如何进行Spark大数据分析,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
之前的Flask的基础教程暂时先结束了。 因为目前所涉及到的东西已经能够满足我的需要。剩下的东西都是根据需求修改和优化。 不涉及更多的东西。 所以我也就是平时维护着,我们接下来讲讲Spark,为什么要讲Spark呢,因为我们性能测试的需求要造10亿级甚至更多的数据。普通的方式肯定不行了,得用到spark提交到yarn上运行才跑的动。所以现在我们来谈论谈论大数据方面的东西。同时大数据也是人工智能的基础,现在搞搞大数据的东西,也为以后讨论人工智能方面的测试做做铺垫吧。
万事开头难,我刚接触大数据的那会是天天的一脸懵逼。因为以前只跟数据库打过交道,对于hadoop生态圈完全是没听过的状态。看资料的时候也根本看不懂。所以我先介绍一下基础的概念吧。
大数据,首先要能存的下大数据。 传统的数据库虽然衍生了主从,分片。但是他们在存储上也无法应对TB甚至PB的数据量,尤其是在计算处理上他们更无法突破单机计算的桎梏。因为我们传统的文件系统是单机的,不能横跨不同的机器。在前些年的时候随着互联网的崛起,我们进入了数据爆炸的时代。传统的数据存储方式不论在存储量上还是计算性能上都已经越来越跟不上数据发展的速度了。当时开发一个新的方式处理数据在业界呼声很高。之后在04年(好像是吧,记不清了)Google发表了论文--MapReduce,详细讲述了Google的分布式计算原理。这时候业界才发现原来数据还可以这么玩,但是Google的良心大大滴坏,他只发了论文但是没有开源,这把一干人等急的抓耳挠腮,后来Apache组织了一帮人根据Google的论文糊出了一个hadoop。直到现在hadoop生态已经发展了10余年(是的没错,我们现在看的很高大上的hadoop技术是人家Google玩剩下的)。
先前说我们传统的文件系统是单机的,无法横跨不同的机器。而HDFS的出现(Hadoop Distributed FileSystem),打破了我们单机的限制。HDFS是Apache专门研发的分布式文件系统。设计本质上是为了大量的数据能横跨成百上千台机器,但是你看到的是一个文件系统而不是多个。比如说我要取/hdfs/gaofei/file1上的数据。你引用的是一个文件路径,但是实际的数据是存放在很多个不同的机器上的。作为用户,我们不知道实际的物理存储结构,我们知道的只要暴露给我们的逻辑路径。那么在我们有能力存在这么大的数据后,就开始考虑怎么处理数据了。 虽然HDFS帮助我们管理不同机器上的数据并抽象一个统一接口给我们。但是这仍然改变不了这些数据非常大的事实。 如果我们仍然是在一台机器上处理这海量的数据,那性能上仍然是不可接受的。那么如果我们要在多台机器上同时处理这些数据,就面临了一个机器之间如何通信和调度的问题。 这就是MapReduce/Spark的功能。MapReduce是第一代的产物,Apache研发的hadoop就是基于MapReduce框架(根据Google的论文而来)。Spark是第二代。 MapReduce采用了很简化的模型,只有Map和Reduce两个计算过程(中间用shuffle串联)。
那什么是MapReduce呢, 举个最常用的wordcount的例子。 假如你需要统计一个巨大的文件中所有单词出现的词频。 首先你需要很多台机器同时并发的读取这个文件的各个部分,分别把自己读到的部分进行第一步计算。 假如在这台机器上,我读取了一部分数据,对这些数据统计出了类似(Hello--100次)(word--1000次)这样的结果。 每台机器都读取了部分数据并做了相同的操作。这就是MapReduce中的Map阶段(额,中间其实还有别的操作,恕我学艺不精,解释不清了)。然后我们进入Reduce阶段,这个阶段也会并发启动很多的机器,框架会将Map机器上的数据按一定规则分别放到这些Reduce机器上进行计算。 例如我们把所有Hello这个单词的放在ReduceA上,把所有word这个单词的数据放到ReduceB上。然后ReduceA汇总所有的Map数据中的Hello这个单词的结果,计算出这个单词在数据中出现的词频为1000次。 ReduceB汇总所有Word这个单词并计算出它在数据中出现的词频为1000次。这样我们就统计出了这个巨大文件的词频了。 这就是MapReduce, 可以简单理解为Map阶段并发机器读取不同的数据块做第一步处理,然后Reduce阶段并发机器按规则汇总Map阶段的数据做第二部处理。中间有个很重要的过程是shuffle,暂时可以理解为这个shuffle就是哪些Map的数据放到哪个Reduce上的规则过程。详细的不表示了,shuffle这个东西有点复杂,我们之后再讲。
MapReduce的模型简单暴力,但是程序写起来真麻烦。因为全靠程序员编码,框架只是提供了Map和Reduce的函数,至于里面什么逻辑全靠你自己写。于是有了pig和Hive。Pig我没怎么了解过,Hive是基于SQL的,它们把SQL翻译成的MapReduce程序。有了Hive以后,大家发现Sql实在太容易写了,这比写java代码方便太多了。例如我司的产品中,专门有一个算子是sql,可以让业务人员也sql做拼表的动作。但是我们发现Hive在MapReduce上跑的特别慢,这个实在让人接受不了。 于是中间又经过了几个引擎的进化,Spark和SparkSQL应运而生。Spark不仅拥有新一代的计算引擎(跑的更快),而且内置了很多的方法供你操作数据,我们编写起程序来现在变的更快更简单。假如我们有这么一个需求,统计一个文件中a,b这两个字母出现的单词有多少个。 可以像下面这样写:
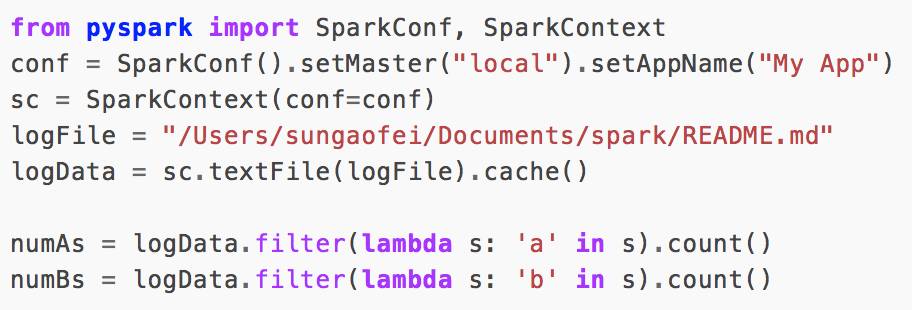
numAs和numBs就是我们统计的结果。可以看到spark提供了filter这种过滤函数和count这种内置的统计数量函数。 我们不再像以前MapReduce一样要写那么多的逻辑。 同时SparkSQL也支持了我们把SQL翻译成代码的功
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/asf/blog/4632678



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



