概念:
正则表达式使用单个字符串来描述、匹配一系列符合某个 句法规则的字符串。
使用场景:
在很多文本编辑器里,正则表达式通常被用来检索、替换 那些符合某个模式的文本。
tip
1、处理正则表达式的工具会提供一个忽略大小写的选项,
2、只使用一个正则表达式,可能不能准确的第筛选,这时,可以采用分支结构,但是分支结构使用过程中,也要注意各个表达式的先后顺序;
3、但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
use:
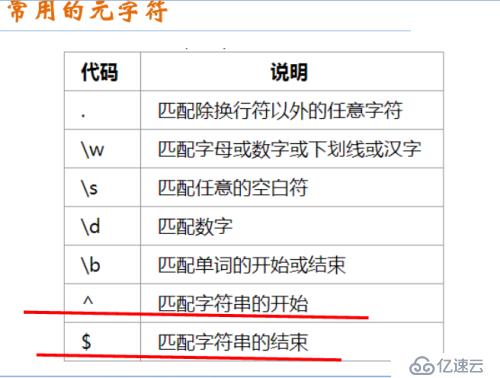
1、\b是正则表达式规定的一个特殊代码(也叫元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。
假如你要找的是hi后面不远处跟着一个Lucy,你应该用\bhi\b.*\bLucy\b。
\bhi\b
\b[Hh]i\b
\b(H|h)i\b
常用元字符:




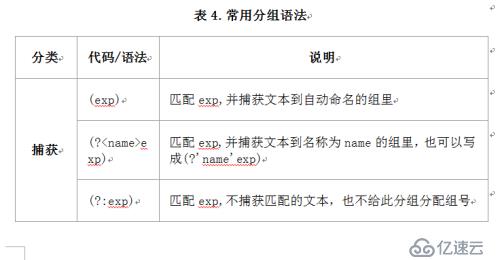



后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。难以理解?请看示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?<Word>\w+)(或者把尖括号换成'也行:(?'Word'\w+)),这样就把\w+的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k<Word>,所以上一个例子也可以写成这样:\b(?<Word>\w+)\b\s+\k<Word>\b。

正则表达式的更深层次东西,我暂且还没有学到,但是这些基本可以应该可以应付一些基础的使用!
每日弟子规:
事虽小 勿擅为 苟擅为 子道亏
物虽小 勿私藏 苟私藏 亲心伤
第五天!
加油!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



