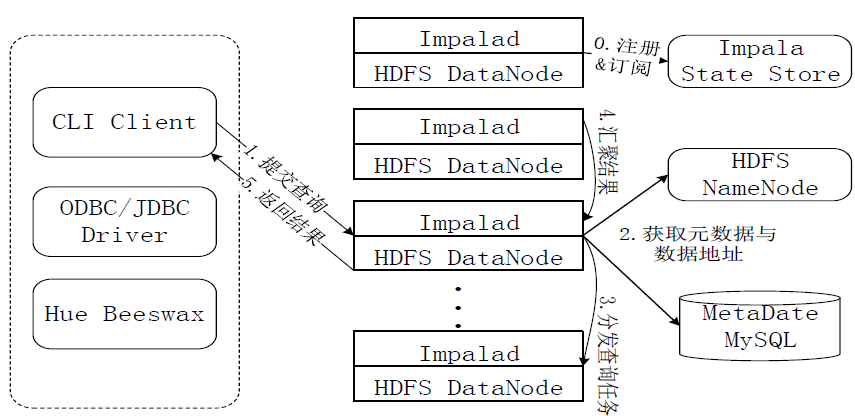
图:Impala查询执行过程图
Impala执行查询的具体过程:
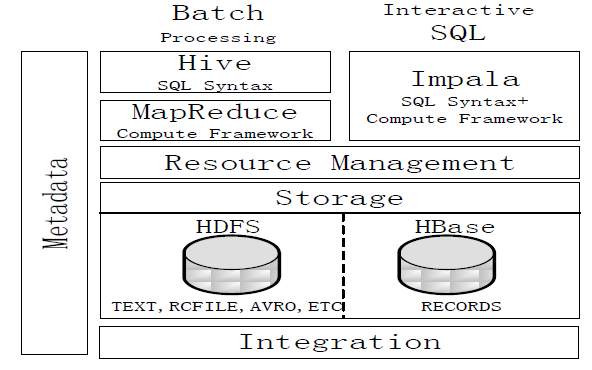
图:Impala与Hive的对比
Hive与Impala的不同点总结如下:
Hive与Impala的相同点总结如下:
总结:
感谢各位的阅读,以上就是“Impala与hive的区别是什么”的内容了,经过本文的学习后,相信大家对Impala与hive的区别是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4590259/blog/5016745



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



