这篇文章主要介绍“Python怎么爬取高质量超清壁纸”,在日常操作中,相信很多人在Python怎么爬取高质量超清壁纸问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python怎么爬取高质量超清壁纸”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Python 3.6
Pycharm
import requests import re import os
安装Python并添加到环境变量,pip安装需要的相关模块即可。
如图所示爬取里面的高清壁纸
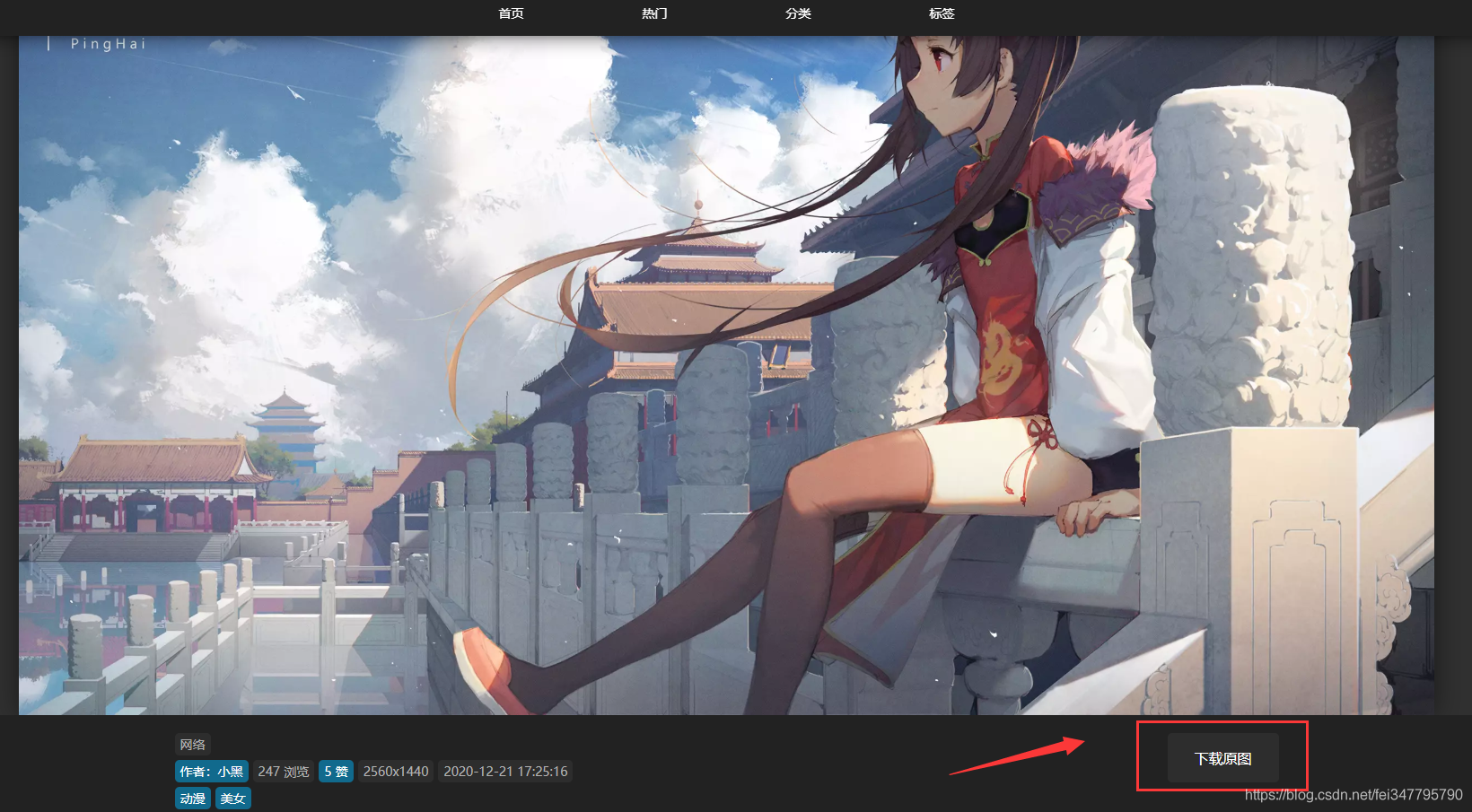
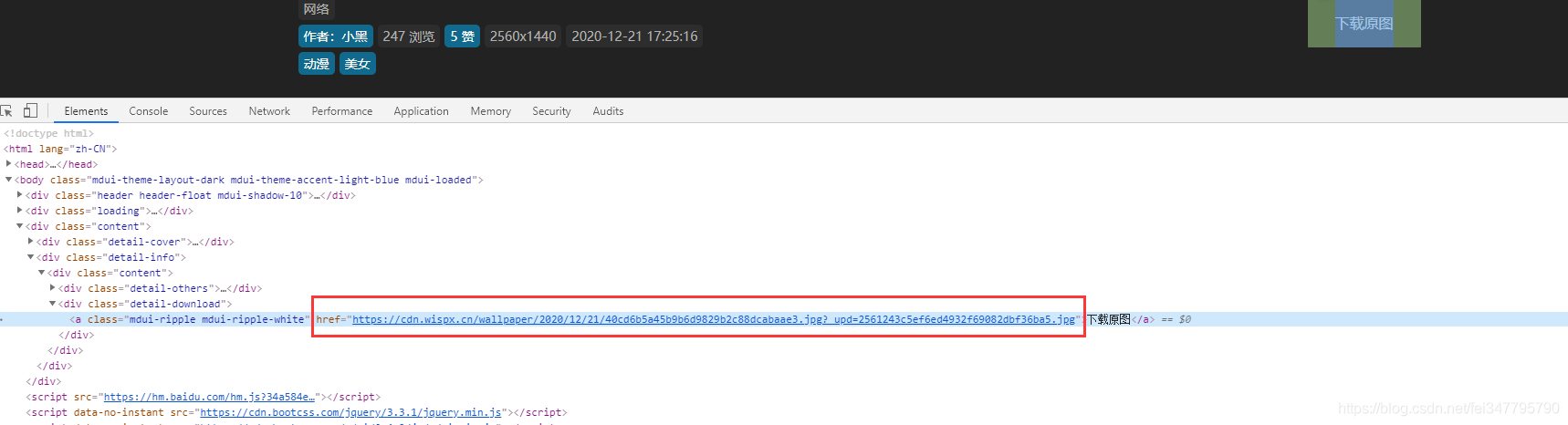
所以只需要获取这个链接就可以了爬取壁纸图片了。
返回列表的可以发现,网页是瀑布流加载方式,当你往下滑才会有数据出现。所以可以在下滑网页的前,先打开开发者工具,当下滑网页的时候新加载出来的数据会出现。
通过对比可以知道,这个数据包中包含了,壁纸图片下载的地址。
需要注意的就是这个数据链接是post请求,并不是get请求
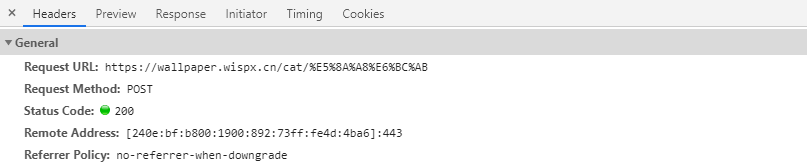
需要提交的data参数,就是对应的页码。
1、获取图片ID
for page in range(1, 11):
url = 'https://wallpaper.wispx.cn/cat/%E5%8A%A8%E6%BC%AB'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
data = {
'page': page
}
response = requests.post(url=url, headers=headers)
result = re.findall('detail(.*?)target=', response.text)
for index in result:
image_id = index.replace('\\', '').replace('" ', '')
page_url = f'https://wallpaper.wispx.cn/detail{image_id}'2、获取壁纸url地址,并保存
def main(page_url):
html_data = get_response(page_url).text
image_url = re.findall('<a class="mdui-ripple mdui-ripple-white" href="(.*?)">', html_data)[0]
image_title = re.findall('<title>(.*?)</title>', html_data)[0].split(' - ')[0]
image_content = get_response(image_url).content
path = 'images\\'
if not os.path.exists(path):
os.makedirs(path)
with open(path + image_title + '.jpg', mode='wb') as f:
f.write(image_content)
print('正在保存:', image_title)需要注意的点:
请求头里面要防盗链,不然就下载不了。
def get_response(html_url):
header = {
'referer': 'https://wallpaper.wispx.cn/detail/1206',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
resp = requests.get(url=html_url, headers=header)
return resp
到此,关于“Python怎么爬取高质量超清壁纸”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





