这篇文章给大家介绍Elasticsearch写入数据底层的示例分析,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
Document(文档): 文档是存储在elasticsearch中的一个JSON文件,相当于关系数据库中表的一行数据。
Shard(分片):索引数据可以拆分为较小的分片,每个分片放到不同的服务器上,提高并发能力。 Lucene 中的 Lucene index 相当于 ES 的一个 shard。
Segments(段): 分片由多个segments组成,每个segments都是一个独立的倒排索引,且具有不变性,segment 提供了搜索功能。
Transaction Log(translog,事务日志):Elasticsearch使用translog来记录index,delete,update,bulk请求,保障数据不丢失,如果Elasticsearch需要恢复数据可以从translog中读取。每个分片对应一个translog文件。
Commit point(提交点):记录着所有已知的segment,每个Shard都有一个Commit point, 其中保存了当前Shard成功写入磁盘的所有Segment。
Lucene index :由一堆 Segment 的集合加上一个Commit point组成。
OS Cache: Lucene 中的倒排索引 segments 存储在文件中,为提高访问速度,都会把它加载到OS Cache中,从而提高 Lucene 性能,所以建议至少留系统一半内存给Lucene。
Node Query Cache:负责缓存filter 查询结果,每个节点有一个,被所有 shard 共享,filter query查询结果不涉及 scores 的计算。
Indexing Buffe:索引缓冲区,用于存储新索引的文档,当其被填满时,缓冲区中的文档被写入磁盘中的 segments 中。
Shard Request Cache: 用于缓存aggregations,suggestions,hits.total的请求结果。
Field Data Cache:Elasticsearch 加载内存 fielddata 的默认行为是延迟加载 。在首次对text类型字段做聚合、排序或者在脚本中使用时,需要设置字段为fielddata数据结构,它将会完整加载这个字段所有 Segment 中的倒排索引到堆内存中。不推荐使用,因为fielddata会占用大量堆内存空间 ,聚合或者排序使用doc_value。
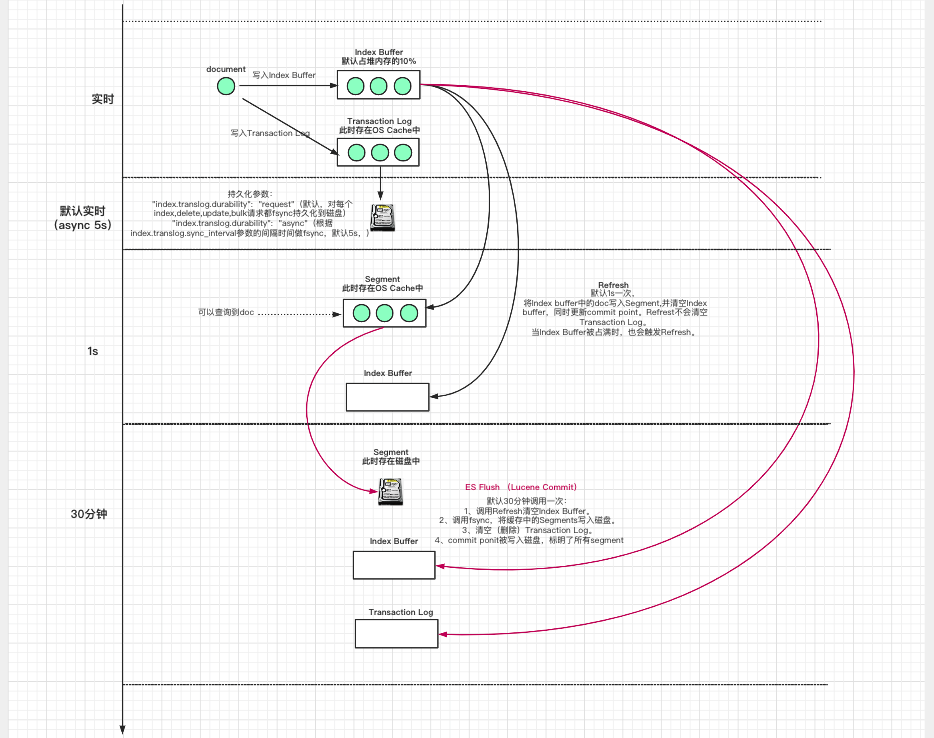
1.数据写入Index Buffer缓冲和Translog日志文件。
为了保证数据不会丢失,从高版本开始Transaction Log对每个index,delete,update,bulk请求都fsync持久化到磁盘。
2.Refresh:将Index Buffer写入Segment的过程叫做Refresh。
每隔1s,Index Buffer中的数据被写入新的Segment(OS Cache中),此时Segment被打开并提供Search。Refresh后,数据就可以被搜索到了,这也是为什么Elasticsearch被称为近实时搜索的原因。
当Index Buffer被占满时,会触发Refresh,默认值是JVM堆内存的10%。
Refresh不执行fsync操作,不会清空Transaction Log。
3.重复1~2步,新的Segment不断添加,Index Buffer不断被清空,而Transaction Log中的数据不断累加。
4.每隔30分钟或者当Transaction Log用满时(默认512M),ES Flush (Lucene Commit) 操作发生:
4.1 调用Refresh清空Index Buffer。
4.2 调用fsync,将缓存中的Segments写入磁盘。
4.3 清空(删除)Transaction Log。
4.4 Commit ponit被写入磁盘,每个Shard都有一个Commit point, 其中保存了当前Shard成功写入磁盘的所有Segment。
PUT my-index/_settings
{
"refresh_interval": "60s" #默认1s
}PUT my-index/_settings
{
"translog.flush_threshold_size": "1gb", #默认512M,当 translog 超过该值,会触发 flush
"translog.sync_interval": "60s", #默认5s
"translog.durability": "async" #默认是 request,每个请求都落盘,忽视translog.sync_interval。设置成 async,异步写入,根据index.translog.sync_interval参数的间隔时间做fsync。
}关于Elasticsearch写入数据底层的示例分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4923278/blog/4972899



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



