怎样理解Flink处理函数中的KeyedProcessFunction类,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
今天要了解的KeyedProcessFunction,以及该类带来的一些特性;
通过对比类图可以确定,KeyedProcessFunction和ProcessFunction并无直接关系: 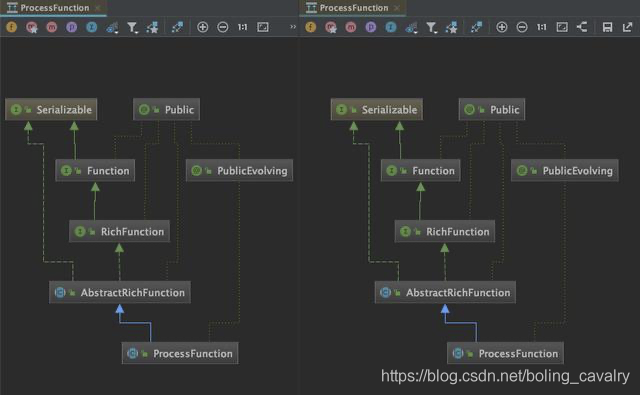 KeyedProcessFunction用于处理KeyedStream的数据集合,相比ProcessFunction类,KeyedProcessFunction拥有更多特性,官方文档如下图红框,状态处理和定时器功能都是KeyedProcessFunction才有的:
KeyedProcessFunction用于处理KeyedStream的数据集合,相比ProcessFunction类,KeyedProcessFunction拥有更多特性,官方文档如下图红框,状态处理和定时器功能都是KeyedProcessFunction才有的:  介绍完毕,接下来通过实例来学习吧;
介绍完毕,接下来通过实例来学习吧;
开发环境操作系统:MacBook Pro 13寸, macOS Catalina 10.15.3
开发工具:IDEA ULTIMATE 2018.3
JDK:1.8.0_211
Maven:3.6.0
Flink:1.9.2
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在<font color="blue">flinkstudy</font>文件夹下,如下图红框所示: 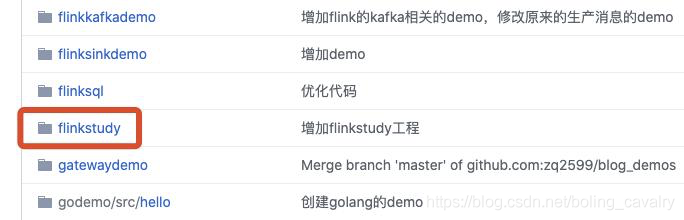
本次实战的目标是学习KeyedProcessFunction,内容如下:
监听本机9999端口,获取字符串;
将每个字符串用空格分隔,转成Tuple2实例,f0是分隔后的单词,f1等于1;
上述Tuple2实例用f0字段分区,得到KeyedStream;
KeyedSteam转入自定义KeyedProcessFunction处理;
自定义KeyedProcessFunction的作用,是记录每个单词最新一次出现的时间,然后建一个十秒的定时器,十秒后如果发现这个单词没有再次出现,就把这个单词和它出现的总次数发送到下游算子;
继续使用《Flink处理函数实战之二:ProcessFunction类》一文中创建的工程flinkstudy;
创建bean类CountWithTimestamp,里面有三个字段,为了方便使用直接设为public:
package com.bolingcavalry.keyedprocessfunction;
public class CountWithTimestamp {
public String key;
public long count;
public long lastModified;
}创建FlatMapFunction的实现类Splitter,作用是将字符串分割后生成多个Tuple2实例,f0是分隔后的单词,f1等于1:
package com.bolingcavalry;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.apache.flink.util.StringUtils;
public class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
if(StringUtils.isNullOrWhitespaceOnly(s)) {
System.out.println("invalid line");
return;
}
for(String word : s.split(" ")) {
collector.collect(new Tuple2<String, Integer>(word, 1));
}
}
}最后是整个逻辑功能的主体:ProcessTime.java,这里面有自定义的KeyedProcessFunction子类,还有程序入口的main方法,代码在下面列出来之后,还会对关键部分做介绍:
package com.bolingcavalry.keyedprocessfunction;
import com.bolingcavalry.Splitter;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author will
* @email zq2599@gmail.com
* @date 2020-05-17 13:43
* @description 体验KeyedProcessFunction类(时间类型是处理时间)
*/
public class ProcessTime {
/**
* KeyedProcessFunction的子类,作用是将每个单词最新出现时间记录到backend,并创建定时器,
* 定时器触发的时候,检查这个单词距离上次出现是否已经达到10秒,如果是,就发射给下游算子
*/
static class CountWithTimeoutFunction extends KeyedProcessFunction<Tuple, Tuple2<String, Integer>, Tuple2<String, Long>> {
// 自定义状态
private ValueState<CountWithTimestamp> state;
@Override
public void open(Configuration parameters) throws Exception {
// 初始化状态,name是myState
state = getRuntimeContext().getState(new ValueStateDescriptor<>("myState", CountWithTimestamp.class));
}
@Override
public void processElement(
Tuple2<String, Integer> value,
Context ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
// 取得当前是哪个单词
Tuple currentKey = ctx.getCurrentKey();
// 从backend取得当前单词的myState状态
CountWithTimestamp current = state.value();
// 如果myState还从未没有赋值过,就在此初始化
if (current == null) {
current = new CountWithTimestamp();
current.key = value.f0;
}
// 单词数量加一
current.count++;
// 取当前元素的时间戳,作为该单词最后一次出现的时间
current.lastModified = ctx.timestamp();
// 重新保存到backend,包括该单词出现的次数,以及最后一次出现的时间
state.update(current);
// 为当前单词创建定时器,十秒后后触发
long timer = current.lastModified + 10000;
ctx.timerService().registerProcessingTimeTimer(timer);
// 打印所有信息,用于核对数据正确性
System.out.println(String.format("process, %s, %d, lastModified : %d (%s), timer : %d (%s)\n\n",
currentKey.getField(0),
current.count,
current.lastModified,
time(current.lastModified),
timer,
time(timer)));
}
/**
* 定时器触发后执行的方法
* @param timestamp 这个时间戳代表的是该定时器的触发时间
* @param ctx
* @param out
* @throws Exception
*/
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
// 取得当前单词
Tuple currentKey = ctx.getCurrentKey();
// 取得该单词的myState状态
CountWithTimestamp result = state.value();
// 当前元素是否已经连续10秒未出现的标志
boolean isTimeout = false;
// timestamp是定时器触发时间,如果等于最后一次更新时间+10秒,就表示这十秒内已经收到过该单词了,
// 这种连续十秒没有出现的元素,被发送到下游算子
if (timestamp == result.lastModified + 10000) {
// 发送
out.collect(new Tuple2<String, Long>(result.key, result.count));
isTimeout = true;
}
// 打印数据,用于核对是否符合预期
System.out.println(String.format("ontimer, %s, %d, lastModified : %d (%s), stamp : %d (%s), isTimeout : %s\n\n",
currentKey.getField(0),
result.count,
result.lastModified,
time(result.lastModified),
timestamp,
time(timestamp),
String.valueOf(isTimeout)));
}
}
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并行度1
env.setParallelism(1);
// 处理时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// 监听本地9999端口,读取字符串
DataStream<String> socketDataStream = env.socketTextStream("localhost", 9999);
// 所有输入的单词,如果超过10秒没有再次出现,都可以通过CountWithTimeoutFunction得到
DataStream<Tuple2<String, Long>> timeOutWord = socketDataStream
// 对收到的字符串用空格做分割,得到多个单词
.flatMap(new Splitter())
// 设置时间戳分配器,用当前时间作为时间戳
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple2<String, Integer>>() {
@Override
public long extractTimestamp(Tuple2<String, Integer> element, long previousElementTimestamp) {
// 使用当前系统时间作为时间戳
return System.currentTimeMillis();
}
@Override
public Watermark getCurrentWatermark() {
// 本例不需要watermark,返回null
return null;
}
})
// 将单词作为key分区
.keyBy(0)
// 按单词分区后的数据,交给自定义KeyedProcessFunction处理
.process(new CountWithTimeoutFunction());
// 所有输入的单词,如果超过10秒没有再次出现,就在此打印出来
timeOutWord.print();
env.execute("ProcessFunction demo : KeyedProcessFunction");
}
public static String time(long timeStamp) {
return new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date(timeStamp));
}
}上述代码有几处需要重点关注的:
通过assignTimestampsAndWatermarks设置时间戳的时候,getCurrentWatermark返回null,因为用不上watermark;
processElement方法中,state.value()可以取得当前单词的状态,state.update(current)可以设置当前单词的状态,这个功能的详情请参考《深入了解ProcessFunction的状态操作(Flink-1.10)》;
registerProcessingTimeTimer方法设置了定时器的触发时间,注意这里的定时器是基于processTime,和官方demo中的eventTime是不同的;
定时器触发后,onTimer方法被执行,里面有这个定时器的全部信息,尤其是入参timestamp,这是原本设置的该定时器的触发时间;
在控制台执行命令nc -l 9999,这样就可以从控制台向本机的9999端口发送字符串了;
在IDEA上直接执行ProcessTime类的main方法,程序运行就开始监听本机的9999端口了;
在前面的控制台输入aaa,然后回车,等待十秒后,IEDA的控制台输出以下信息,从结果可见符合预期: 
继续输入aaa再回车,连续两次,中间间隔不要超过10秒,结果如下图,可见每一个Tuple2元素都有一个定时器,但是第二次输入的aaa,其定时器在出发前,aaa的最新出现时间就被第三次输入的操作给更新了,于是第二次输入aaa的定时器中的对比操作发现此时距aaa的最近一次(即第三次)出现还未达到10秒,所以第二个元素不会发射到下游算子: 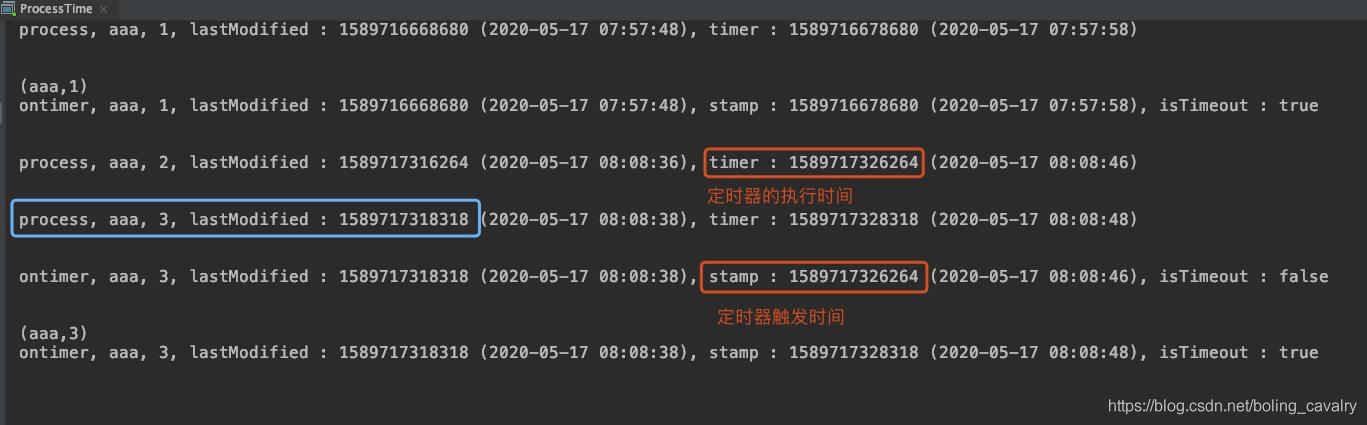
下游算子收到的所有超时信息会打印出来,如下图红框,只打印了数量等于1和3的记录,等于2的时候因为在10秒内再次输入了aaa,因此没有超时接收,不会在下游打印: 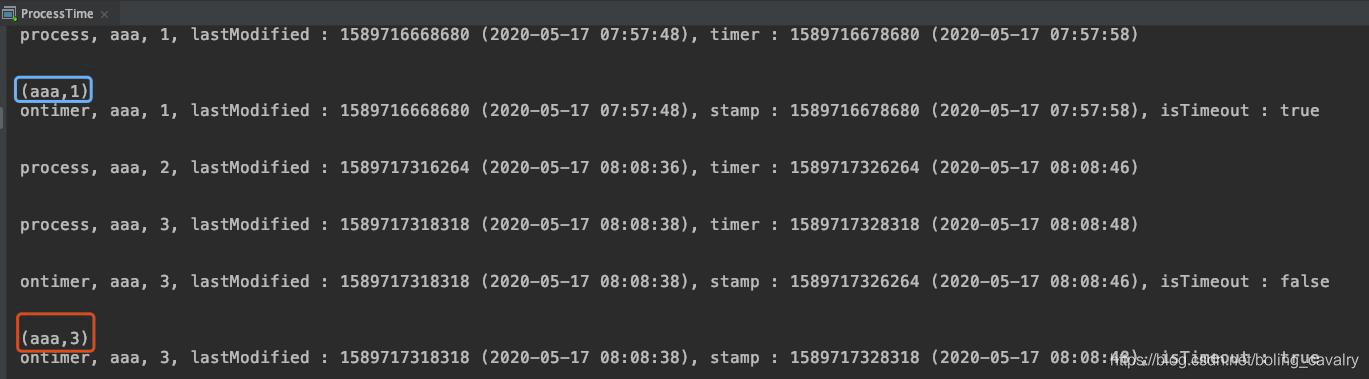 至此,KeyedProcessFunction处理函数的学习就完成了,其状态读写和定时器操作都是很实用能力。
至此,KeyedProcessFunction处理函数的学习就完成了,其状态读写和定时器操作都是很实用能力。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/zq2599/blog/4731847



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



