这篇文章主要介绍“Unicorn模拟CPU执行JNI_Onload动态注册的方法”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Unicorn模拟CPU执行JNI_Onload动态注册的方法”文章能帮助大家解决问题。
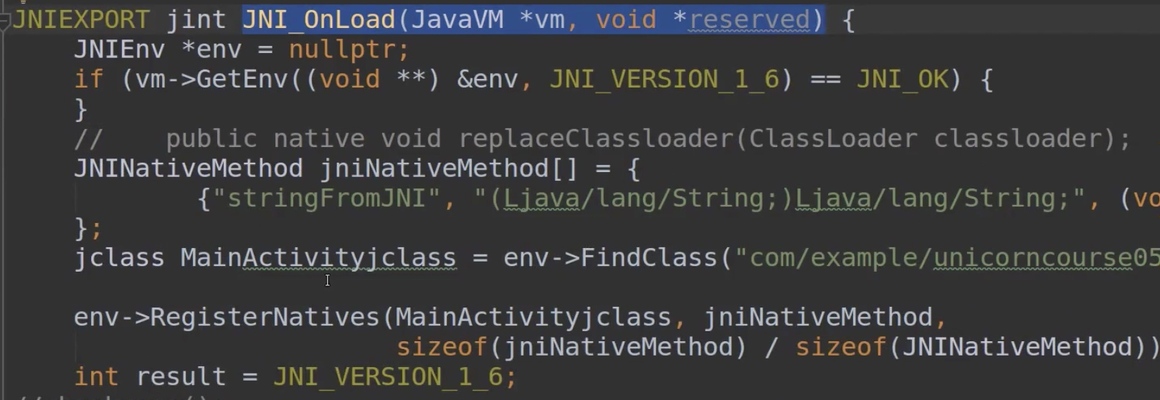 <br>步骤:
<br>步骤:
先实现 javavm 中的 GetEnv, (与模拟 jni 过程类似)一共八个函数
初始化
# 1. 开始映射
mu.mem_map(0, 0x1000) # 初始化映射 参数1:地址 参数2:空间大小 默认初始化后默认值:0
# 1.1 初始化 java vm 中的每一个函数
java_vm_base = 700*4 # 从 700*4 开始
for i in range(0, 10, 1): # 一共8个函数(5个+3个预留) 这里我预留了10个多写几个预备,也就是 10*4
mu.mem_write(i*4+java_vm_base, b'\x00\xb5\x00\xbd') # 先随便填充,保持堆栈平衡 push {lr} pop {pc}
# 1.2 初始化填充 JNIInvokeInterface 结构体
for i in range(0, 10, 1):
mu.mem_write(i*4+java_vm_base+40, struct.pack("I", i*4+java_vm_base+1)) # 注意第二个参数,要 pack 一下为 bytes, 而且是 thmob 指令集都要+1
# 1.3 初始化 Java vm 指针
javavm_pointer=700*4+80
mu.mem_write(javavm_pointer,struct.pack("I",java_vm_base+40)) # 内容指针,页就是 JNIInvokeInterface 的第一个位置所以要加 40**<br>然后添加 Hook 代码,模拟cpu 执行
注意: 想要直接通过 R2 的地址读出函数的信息,是有问题的
因为: linker 对加载的时候并不是直接映射的,而是分不通的段进行加载的!!所以位置是不通的。
解决: 要模拟加载 和 重定位
涉及: 依赖库加载,符号的解析等等工作
便捷解决: AndroidNativeEmu 已经封装好了 linker, 并且可以模拟 syscall 的执行,还提供了对函数的 hook 功能
代码如下<br>tool
import unicorn
import capstone
import struct
class Tool:
"""工具类"""
def __init__(self):
self.CP = capstone.Cs(capstone.CS_ARCH_ARM, capstone.CS_MODE_THUMB)
def capstone_print(self, code, offset, total=20):
"""
code: 代码
offset: 偏移位置
total: 最大打印行
"""
for i in self.CP.disasm(code[offset:], 0, total):
print('\033[1;32m地址: 0x%x | 操作码: %s | %s\033[0m'%(offset + i.address, i.mnemonic, i.op_str))
def readstring(self, mu,address):
"""读字符串"""
result=''
tmp=mu.mem_read(address,1)
while(tmp[0]!=0):
result=result+chr(tmp[0])
address=address+1
tmp = mu.mem_read(address, 1)
return result
def printArm32Regs(self, mu, end=78):
"""打印寄存器"""
for i in range(66, end):
print("\033[1;30m【R%d】, value:%x\033[0m"%(i-66,mu.reg_read(i)))
print("\033[1;30mSP->value:%x\033[0m" % (mu.reg_read(unicorn.arm_const.UC_ARM_REG_SP)))
print("\033[1;30mPC->value:%x\033[0m" % (mu.reg_read(unicorn.arm_const.UC_ARM_REG_PC)))
tl = Tool()
if __name__ == "__main__":
with open("so/testcalljni.so",'rb') as f:
CODE=f.read()
# tl.capstone_print(CODE, 0x0B58, 10)**<br>_ _<br>core
import unicorn
import struct
import capstone
from arm_tool import tl
def init_java_vm(mu):
"""初始化 java vm
java vm 5+3 个函数
"""
# 1. 开始映射
mu.mem_map(0, 0x1000) # 初始化映射 参数1:地址 参数2:空间大小 默认初始化后默认值:0
"""注意:要模拟 JNI_OnLoad 同样也需要先初始化 JNI"""
# 0.1 初始化填充 jni 函数
JniFuntionListbase=0x0
for i in range(0, 300): # 接近 300 个jni函数 (指针是 4 个字节)
mu.mem_write(i*4+JniFuntionListbase, b'\x00\xb5\x00\xbd') # 先随便填充,保持堆栈平衡 push {lr} pop {pc}
# 0.2 初始化填充 JNINaviteInterface 结构体, 每一项都是,jni函数的地址
# JniNativeInterFace=301 # 前面300个用于指针了,从301个开始
for i in range(300, 600): # 4 个字节都是地址
mu.mem_write(i*4, struct.pack("I", (i-300)*4+1)) # 注意第二个参数,要 pack 一下为 bytes, 而且是 thmob 指令集都要+1
# 0.3 初始化 jnienv 指针
jnienv_pointer = 601*4
mu.mem_write(jnienv_pointer, struct.pack("I", 300*4)) # 内容指针,页就是 JniNativeInterFace 的第一个 300
"""初始化 java vm"""
# 1.1 初始化 java vm 中的每一个函数
java_vm_base = 700*4 # 从 700*4 开始
for i in range(0, 10, 1): # 一共8个函数(5个+3个预留) 这里我预留了10个多写几个预备,也就是 10*4
mu.mem_write(i*4+java_vm_base, b'\x00\xb5\x00\xbd') # 先随便填充,保持堆栈平衡 push {lr} pop {pc}
# 1.2 初始化填充 JNIInvokeInterface 结构体
for i in range(0, 10, 1):
mu.mem_write(i*4+java_vm_base+40, struct.pack("I", i*4+java_vm_base+1)) # 注意第二个参数,要 pack 一下为 bytes, 而且是 thmob 指令集都要+1
# 1.3 初始化 Java vm 指针
javavm_pointer=700*4+80
mu.mem_write(javavm_pointer,struct.pack("I",java_vm_base+40)) # 内容指针,页就是 JNIInvokeInterface 的第一个位置所以要加 40
# 2. 将代码片段映射到模拟器的虚拟地址
ADDRESS = 0x1000 # 映射开始地址
SIZE = 1024*1024*10 # 分配映射大小(多分一点)
# 3. 开始映射
mu.mem_map(ADDRESS, SIZE) # 初始化映射 参数1:地址 参数2:空间大小 默认初始化后默认值:0
mu.mem_write(ADDRESS, CODE) # 写入指令 参数1: 写入位置 参数2:写入内容
# 4. 寄存器初始化 函数2个参数 (JNI_OnLoad 有两个参数)
mu.reg_write(unicorn.arm_const.UC_ARM_REG_R0, javavm_pointer) # 参数 javavm 指针
mu.reg_write(unicorn.arm_const.UC_ARM_REG_R1, 0x0) # 0
# 5. 初始化堆栈,因为要对内存进行操作 设置 SP
SP = ADDRESS+SIZE-16 # 多减点,预留 sp 剩下两个参数的位置
mu.reg_write(unicorn.arm_const.UC_ARM_REG_SP,SP)
# 6. 添加 hook 代码
"""注意: hook 的时候加上区间可以极大的提升hook效率!!"""
mu.hook_add(unicorn.UC_HOOK_CODE, hook_code)
# mu.hook_add(unicorn.UC_HOOK_MEM_WRITE, hook_mem) # 跟踪 cpu 执行内存操作, 需要自写回调函数
# mu.hook_add(unicorn.UC_HOOK_INTR,hook_syscall) # hook 系统调用函数
# mu.hook_add(unicorn.UC_HOOK_BLOCK,hook_block) # hook 基本块
# 7. 开始运行
add_satrt = ADDRESS+0xc00+1 # 偏移位置 ida 查看 THUMB 指令集奇数所以要 ADDRESS +1,
add_end = ADDRESS+0xC66 # 调用完 registnative 返回即可
try:
mu.emu_start(add_satrt, add_end) # 参数1:起始位置,参数2:结束位置
print('-------- unicorn 执行后--------')
r0value = mu.reg_read(unicorn.arm_const.UC_ARM_REG_R0)
print('执行结果: ', tl.readstring(mu, r0value))
except unicorn.UcError as e:
print('\033[1;31mError: %s \033[0m' % e)
def hook_code(mu,address,size,user_data):
"""定义回调函数, 在进入汇编指令之前就会先运行这里
mu: 模拟器
address: 执行地址
size: 汇编指令大小
user_data: 通过 hook_add 添加的参数
"""
code=mu.mem_read(address,size) # 读取
if address>=700*4 and address<=710*4:
index=(address-700*4)/4
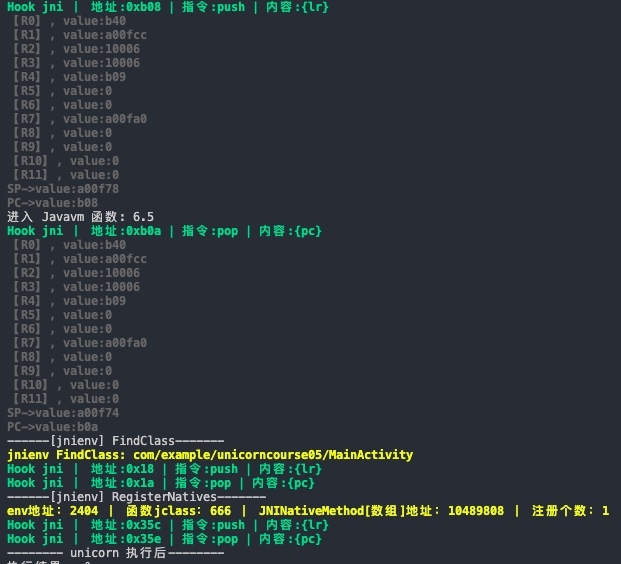
print('进入 Javavm 函数: '+str(index))
if index==6:
print("调用 javavm->GetEnv---------------:" + str(index))
# jint (*GetEnv)(JavaVM*, void**, jint); 第二个参数才是,返回的值,所以要用 R1 !!!!!
"""第二个参数才是,返回的值,所以要用 R1 !!!!!"""
r1value = mu.reg_read(unicorn.arm_const.UC_ARM_REG_R1) # 将 ENV 指针 写入 jni 第一个参数中,即可
mu.mem_write(r1value,struct.pack("I",601*4)) # 也就是我们初始化 jni 的时候的指针地址
CP=capstone.Cs(capstone.CS_ARCH_ARM,capstone.CS_MODE_THUMB)
for i in CP.disasm(code,0,len(code)):
print("\033[1;32mHook jni | 地址:0x%x | 指令:%s | 内容:%s\033[0m"%(address,i.mnemonic,i.op_str))
tl.printArm32Regs(mu)
elif address>=0 and address<=300*4: # 返回属于我们自己写的 jni 函数的区域的时候
index=(address-0)/4 # 拿到第几个 jni 函数
if index==6: # 676/4 6 = FindClass 就可以捕获到,类的完整类名
print("------[jnienv] FindClass-------")
# jclass (*FindClass)(JNIEnv*, const char*); 是第二个参数返回的值 所以是 R1
r1value = mu.reg_read(unicorn.arm_const.UC_ARM_REG_R1)
classname=tl.readstring(mu,r1value)
#666 com/example/unicorncourse05/MainActivity
print("\033[1;33mjnienv FindClass: %s\033[0m" %classname)
mu.reg_write(unicorn.arm_const.UC_ARM_REG_R0,666) # 随便写一个值来代表这个引用!
elif index == 215: # 第二部,调用 注册函数
# jint (*RegisterNatives)(JNIEnv*, jclass, const JNINativeMethod*,jint);
print("------[jnienv] RegisterNatives-------")
r0value = mu.reg_read(unicorn.arm_const.UC_ARM_REG_R0) # 也就是我们前面写好的 601 * 4 = 2404
r1value = mu.reg_read(unicorn.arm_const.UC_ARM_REG_R1) # 也就是上面随便写的一个值
r2value = mu.reg_read(unicorn.arm_const.UC_ARM_REG_R2) # JNINativeMethod 地址 (数组)
"""
注意: 想要直接通过 R2 的地址读出函数的信息,是有问题的
因为: linker 对加载的时候并不是直接映射的,而是分不通的段进行加载的!!所以位置是不通的。
解决: 要模拟加载 和 重定位
涉及: 依赖库加载,符号的解析等等工作
便捷解决: AndroidNativeEmu 已经封装好了 linker, 并且可以模拟 syscall 的执行,还提供了对函数的 hook 功能
"""
# funcname_bytearray=mu.mem_read(r2value,4)
# funcname_addr=struct.unpack("I",funcname_bytearray);
# print(tl.readstring(mu,funcname_addr))
r3value = mu.reg_read(unicorn.arm_const.UC_ARM_REG_R3)
print("\033[1;33menv地址:"+str(r0value)+" | 函数jclass:"+str(r1value)+" | JNINativeMethod[数组]地址:"+str(r2value)+" | 注册个数:"+str(r3value)+"\033[0m")
CP=capstone.Cs(capstone.CS_ARCH_ARM,capstone.CS_MODE_THUMB)
for i in CP.disasm(code,0,len(code)):
print("\033[1;32mHook jni | 地址:0x%x | 指令:%s | 内容:%s\033[0m"%(address,i.mnemonic,i.op_str))
return
def hook_mem(mu, type, address, size, value, user_data):
"""
读和写内存的 mem hook 回调
"""
msg = None
print('\033[1;32m=== Hook cpu ===\033[0m')
if type==unicorn.UC_MEM_WRITE:
msg = """\033[1;32m内存操作 %s 地址: 0x%x | hook_mem 类型: %s| 大小: %s | 值: 0x%x\033[0m"""%('写入',address,type,size,value)
if type==unicorn.UC_MEM_READ:
msg = """\033[1;32m内存操作 %s 地址: 0x%x | hook_mem 类型: %s| 大小: %s | 值: 0x%x\033[0m"""%('读取',address,type,size,value)
print(msg)
return
def hook_syscall(mu,intno,user_data):
print("\033[1;36mhook 系统调用 系统调用号: 0x%d"%intno)
if intno==2: # 例子 2 是退出
print("系统调用退出!!")
# print_result(mu)
print("\033[0m")
return
def hook_block(mu, address, size, user_data):
# code = mu.mem_read(address,size)
print("\033[1;36mhook 基本块")
# print_result(mu)
print("\033[0m")
return
if __name__ == "__main__":
with open("so/unicorn05.so",'rb') as sofile:
CODE=sofile.read()
mu = unicorn.Uc(unicorn.UC_ARCH_ARM, unicorn.UC_MODE_THUMB)
tl.capstone_print(CODE, 0xc00)
init_java_vm(mu) # 初始化 java vm运行效果
关于“Unicorn模拟CPU执行JNI_Onload动态注册的方法”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





