这篇文章将为大家详细讲解有关如何对浏览器解析和XSS的深度探究,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
为什么要进行编码?
主要是因为某些数据不适合传输。原因多种多样,如 Size 过大,包含隐私数据,另外重要的一点就是有些字符会引起歧义。
对于 URL: &用于分割多个参数,倘若有某个参数键值为 name=v&lue,就会因为 name 参数的值 v&lue 中携带了&而造成歧义。因此需要对&进行 URL 编码。url编码后,服务端会把紧跟在“%”后的字节当成普通的字节,就是不会把它当成各个参数或键值对的分隔符。
对于 HTML: 当浏览器遇到<会识别为元素定义的开始,>会识别为元素的结束。倘若有<div id="1>" ></div>,由于标签的属性值携带了>,同样会造成歧义。因此需要属性值的>需要 进行 HTML 编码,即使用字符实体。
字符实体是一个预先定义好的转义序列。 字符实体两种表示方法:
1、 字符实体以&开头+预先定义的实体名称+;分号结束,如“<”的实体名称为&lt;
2、 字符实体还可以以&开头+#符号+字符在 ASCII 对应的十进制数字+;分号结束,如<的实体编号为&#60;
字符都是有实体编号的,但有些字符是没有实体名称
| 显示结果 | 描述 | 实体名称 | 实体编号 |
|---|---|---|---|
| 空格 | &nbsp; | &#160; | |
| < | 小于号 | &lt; | &#60; |
| > | 大于号 | &gt; | &#62; |
| & | 和号 | &amp; | &#38; |
| " | 引号 | &quot; | &#34; |
| ' | 撇号 | &apos; (IE不支持) | &#39; |
| ¢ | 分(cent) | &cent; | &#162; |
| £ | 镑(pound) | &pound; | &#163; |
| ¥ | 元(yen) | &yen; | &#165; |
| € | 欧元(euro) | &euro; | &#8364; |
| § | 小节 | &sect; | &#167; |
| © | 版权(copyright) | &copy; | &#169; |
| ® | 注册商标 | &reg; | &#174; |
| ™ | 商标 | &trade; | &#8482; |
| × | 乘号 | &times; | &#215; |
| ÷ | 除号 | &divide; | &#247; |
最常用的,如\uXXXX 这种写法的Unicode 转义序列,表示一个字符,其中 XXXX 表示一个 16 进制数字,如<的Unicode 编码为\u003c。
RFC3986 文档规定,URL 中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4 个特殊字 符以及所有保留字符。 RFC3986 中指定了以下字符为保留字符:! * ' ( ) ; : @ & = + $ , / ? # [ ]
编码方式 %加字符在 ASCII 码表中的十六进制值。例如,/在 ASCII 码表中十六进制为 0x2f,那么它对应的 URL 编码为%2f。
JavaScript 中提供了 3 个函数用来对 URL 编码以得到合法的 URL:
1、 escape()
2、 encodeURI()
3、 encodeURIComponent()
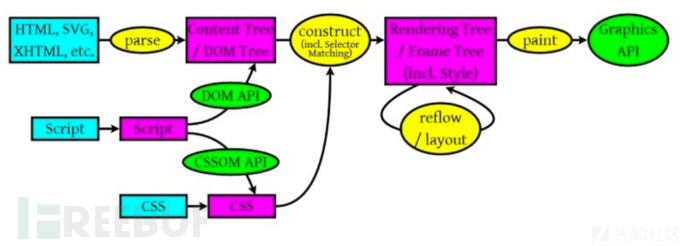
浏览器无论什么情况都会遵守一个这样的解码规则:
1、 HTML 解析器对 HTML 文档进行解析,完成 HTML 解码并且创建 DOM 树
2、 JavaScript 或者 CSS 解析器对内联脚本进行解析,完成 JS、CSS 解码
3、 URL 解码会根据 URL 所在的顺序不同而在 JS 解码前或者解码后
3.1.1HTML 中有五类元素:
1、 空元素(Voidelements),有 area、base、br、col、command、embed、hr、img、input、 keygen、link、meta、param、source、track、wbr
2、 原始文本元素(Raw textelements),有<script>和<style>
3、 RCDATA 元素(RCDATA elements),有<textarea>和<title>
4、 外部元素(Foreignelements),例如 MathML 命名空间或者 SVG 命名空间的元素
5、 基本元素(Normal elements),即除了以上 4 种元素以外的元素
五类元素的区别如下:
1、 空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
2、 原始文本元素,可以容纳文本。
3、 RCDATA 元素,可以容纳文本和字符引用。
4、 外部元素,可以容纳文本、字符引用、CDATA 段、其他元素和注释
5、 基本元素,可以容纳文本、字符引用、其他元素和注释
3.1.2 HTML编解码
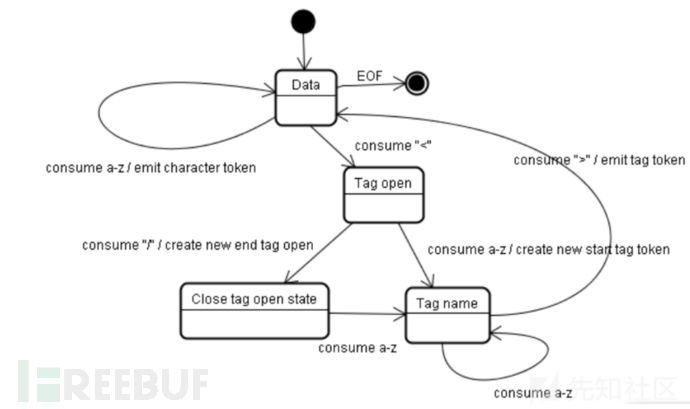
HTML 解析器以状态机的方式运行,它从文档输入流中消耗字符并根据其转换规则转换到不同的状态。
示例:
<html><body>Hello world</body></html>1、 初始状态为"DataState",当遇到"<"字符,状态变为"Tag open state",读取一个 a-z 的字符将产生一个开始标签符号,状态相应变为"Tag name state",一直保持这个状态直到读取到">",每个字符都附加到这个符号名上,例子中创建的是一个 html 符号。
2、 当读取到">",当前的符号就完成了,此时,状态回到"Data state","<body>"重复这一处理过程。到这里,html 和 body 标签都识别出来了。现在,回到"Data state",读取"Helloworld"中的字符"H"将创建并识别出一个字符符号,这里会为"Hello world"中的每个字符 生成一个字符符号。
3、 这样直到遇到"</body>"中的"<"。现在,又回到了"Tag openstate",读取下一个字符"/" 将创建一个闭合标签符号,并且状态转移到"Tag name state",还是保持这一状态,直到 遇到">"。然后,产生一个新的标签符号并回到"Data state"。后面的"</html>"将和 "</body>"一样处理。
总结:当HTML 解析器处于数据状态(DataState)、RCDATA 状态(RCDATA State)、属性值状态(Attribute Value State)时,字符实体会被解码为对应的字符。
示例:
<div>&#60;img src=x onerror=alert(4)&#62;</div><和>被编码为字符实体&#60;和&#62;。 当 HTML 解析器解析完<div>时,会进入数据状态(Data State)并发布标签令牌。接着解析到实体&#60;时因为处在数据状态(Data State)就会对实体进行解码为<,后面 的&#62;同样道理被解码为>。
这里会有个问题,被解码后,img是否会被解析为 HTML 标签而导致 JS 执行呢?
答案是否定的。因为解析器在使用字符引用后不会转换到标签打开状态(Tag OpenState),不进入标签打开状态就不会被发布为 HTML 标签。因此,不会创建新 HTML 标签, 只会将其作为数据来处理。 这也是为什么我们可以使用字符实体来避免用户不安全输入导致 XSS 的原因。
3.1.3 原始文本元素(Raw text elements)
在 HTML 中,属于 Rawtext elements 的标签有两个:script、style。在 Raw text elements 类型标签下的所有内容块都属于该标签。
存在一条特性: Raw text elements 类型标签下的所有字符实体编码都不会被 HTML 解码。HTML 解析器 解析到 script、style 标签的内容块(数据)部分时,状态会进入 Script Data State,该状态并 不在我们前面说的会解码字符实体的三条状态之中。
因此,<script>&#97;&#108;&#101;&#114;t&#40;&#57;&#41;&#59;</script>这样字符实体并不会被解码,也就不会执行 JS。
3.1.4 RCDATA
在 HTML 中,属于RCDATAElements的标签有两个:textarea、title。
RCDATA Elements 类型的标签可以包含文本内容和字符实体。
解析器解析到 textarea、title标签的数据部分时,状态会进入 RCDATA State。
前面我们提到,处于 RCDATA State 状态时,字符实体是会被解析器解码的。
示例:
<textarea>&#60;script&#62;alert(5)&#60;/script&#62;</textarea><和>被编码为实体&#60;和&#62;。 解析器解析到它们时会进行解码,最终得到<textarea><script>alert(5)</script></textarea>。但是里面的 JS 同样还是不会被执 行,原因还是因为解码字符实体状态机不会进入标签打开状态(TagOpen State),因此里面的<script>并不会被解析为 HTML 标签。
3.1.5 外部元素(Foreign elements)
来源于 MathML 和 SVG 命名空间
<svg>遵循 XML 和 SVG 的定义
实例:
<script>alert&#40;1)</script>不能弹窗,Raw text elements 类型标签下的所有字符实体编码都不会被 HTML 解码
<svg><script>alert&#40;1)</script>能弹窗,在 XML 中,&#40;会被解析成(,在 XML 中实体会自动转义,除了<![CDATA[和]]> 包含的实体
形如 \uXXXX 这样的 Unicode 字符转义序列或 Hex 编码是否能被解码需要看情况。 首先,JavaScript 中有三个地方可以出现 Unicode 字符转义序列:
1、字符串中(in String)
Unicode 转义序列出现在字符串中时,它只会被解释为普通字符,而不会破坏字符串的上下文。
例如,<script>alert("\u0031\u0030");</script>
被编码转义的部分为 10,是字符串,会被正常解码,JS 代码也会被执行。
2、标识符中(in identifier names)
若 Unicode 转义序列存在于标识符中,即变量名(如函数名等…),它会被进行解码。
例如,<script>\u0061\u006c\u0065\u0072\u0074(10);</script>
被编码转义的部分为 alert 字符,是函数名,属于在标识符中的情况,因此会被正常解码,JS 代码也会被执行。
3、控制字符中(in control characters)
若 Unicode 转义序列存在于控制字符中,那么它会被解码但不会被解释为控制字符,而会被解释为标识符或字符串字符的一部分。 控制字符即'、"、()等。
例如,<script>alert\u0028"xss"); </script>,(进行了 Unicode 编码,那么解码后它不再是作为控制字符,而是作为标识符的一部分alert(。
因此函数的括号之类的控制字符进行Unicode 转义后是不能被正常解释的。
总结:Unicode 序列不能出现在控制字符中,否则不能被解释。
示例 1:
<script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>被编码部分为 alert(11)。
该例子中的 JS 不会被执行,因为控制字符被编码了。
示例 2:
<script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>被编码部分为 alert 及括号内为12。
该例子中 JS 不会被执行,原因在于括号内被编码的部分不能被正常解释,即使反编码之后为数字,但是仍然按照字符串来处理(这里的12为字符串12,并不是int整数)。要么使用 ASCII 数字,要么加""或''使其变为字符串,作为字符串也只能作为普通字符。
示例 3:
<script>alert('13\u0027)</script>被编码处为'。
该例的 JS 不会执行,因为控制字符被编码了,解码后的'将变为字符串的一部分,而不再解释为控制字符。因此该例中字符串是不完整的,因为没有'来结束字符串。
示例 4:
<script>alert('14\u000a')</script>该例的 JS 会被执行,因为被编码的部分处于字符串内,只会被解释为普通字符,不会突破字符串上下文。
示例 5:
<img src="1" onerror=\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0029>此例无法执行。我们以浏览器的视角来看:首先读到<开始读取标签,然后读到 onerror 调用 JS 解析器。 在JS中,单引号,双引号和圆括号等属于控制字符,编码后将无法识别。所以对于防御来说,应该编码这些控制字符。
下面这种方式可以解析:
<img src="1" onerror=\u0061\u006c\u0065\u0072\u0074('\u0031')>可以结合上面的 HTML 编码 按照解析顺序反过去,先 JS 编码然后 HTML 解码:
<img src="1" onerror=&#92;&#117;&#48;&#48;&#54;&#49;&#92;&#117;&#48;&#48;&#54;&#99;&#92;&#117;&#48;&#48;&#54;&#53;&#92;&#117;&#48;&#48;&#55;&#50;&#92;&#117;&#48;&#48;&#55;&#52;&#40;&#39;&#92;&#117;&#48;&#48;&#51;&#49;&#39;&#41;>浏览器读到了<标签开始构造语法树,然后 HTML 解码,解码之后发现 onerror 于是进行 一个 JS 解码,成功弹窗
延伸:
开发人员单纯的设置 HTML 实体编码为防御 xss 的手段,但是用户输入点在 alert 中 <img src = "https://text.com" onclick = 'alert("输入点")'>
如果用户正常输入的话凡是存在< ," 等都能被转码
攻击者可以通过语句 ");alert("test,在服务端被转码:
<img src ="https://gss1.bdstatic.com" onclick = 'alert("FIRSTXSS&#34;&#41;&#59;&#97;&#108;&#101;&#114;&#116;&#40;&#34;&#116;&#101;&#115;&#116;")'>弹窗两次,是因为浏览器进行 HTML 解码发现存在两个 alert()
所以对于这种情况,正确防御 XSS 的方法:
应该是先 JavaScript 编码然后再进行 HTML 编码用户输入 ");alert("test 后在服务端先 JavaScript 编码然后再进行 HTML 编码到浏览器端:首先经过第一步 HTML 解码后变为\u0022\u0029\u003B\u0061\u006C\u0065\u0072\u0074\u0028\u0022\u0074\u0065\u0073\u0074。JavaScript 解析器工作,变为");alert("test ,刚才已经讲过 JavaScript 解析时只有标识符名称不会被当做字符串,控制字符仅会被解析为标示符名称或者字符串,因此 \u0022 被解释成双引号文本,\u0028 和\u0029 被解释成为圆括号文本,不会变为控制 字符被解析执行。
在这里采用的先 JS 编码后 HTML 编码中只弹窗了一次。
通用 URI 的格式如下:
[协议名]://[用户名]:[密码]@[主机名]:[端口]/[路径]?[查询参数]#[片段 ID]
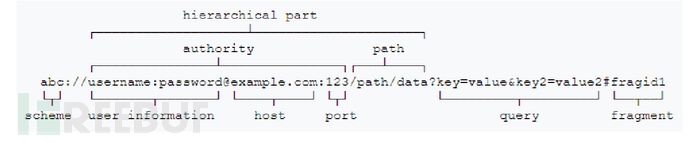
URL 解析器也被建模为状态机,文档输入流中的字符可以将其导向不同的状态。
首先,要注意的是 URL 的 Scheme 部分(协议部分)必须为 ASCII 字符,即不能被任何编码,否则 URL 解析器的状态机将进入 No Scheme 状态。
示例1:
<ahref="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>URL 编码部分的是javascript:alert(1)。
JS 不会被执行,因为作为Scheme 部分的"javascript"这个字符串被编码(其中javascript是一种伪协议),导致 URL 解析 器状态机进入 No Scheme 状态。
URL 中的:也不能被以任何方式编码,否则 URL 解析器的状态机也将进入 No Scheme 状态。
<ahref="javascript%3aalert(3)"></a>由于:被 URL 编码为%3a,导致 URL 状态机进入 NoScheme 状态,JS 代码不能执行。
示例2:
<ahref="&#x6a;&#x61;&#x76;&#x61;&#x73;&#x63;&#x72;&#x69;&#x70;&#x74;:%61%6c%65%72%74%28%32%29">"javascript"这个字符串被实体化编码,:没有被编码,alert(2)被 URL编码。 成功执行 首先,在 HTML 解析器中我们谈到过,HTML状态机处于属性值状态(Attribute Value State)时,字符实体时会被解码的,此处在 href 属性中,所以被实体化编码的 "javascript"字符串会被解码。其次,HTML 解析是在URL解析之前的,所以在进行 URL 解析之前,Scheme 部分的"javascript"字符串已被解码,而并不再是被实体编码的状态。
首先浏览器接收到一个 HTML 文档时,会触发 HTML 解析器对 HTML 文档进行词法解析,这一过程完成 HTML 解码并创建 DOM 树。
接下来 JavaScript 解析器会介入对内联脚本进行解析,这一过程完成 JS 的解码工作。
如果浏览器遇到需要 URL 的上下文环境,这时 URL 解析器也会介入完成 URL 的解码工 作,URL 解析器的解码顺序会根据 URL 所在位置不同,可能在 JavaScript 解析器之前或之后解析。
总之HTML 解析总是第一步。URL 解析和 JavaScript 解析,它们的解析顺序要根据情况而定。
示例 1:
<a href="UserInput"></a>该例子中,首先由 HTML 解析器对UserInput 部分进行字符实体解码;
接着 URL 解析器对UserInput 进行 URL decode;
如果 URL 的 Scheme 部分为 javascript 的话,JavaScript 解析器会再对 UserInput 进行解 码。
所以解析顺序是:HTML 解析->URL解析->JavaScript 解析。
示例 2:
<a href=# onclick="window.open('UserInput')"></a>该例子中,首先由 HTML 解析器对UserInput 部分进行字符实体解码;
接着由 JavaScript 解析器会再对 onclick 部分的 JS 进行解析并执行 JS;
执行 JS 后window.open('UserInput')函数的参数会传入 URL,所以再由 URL 解析器对 UserInput 部分进行解码。
因此解析顺序为:HTML 解析->JavaScript解析->URL 解析。
示例 3:
<a href="javascript:window.open('UserInput')">该例子中,首先还是由 HTML 解析器对 UserInput 部分进行字符实体解码;
接着由 URL 解析器解析 href 的属性值;
然后由于Scheme为javascript,所以由 JavaScript 解析;
解析执行 JS 后window.open('UserInput')函数传入 URL,所以再由 URL 解析器解析。
所以解析顺序为:HTML 解析->URL解析->JavaScript 解析->URL 解析。
综合实例:
<a href="&#x6a;&#x61;&#x76;&#x61;&#x73;&#x63;&#x72;&#x69;&#x70;&#x74;&#x3a;&#x25;&#x35;&#x63;&#x25;&#x37;&#x35;&#x25;&#x33;&#x30;&#x25;&#x33;&#x30;&#x25;&#x33;&#x36;&#x25;&#x33;&#x31;&#x25;&#x35;&#x63;&#x25;&#x37;&#x35;&#x25;&#x33;&#x30;&#x25;&#x33;&#x30;&#x25;&#x33;&#x36;&#x25;&#x36;&#x33;&#x25;&#x35;&#x63;&#x25;&#x37;&#x35;&#x25;&#x33;&#x30;&#x25;&#x33;&#x30;&#x25;&#x33;&#x36;&#x25;&#x33;&#x35;&#x25;&#x35;&#x63;&#x25;&#x37;&#x35;&#x25;&#x33;&#x30;&#x25;&#x33;&#x30;&#x25;&#x33;&#x37;&#x25;&#x33;&#x32;&#x25;&#x35;&#x63;&#x25;&#x37;&#x35;&#x25;&#x33;&#x30;&#x25;&#x33;&#x30;&#x25;&#x33;&#x37;&#x25;&#x33;&#x34;&#x28;&#x31;&#x35;&#x29;"></a>首先 HTML 解析器进行解析,解析到href 属性的值时,状态机进入属性值状态(Attribute Value State),该状态会解码字符实体;
接着由 URL 解析器进行解析并解码;
再接着由于 Scheme 为javascript,因此由 JavaScript 解析器解析并解码,加上编码部分是函 数名,属于标识符,因此可以正常解码解释;
经过三轮解析解码后得到结果:<a href="javascript:alert(15)"></a>
关于如何对浏览器解析和XSS的深度探究就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.freebuf.com/articles/web/222849.html



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



