这篇文章主要介绍“Kafka可用架构有哪些”,在日常操作中,相信很多人在Kafka可用架构有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Kafka可用架构有哪些”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
当添加一个分区或分区增加副本的时候,都要从所有副本中选举一个新的Leader出来。
Leader如果选举?投票怎么玩?是不是所有的partition副本直接发起投票,开始竞选呢?比如用ZK实现。
利用ZK如何实现选举?ZK的什么功能可以感知到节点的变化(增加或减少)?或者说ZK为什么能实现加锁和释放锁?
用到了3个特点:watch机制;节点不允许重复写入;临时节点。
这样实现是比较简单,但也会存在一定弊端。如果分区和副本数量过多,所有的副本都直接选举的话,一旦某个节点增减,就会造成大量watch事件被触发,ZK的负载就会过重。
kafka早期的版本就是这样做的,后来换了一种实现方式。
不是所有的repalica都参与leader选举,而是由其中的一个Broker统一来指挥,这个Broker的角色就叫做Controller(控制器)。
就像Redis Sentinel的架构,执行故障转移的时候,必须要先从所有哨兵中选一个负责故障转移的节点一样。kafka 也要先从所有Broker中选出唯一的一个Controller。
所有Broker会尝试在zookeeper中创建临时节点/controller,只有一个能创建成功(先到先得)。
如果Controller挂掉了或者网络出现了问题,ZK上的临时节点会消失。其他的Brokder通过watch监听到Controller下线的消息后,开始竞选新的Controller。方法跟之前还是一样的,谁先在ZK里写入一个/cotroller节点,谁就成为新的Controller。
成为Controller节点之后,它的责任也比其他节点重了几分:
监听Broker变化
监听Topic变化
监听Partition变化
获取和管理Broker、Topic、Partition的信息
管理Partiontion的主从信息
Controller确定以后,就可以开始做分区选主的事了。下面就是找候选人了。显然,每个replica都想推荐自己,但所有的replica都有竞选资格吗?并不是,这里有几个概念。
Assigned-Replicas(AR):一个分区的所有副本。 In-Sync Replicas(ISR):上边所有副本中,跟leader数据保持一定程度同步的。 Out-Sync Replicas(OSR):跟leader同步滞后过多的副本。
AR=ISR + OSR。正常情况下OSR是空的,大家正常同步,AR=ISR。
谁能参加选举?肯定不是AR,也不是OR,而是ISR。而且这个ISR不是固定不变的,还是一个动态列表。
前面说过,如果同步延迟超30秒,就踢出ISR,进入OSR;如果赶上来了就加入ISR。
默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader。
如果ISR为空呢?群龙不能无首。在这种情况下,可以让ISR之外的副本参与选举。允许ISR之外的副本参与选举,叫做unclean leader election。
unclean.leader.election.enable=false把这个参数改成true(一般不建议开启,会造成数据丢失)。
Controller有了,候选人也有了ISR,那么根据什么规则确定leader呢?
我们首先来看分布式系统中常见的选举协议有哪些(或者说共识算法)?
ZAB(ZK)、Raft(Redis Sentinel)他们都是Paxos算法的变种,核心思想归纳起来都是:先到先得、少数服从多数。
但kafka没有用这些方法,而是用了一种自己实现的算法。
为什么呢?比如ZAB这种协议,可能会出现脑裂(节点不能互通的时候,出现多个leader)、惊群效应(大量watch事件被触发)。
在文档中有说明:
https://kafka.apachecn.org/documentation.html#design_replicatedlog
提到kafka的选举实现,最相近的是微软的PacificA算法。
在这种算法中,默认是让ISR中第一个replica变成leader。像中国皇帝传位一样,优先传给皇长子。
leader确定之后,客户端的读写只能操作leader节点。follower需要向leader同步数据。
不同的raplica的offset是不一样的,同步到底怎么同步呢?
在之后内容,需要先理解几个概念。
LEO(Log End Offset):下一条等待写入的消息的offset(最新的offset + 1)。
HW(Hign Watermark 高水位):ISR中最小的LEO。Leader会管理所有ISR中最小的LEO为HW。
consumer最多只能消费到HW之前的位置。也就是说,其他副本没有同步过去的消息,是不能被消费的。
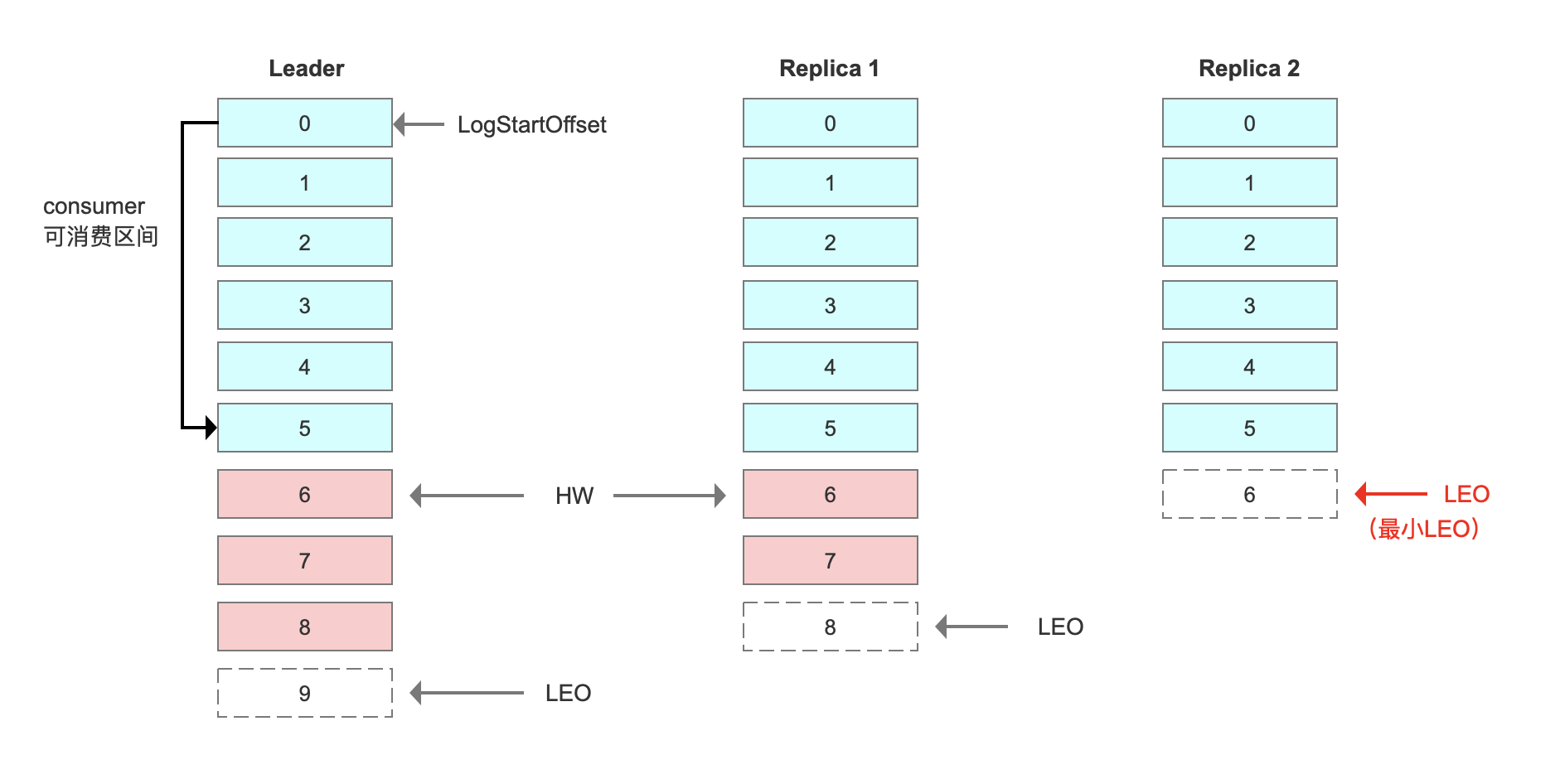
kafka为什么这么设计?
如果在同步成功之前就被消费了,consumer group 的offset会偏大,如果leader崩溃,中间会丢失消息。
接着再看消息是如何同步的。
Replica 1与Replica2各同步了1条数据,HW推进了1,变成了7,LEO因Replica2推进了1,变成了7。
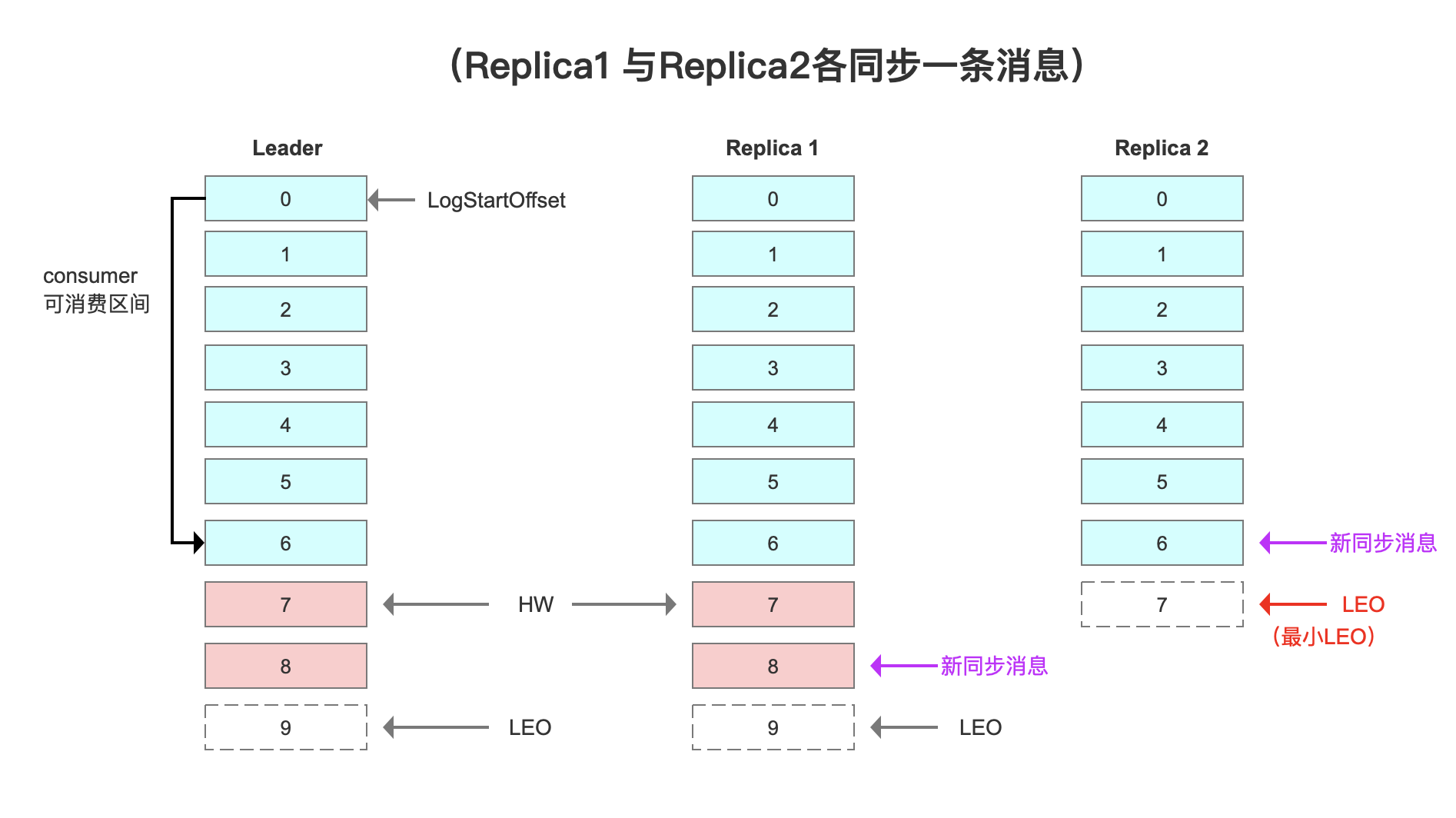
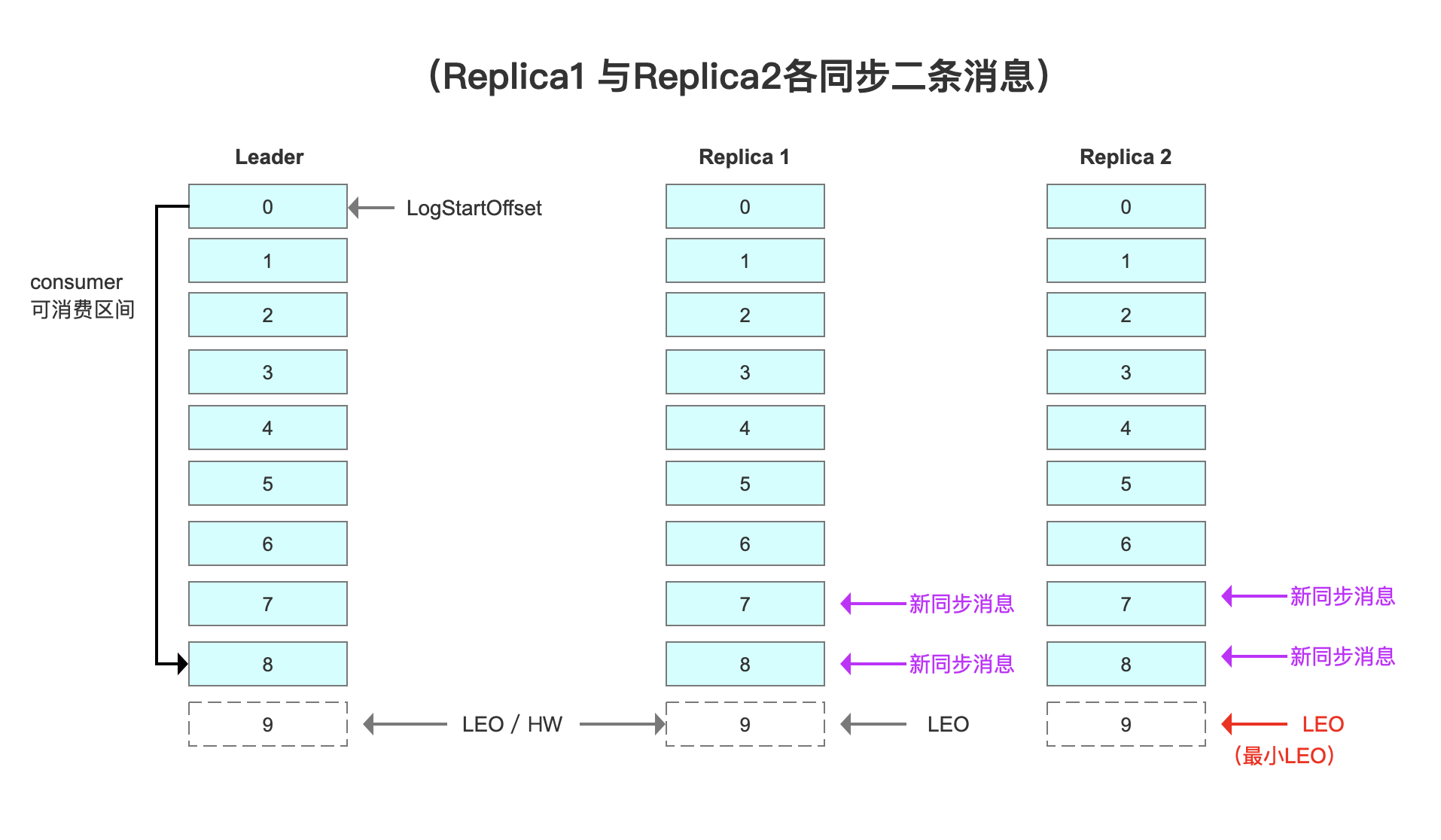
Replica 1与Replica2各同步了2条数据,HW和LEO重叠,都到了9。
在这需要了解一下,从节点如何与主节点保持同步?
follower节点会向Leader发送一个fetch请求,leader向follower发送数据后,即需要更新follower的LEO。
follower接收到数据响应后,依次写入消息并且更新LEO。
leader更新HW(ISR最小的LEO)
kafka设计了独特的ISR复制,可以在保障数据一致性情况下又可以提供高吞吐量。
首先follower发生鼓掌,会被先踢出ISR。
follower恢复之后,从哪开始同步数据呢?
假设Replica1宕机。
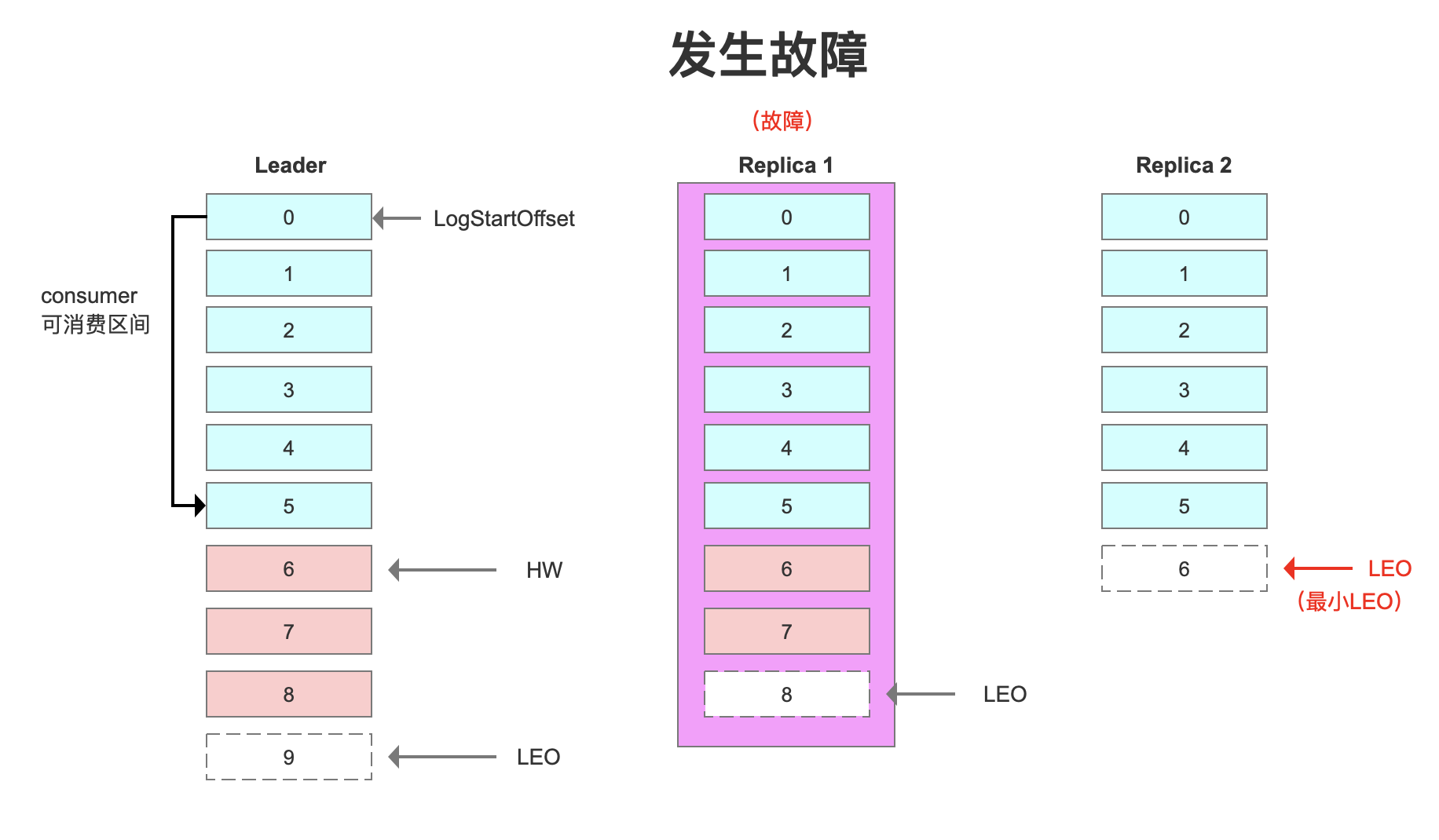
恢复以后,首先根据之前的记录的HW(6),把高于HW的消息截掉(6、7)。
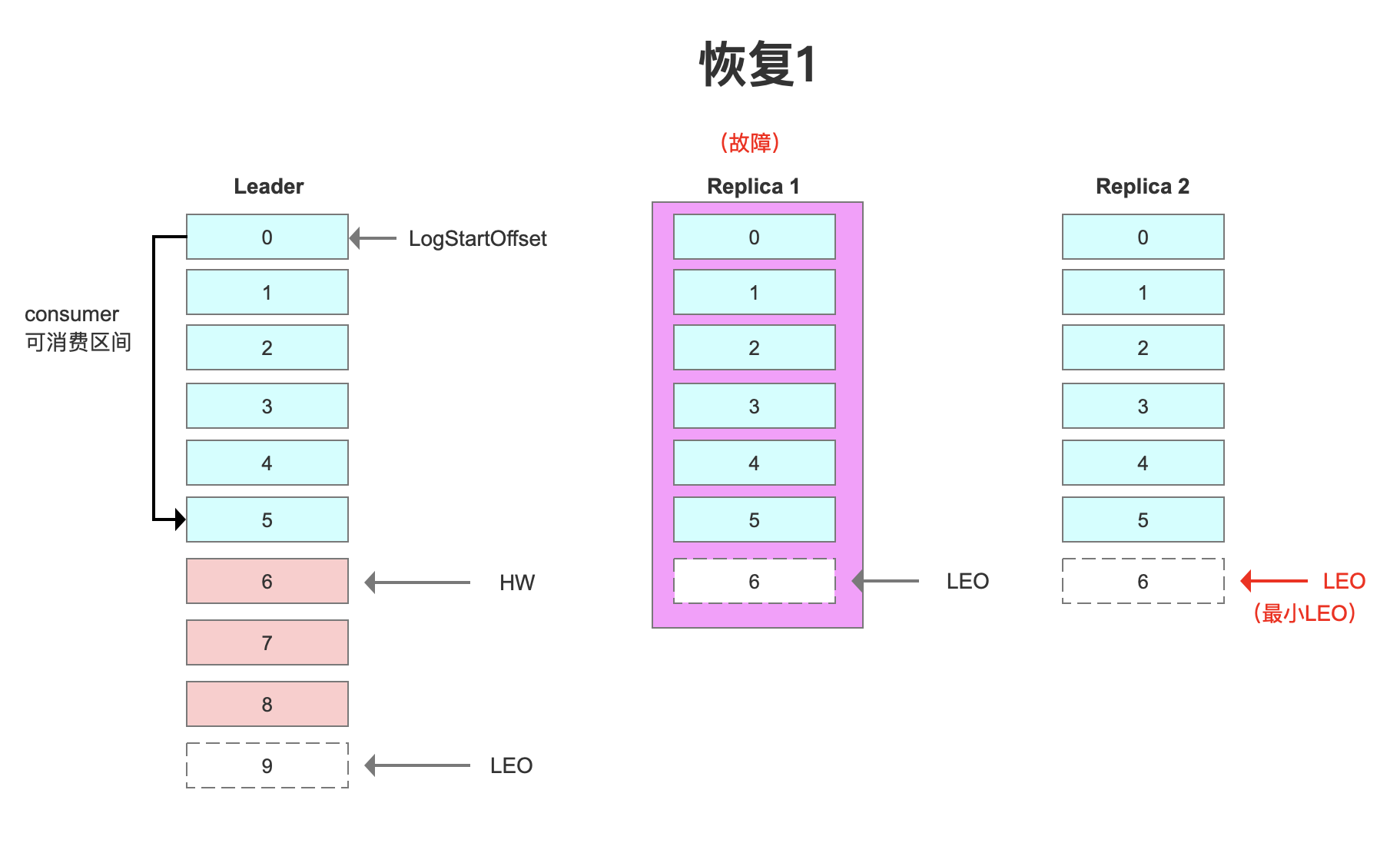
然后向Leader同步消息。追上Leader之后(30秒),重新加入ISR。

还以上图为例,如果图中Leader发生故障。
首先选一个Leader,因为Replica1优先,它将成为Leader。
为了保证数据一致,其他follower需要把高于HW的消息截掉(这里没有消息需要截取)。
然后Replica2同步数据。
此时原Leader中的数据8将丢失。
注意:这种机制只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
到此,关于“Kafka可用架构有哪些”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/1019754/blog/5001230



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



