这篇文章主要讲解了“Python怎么抓取必应搜索背景图片”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python怎么抓取必应搜索背景图片”吧!
首先,我们安装IDE,这里我选择Python最流行的PyCharm,大家可以到官网上下载:
https://www.jetbrains.com/pycharm/download/#section=windows
安装方法非常简单,直接下一步就行。
安装完成后,打开IDE,我们创建一个Python的项目
完成后,还要事先安装几个库,方便我们后面写代码使用,分别是:
request
BeautifulSoup4
lxml
安装方法很简单,我们点击编译器左上角的File->Settings弹出对话框:
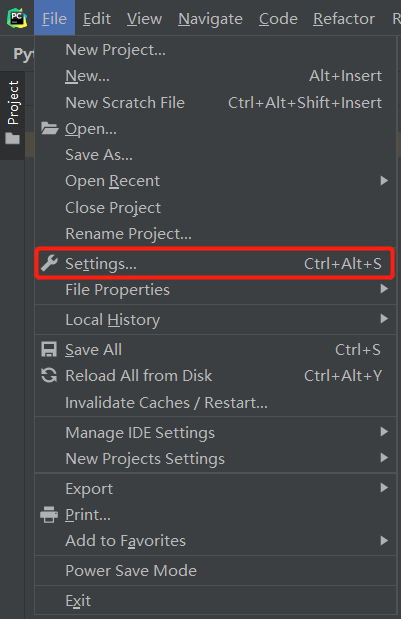
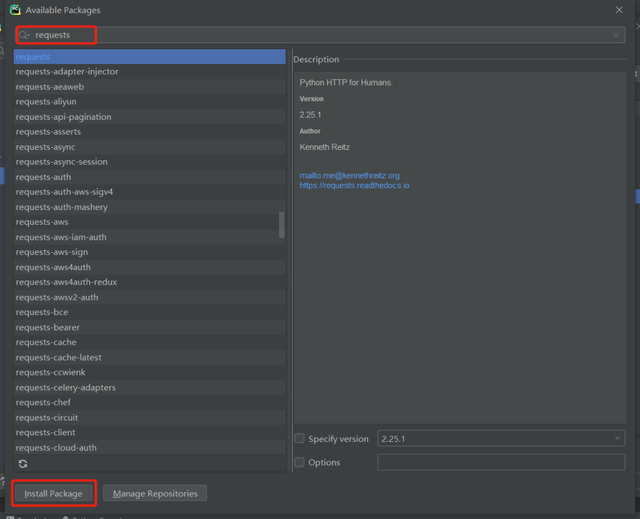
我们双击上图中的pip,在弹出的对话框里面分别搜索上面罗列的三个库名字,然后点击左下角的InstallPackage即可完成安装:
完成以后,我们开始写代码:
首先我们引入四个我们需要的包代码:
if __name__=='__main__':
for i in range(8):
url = 'https://cn.bing.com/HPImageArchive.aspx?idx={}&n=1'.format(i)
html = get_page(url)
soup = BeautifulSoup(html, 'lxml')
text = soup.find(name='url').string
img_url = 'https://cn.bing.com' + text
img_name = re.match('^/th\?id=(.*?)&', text).group(1)
download(img_url, '填你自己想保存的文件路径c:/..', img_name)然后我们定义一个get_page的函数来获取request请求得到的网页内容,不过为了伪装成浏览器访问,我们这里要更改一下User-Agent字段:
def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200: #响应状态码表示服务器对请求的响应结果。200代表服务器响应成功,403代表禁止访问,404代表页面未找到
return response.text再来定义一个下载图片的函数download,传入的参数包含图片的url路径,你自己定义的文件夹路径还有图片的名称:
def download(url, path, fname):
response = requests.get(url)
if response:
with open(os.path.join(path, fname), 'wb') as f:
f.write(response.content)
print('successful: {} .'.format(fname))
else:
print('faild: {}.'.format(fname))好了,上面两个主要的函数定义好了以后,我们再定义main函数,来不断调用他们,注意download函数的路径要填写你自己的文件夹路径。由于必应官方只保存了八张原图,所以我们就简单粗暴地只循环8次即可,代码如下:
if __name__=='__main__':
for i in range(8):
url = 'https://cn.bing.com/HPImageArchive.aspx?idx={}&n=1'.format(i)
html = get_page(url)
soup = BeautifulSoup(html, 'lxml')
text = soup.find(name='url').string
img_url = 'https://cn.bing.com' + text
img_name = re.match('^/th\?id=(.*?)&', text).group(1)
download(img_url, '填你自己想保存的文件路径c:/..', img_name)好了,上面就是完整的代码内容,我们试着运行一次
结果完全没问题,看文件夹里面的图片也保存下来了:

感谢各位的阅读,以上就是“Python怎么抓取必应搜索背景图片”的内容了,经过本文的学习后,相信大家对Python怎么抓取必应搜索背景图片这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4848094/blog/4886670



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



