这篇文章主要讲解了“Fractured Mirrors知识点有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Fractured Mirrors知识点有哪些”吧!
背景知识
PAX 是优化 NSM 的 cache 表现,而这篇文章主要关注磁盘IO。NSM 主要针对投影率和选择率都比较高的场景,而 DSM 适用投影率和选择率都比较低的场景。
投影率(projectivity)就是 select 语句后边跟的列数,就是查询的列数。投影率高就是查的列多。选择率(selectivity)就是挑剔度,选择率高,结果集就少。
投影率和选择率都高,就是只选择很少的数据,并且把这些数据的大部分属性都拿出来,比较适合 NSM。
DSM 的缺点及实现优化
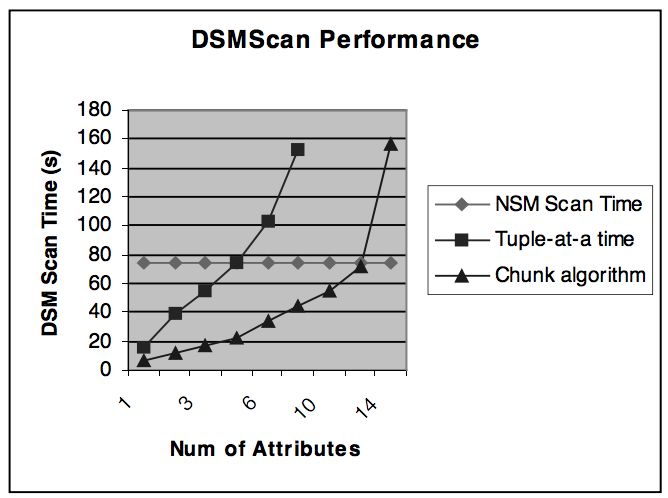
都说 DSM 重组数据耗时,到底多耗时呢?这篇文章给出了一个测试结果。
用 TPC-H 数据集的 Line-item 表(每行数据有16个属性),一共 1GB 数据。采用 NSM 会占用 1.1 GB 磁盘空间,并且一个全表扫描需要 74.5 秒。
DSM (16个关系,每个关系表有一个 ID 列和一个属性列)占用 2.8 GB 空间,
为了实现全表扫描,需要对每行数据都重组,随着选择的列数从 1 列到 8列,扫描的时间为 68.29s 到 759.39s。比 NSM 模型差的有点大,即使只选择一列也没好多少。

这和我一直说的 DSM 在选择列数少的时候性能很好说法相悖啊,这里有实现问题,作者是用一种最简单的 DSM 实现对比的,用 slotted page 存放每一对 《ID,属性列》,不管这个属性列是定长还是变长。这种实现方式比较浪费空间。
除此之外,每个属性需要带一个 ID,比较浪费空间,虽然现在磁盘几乎没啥成本,多占空间不是问题,但是多占空间会导致多占 IO,这就成问题了。因此,减少 IO 数据传输是很有必要的。
作者针对 DSM 的一些实现上的问题,提出了一个稀疏的 B-Tree 索引,去掉了多余的 ID 列。在这些 DSM 优化的基础上,又提出了一个基于 Chunk 的多路归并算法,主要思想就是从单点加载变成批量加载。
作者比较了优化后的单点加载算法、批量加载的算法以及 NSM 扫描的时间。这基本是 DSM 应该有的速度,可以看到一种思想的表现和实现也很相关,你可以把一个非常巧妙的想法实现成一坨屎,也可以把一个很傻的算法实现的很快。
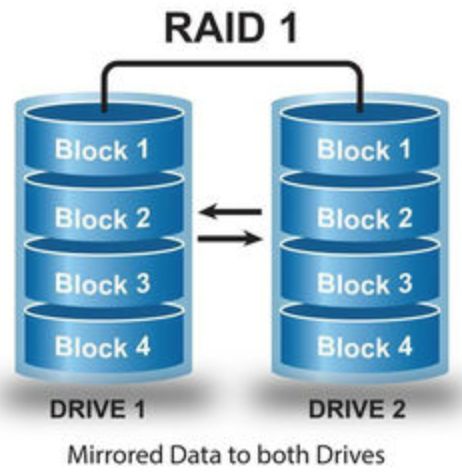
镜像:Raid 1
镜像技术就是使用两块磁盘将数据做个拷贝,两块盘都可以对外提供访问服务,做负载均衡。两块盘的数据存储结构都一样。
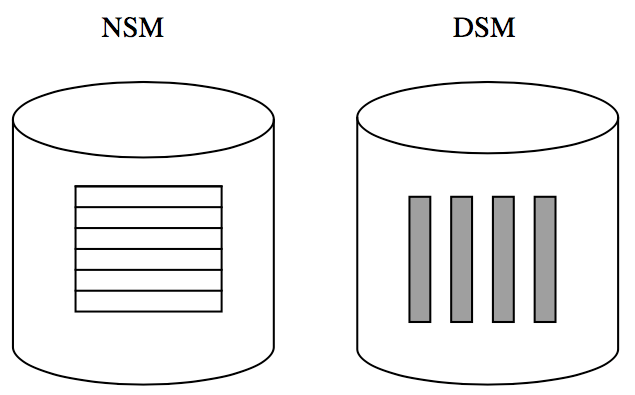
简单版 fractured mirror
前边都是在讲 DSM 和 NSM 的基础和实现。其实这篇文章主要在镜像上做文章。
因为 NSM 和 DSM 分别适用于不同场景,所以一个简单的想法是,两个镜像,一个用 NSM ,一个用 DSM。这样不同的查询负载就可以分配到不同的盘上去执行,哪个快用哪个。
这样是最简单的方式,但是有个问题,那就是负载不均衡,可能查询都是偏 NSM 场景的,那 NSM 的盘就比较忙碌了。
升级版 fractured mirror
为了解决负载均衡的问题,又提出了升级版的。下图:
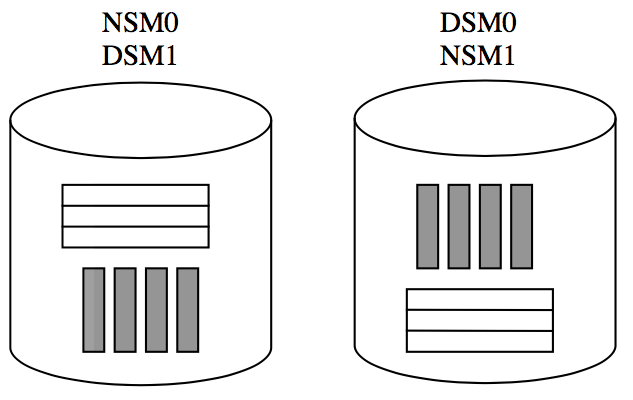
一张表,在一块盘上前一半数据用 NSM 结构存储,后一半用 DSM。在另一块盘上反过来。这是比较简单的分配策略,也可以用轮转的分配方式。
这样,一个全部偏 NSM 的查询负载,对于每一个查询来说,假设这个查询访问的数据是随机分布的,这个查询也可以被均摊到两块盘上。负载均衡也没问题了。
同步方式
原来的 Raid 1,在两个磁盘上的插入更新操作都一样,现在物理存储不同了,一个涉及1行记录10个属性的更新操作,在 NSM 上只需要一次写入就可以了,在 DSM 上就需要 10 次写入,这个极大地不同步。
解决方式是用全部驻留在内存中的 Differential file,将修改都记录在这里,定期和磁盘文件合并,保证这个文件大小适中。
删除使用 bitmap记录,查询时候需要将 Differential file 和 bitmap 一起合并。
查询计划生成
这样一个查询来了之后,可以生成两个最优计划,基于 NSM 的最优计划和基于 DSM 的最优计划,哪个快用哪个,查询优化器就变复杂了。而且需要生成两种查询计划,相当于优化了两遍(optimize-twice)。
另一种方式是自底向上的搜索查询计划,把所有可能的扫描操作符和join操作符都生成出来,然后拼出来一个最优的。通过这种方式避免 optimize-twice,而且能生成混合查询计划(既包含NSM的又包含DSM的)。
局限
先说查询计划生成,都是基于规则的,作者说是避免了优化两次,但是我觉得只是将两种查询计划生成器混合起来了,打散放到了每一小步上去,比optimize-twice并不简单,优点是能生成混合的计划。由于底层存储的不同,需要维护两套查询引擎是比较头大的。
仅有两种不同的物理存储结构,即 NSM 和 DSM,仅适用两个副本的情况。
Differential file 是个潜在的性能问题,一个盘挂了,从另一个盘恢复的时间没有度量。
感谢各位的阅读,以上就是“Fractured Mirrors知识点有哪些”的内容了,经过本文的学习后,相信大家对Fractured Mirrors知识点有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3664598/blog/4430202



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



