python中怎么利用正则表达式从网页摘取信息,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
练习从网页爬取数据时,为了不触发网站的反爬机制,建议打开网页另存为html文件。我从某网站保存了一页关于房产信息的网页,尝试从中爬取信息。
然后用notepad++打开该文件,看看文件内容。

是不是感觉有点无从下手?别慌,慢慢来。通过对比网页和网页代码我们确认信息特征。
房产名称:
急降60万 急卖全款客户来 宝山二村好位置
复制该信息,到html文件中通过ctrl+F查找该信息,然后认真查看“房产名称”前后的字符特征:
前面的字符特征:
;</span>" >后面的字符特征:
&nbsp;现在对照房产名称前后的字符特征编写正则表达式,同时给“房产名称”进行分组命名(?P.*?):
;</span>" >(?P<name>.*?)&nbsp;注意: .*?在爬取网页时经常会用到,表示匹配任意内容任意数量直到遇到后面的字符特征结束。
房型:
现在再观察下一项“房型”信息前后的字符特征:
前面的字符特征:
span></span>后面的字符特征:
<span class="html-tag">如法炮制,提取“房型”信息并进行分组命名(?P.*?):
span></span>(?P<type>.*?)<span class="html-tag">注意: 在房产名称和房型之间有大段网页代码,我们可以写.*?对应该段代码表示跳过。
面积:
现在再观察下一项“面积”信息前后的字符特征:
前面的字符特征:
<span class="html-tag"><span></span>后面的字符特征:
<span如法炮制,提取“面积”信息并进行分组命名(?P.*?):
<span class="html-tag"><span></span>(?P<area>.*?) <span总价:
现在就剩最后一项“总价”信息,继续查找该信息前后的字符特征:
前面的字符特征:
</span><span class="html-tag"><b></span>后面的字符特征:
<span class="html-tag"><如法炮制,提取“总价”信息并进行分组命名(?P.*?):
</span><span class="html-tag"><b></span>(?P<price>.*?)<span class="html-tag"><现在提取网页数据四项信息的正则表达式均已写好,注意每一项信息之间间隔了很多的网页代码,我们可以用.*?对应该段代码表示跳过。让我们现在把4段信息连起来,写出完整的正则表达式:
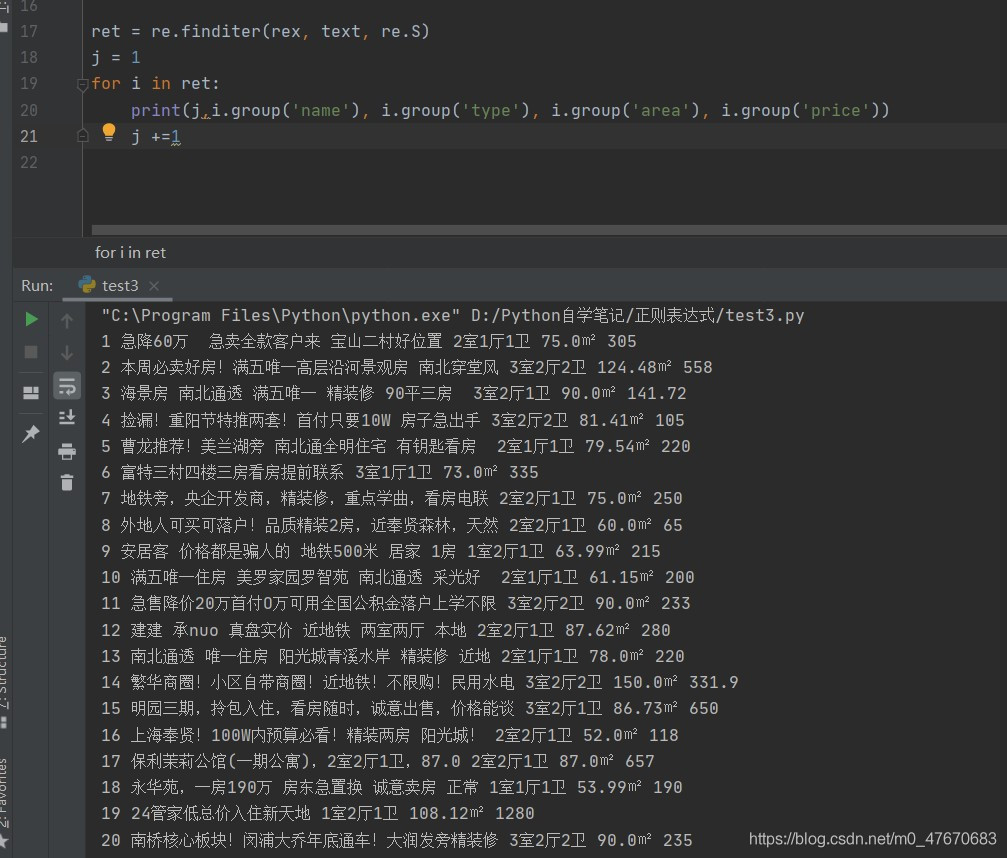
rex = ';</span>" >(?P<name>.*?)&nbsp;.*?span></span>(?P<type>.*?)<span class="html-tag">.*?<span class="html-tag"><span></span>(?P<area>.*?) <span.*?</span><span class="html-tag"><b></span>(?P<price>.*?)<span class="html-tag"><'import rewith open('房屋信息.html',encoding='utf8') as f:text = f.read()rex = ';</span>" >(?P<name>.*?)&nbsp;.*?span></span>(?P<type>.*?)<span class="html-tag">.*?<span class="html-tag"><span></span>(?P<area>.*?) <span.*?</span><span class="html-tag"><b></span>(?P<price>.*?)<span class="html-tag"><'ret = re.finditer(rex, text, re.S)j = 1for i in ret:print(j,i.group('name'), i.group('type'), i.group('area'), i.group('price'))j +=1最终输出内容有120项,信息式样如下:
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/fz17/blog/4746164



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



