这篇文章将为大家详细讲解有关基于Flink如何实现解决数据库分库分表任务拆分,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
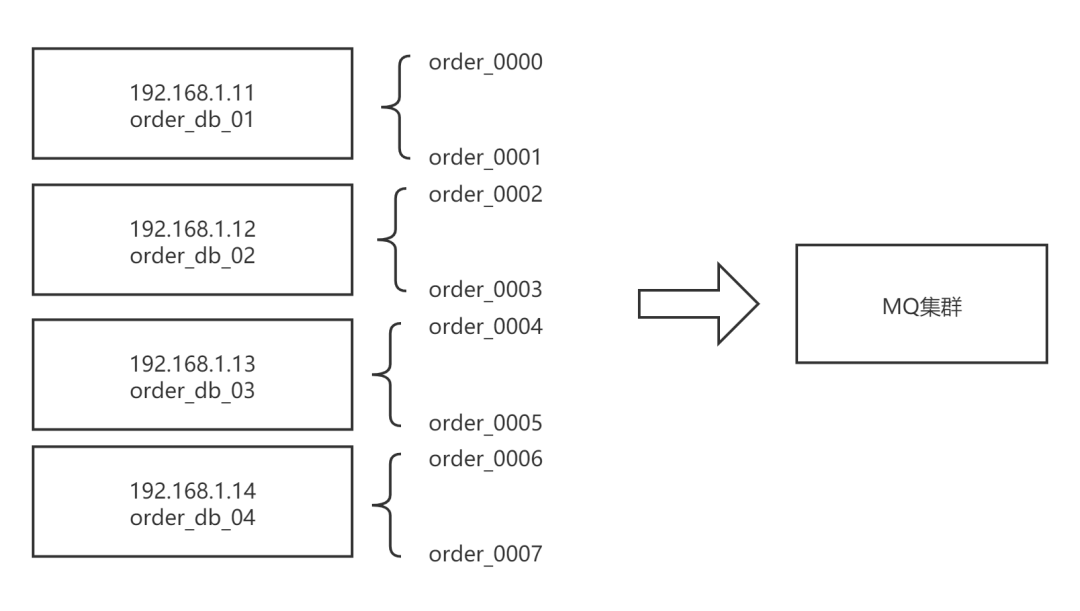
例如订单库进行了分库分表,其示例如下图所示:
使用 Flink Stream API 编程的通用步骤如下图所示:
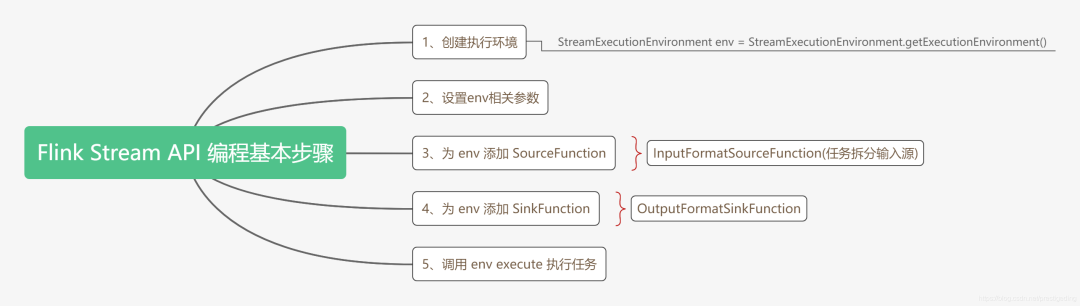
温馨提示:有关 Stream API 的详细内容将在后续的文章中展开,本文主要是关注 InputFormatSourceFunction,重点关注数据源的拆分。

InputFormat
flink 核心API,主要是对输入源进行数据切分、读取数据的抽象,其核心接口说明如下:
void configure(Configuration parameters)
对输入源进行额外的配置,该方法在 Input 的生命周期中只需调用一次。
BaseStatistics getStatistics(BaseStatistics cachedStatistics)
返回 input 的统计数据,如果不需要统计,在实现的时候可以直接返回 null。
T[] createInputSplits(int minNumSplits)
对输入数据进行数据切片,使之支持并行处理,数据切片相关类体系见:InputSplit。
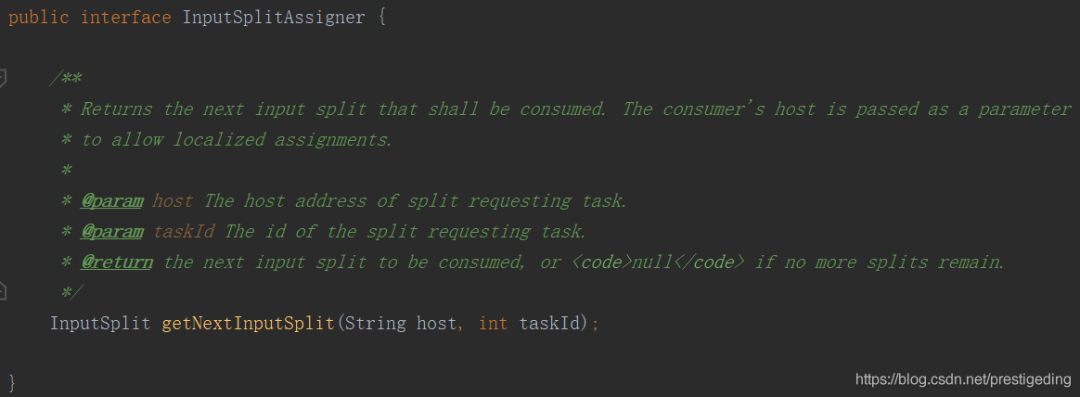
InputSplitAssigner getInputSplitAssigner(T[] inputSplits)
获取 InputSplit 分配器,主要是在具体执行任务时如何获取下一个 InputSplit,其声明如下图所示:
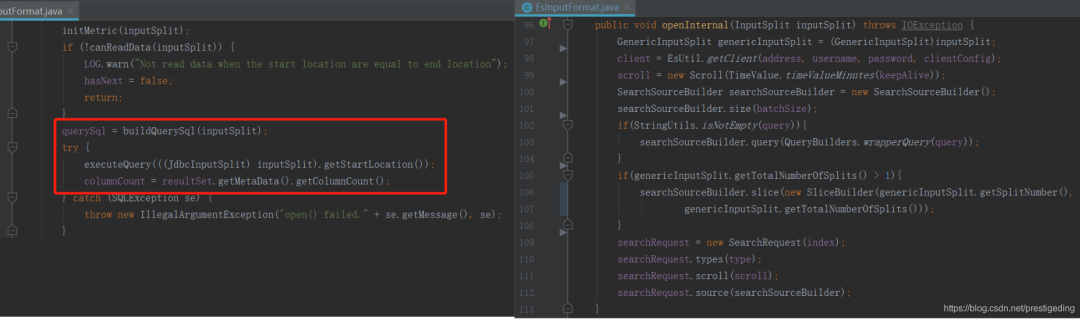
void open(T split)
根据指定的数据分片 (InputSplit) 打开数据通道。为了加深对该方法的理解,下面看一下 Flinkx 关于 jdbc、es 的写入示例:
boolean reachedEnd()
数据是否已结束,在 Flink 中通常 InputFormat 的数据源通常表示有界数据 (DataSet)。
OT nextRecord(OT reuse)
从通道中获取下一条记录。
void close()
关闭。
InputSplit
数据分片根接口,只定义了如下方法:
int getSplitNumber()
获取当前分片所在所有分片中的序号。
本文先简单介绍一下其通用实现子类:GenericInputSplit。
int partitionNumber
当前 split 所在的序号
int totalNumberOfPartitions
总分片数
为了方便理解我们可以思考一下如下场景,对于一个数据量超过千万级别的表,在进行数据切分时可以考虑使用10个线程,即切割成 10分,那每一个数据线程查询数据时可以 id % totalNumberOfPartitions = partitionNumber,进行数据读取。
SourceFunction
Flink 源的抽象定义。
RichFunction
富函数,定义了生命周期、可获取运行时环境上下文。
ParallelSourceFunction
支持并行的 source function。
RichParallelSourceFunction
并行的富函数
InputFormatSourceFunction
Flink 默认提供的 RichParallelSourceFunction 实现类,可以当成是RichParallelSourceFunction 的通用写法,其内部的数据读取逻辑由 InputFormat 实现。
BaseDataReader
flinkx 数据读取基类,在 flinkx 中将所有的数据读取源封装成 Reader 。
经过了上面类图的梳理,大家应该 flink 中提到的上述类的含义有了一个大概的理解,但如何运用呢?接下来将通过查阅 flinkx 的 DistributedJdbcDataReader(BaseDataReader的子类)的 readData 调用流程,体会一下其使用方法。
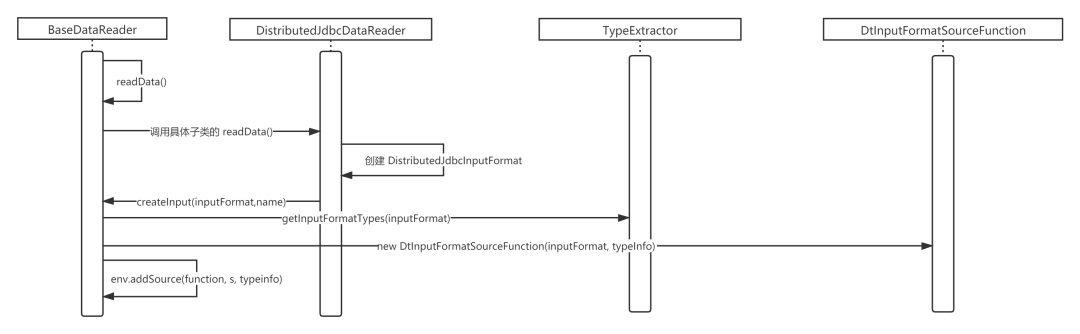
正如本文开头部分的场景描述那样,某订单系统被设计成4库8表,每一个库(Schema)中包含2个表,如何提高数据导出的性能呢,如何提高数据的抽取性能呢?通常的解决方案如下:
首先按库按表进行拆分,即4库8表,可以进行切分8份,每一个数据分配处理一个实例中的1个表。
单个表的数据抽取再进行拆分,例如按ID进行取模进一步分解。
flinkx 就是采取上面的策略,我们来看一下其具体做法。
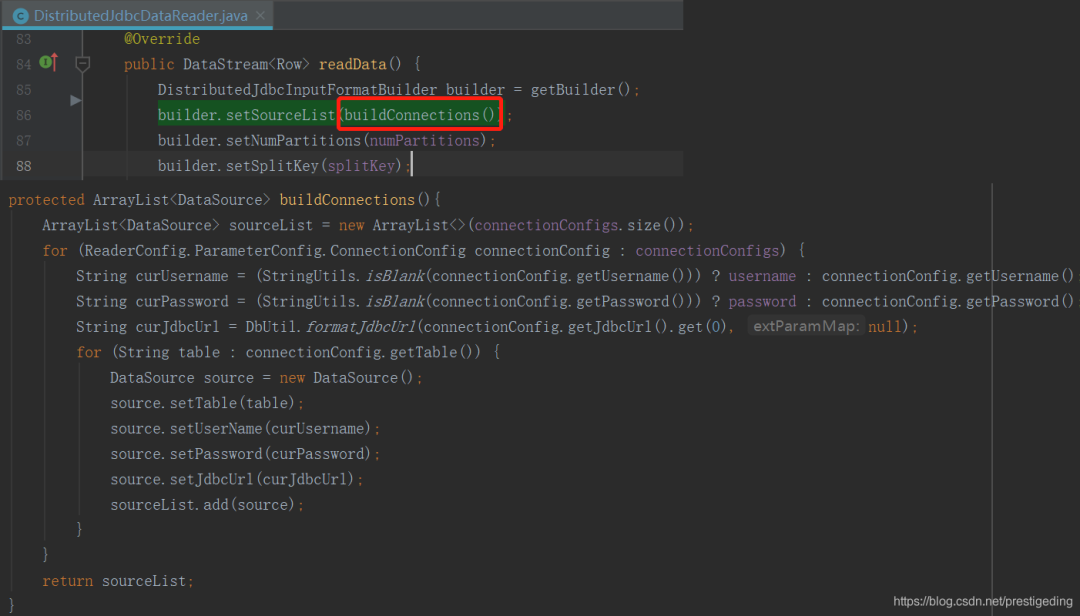
接下来具体的任务拆分在 InputFormat 中实现,本实例在 DistributedJdbcInputFormat 的 createInputSplitsInternal 中。


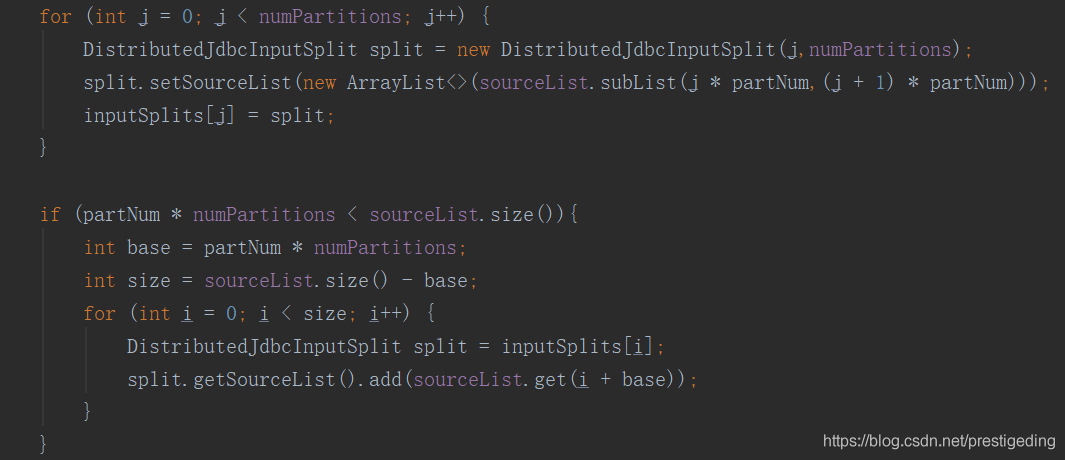
关于 flinkx 中关于任务切分的介绍就到这里了。
本文主要是基于 flinkx 介绍 MySQL 分库分表情况下如何基于 flink 进行任务切分,简单介绍了 Flink 中关于基本的编程范式、InputFormat、SourceFunction 的基本类体系。
关于基于Flink如何实现解决数据库分库分表任务拆分就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





