Spark2.1.0жҖҺд№Ҳз”Ё
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңSpark2.1.0жҖҺд№Ҳз”ЁвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
иҝҗиЎҢspark-shell
еңЁгҖҠSpark2.1.0д№ӢиҝҗиЎҢзҺҜеўғеҮҶеӨҮгҖӢдёҖж–Үжӣҫз»Ҹз®ҖеҚ•иҝҗиЎҢдәҶspark-shellпјҢ并用дёӢеӣҫиҝӣиЎҢдәҶеұ•зӨәпјҲжӯӨеӨ„еҶҚж¬Ўеұ•зӨәжӯӨеӣҫпјүгҖӮ
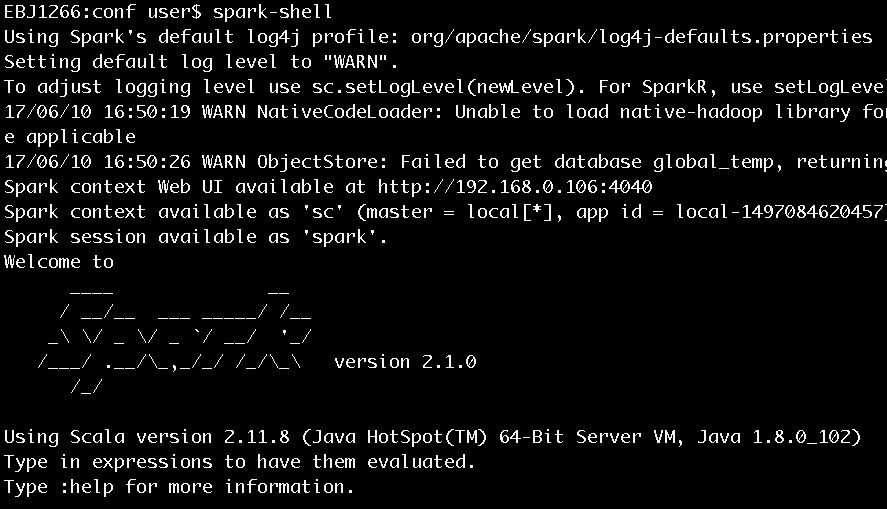
еӣҫ1 жү§иЎҢspark-shellиҝӣе…ҘScalaе‘Ҫд»ӨиЎҢ
еӣҫ1дёӯжҳҫзӨәдәҶеҫҲеӨҡдҝЎжҒҜпјҢиҝҷйҮҢиҝӣиЎҢдёҖдәӣиҜҙжҳҺпјҡ
еңЁе®үиЈ…е®ҢSpark 2.1.0еҗҺпјҢеҰӮжһңжІЎжңүжҳҺзЎ®жҢҮе®ҡlog4jзҡ„й…ҚзҪ®пјҢйӮЈд№ҲSparkдјҡдҪҝз”ЁcoreжЁЎеқ—зҡ„org/apache/spark/зӣ®еҪ•дёӢзҡ„log4j-defaults.propertiesдҪңдёәlog4jзҡ„й»ҳи®Өй…ҚзҪ®гҖӮlog4j-defaults.propertiesжҢҮе®ҡзҡ„Sparkж—Ҙеҝ—зә§еҲ«дёәWARNгҖӮз”ЁжҲ·еҸҜд»ҘеҲ°Sparkе®үиЈ…зӣ®еҪ•зҡ„confж–Ү件еӨ№дёӢд»Һlog4j.properties.templateеӨҚеҲ¶дёҖд»Ҫlog4j.propertiesж–Ү件пјҢ并еңЁе…¶дёӯеўһеҠ иҮӘе·ұжғіиҰҒзҡ„й…ҚзҪ®гҖӮ
йҷӨдәҶжҢҮе®ҡlog4j.propertiesж–Ү件еӨ–пјҢиҝҳеҸҜд»ҘеңЁspark-shellе‘Ҫд»ӨиЎҢдёӯйҖҡиҝҮsc.setLogLevel(newLevel)иҜӯеҸҘжҢҮе®ҡж—Ҙеҝ—зә§еҲ«гҖӮ
SparkContextзҡ„Web UIзҡ„ең°еқҖжҳҜпјҡhttp://192.168.0.106:4040гҖӮ192.168.0.106жҳҜ笔иҖ…е®үиЈ…Sparkзҡ„жңәеҷЁзҡ„ipең°еқҖпјҢ4040жҳҜSparkContextзҡ„Web UIзҡ„й»ҳи®Өзӣ‘еҗ¬з«ҜеҸЈгҖӮ
жҢҮе®ҡзҡ„йғЁзҪІжЁЎејҸпјҲеҚіmasterпјүдёәlocal[*]гҖӮеҪ“еүҚеә”з”ЁпјҲApplicationпјүзҡ„IDдёәlocal-1497084620457гҖӮ
еҸҜд»ҘеңЁspark-shellе‘Ҫд»ӨиЎҢйҖҡиҝҮscдҪҝз”ЁSparkContextпјҢйҖҡиҝҮsparkдҪҝз”ЁSparkSessionгҖӮscе’Ңsparkе®һйҷ…еҲҶеҲ«жҳҜSparkContextе’ҢSparkSessionеңЁSpark REPLдёӯзҡ„еҸҳйҮҸеҗҚпјҢе…·дҪ“з»ҶиҠӮе·ІеңЁгҖҠSpark2.1.0д№Ӣеү–жһҗspark-shellгҖӢдёҖж–ҮжңүиҝҮеҲҶжһҗгҖӮ
з”ұдәҺSpark coreзҡ„й»ҳи®Өж—Ҙеҝ—зә§еҲ«жҳҜWARNпјҢжүҖд»ҘзңӢеҲ°зҡ„дҝЎжҒҜдёҚжҳҜеҫҲеӨҡгҖӮзҺ°еңЁжҲ‘们е°ҶSparkе®үиЈ…зӣ®еҪ•зҡ„confж–Ү件еӨ№дёӢзҡ„log4j.properties.templateд»ҘеҰӮдёӢе‘Ҫд»ӨеӨҚеҲ¶еҮәдёҖд»Ҫпјҡ
cp log4j.properties.template log4j.properties
cp log4j.properties.template log4j.properties
并е°Ҷlog4j.propertiesдёӯзҡ„log4j.logger.org.apache.spark.repl.Main=WARNдҝ®ж”№дёәlog4j.logger.org.apache.spark.repl.Main=INFOпјҢ然еҗҺжҲ‘们еҶҚж¬ЎиҝҗиЎҢspark-shellпјҢе°Ҷжү“еҚ°еҮәжӣҙдё°еҜҢзҡ„дҝЎжҒҜпјҢеҰӮеӣҫ2жүҖзӨәгҖӮ
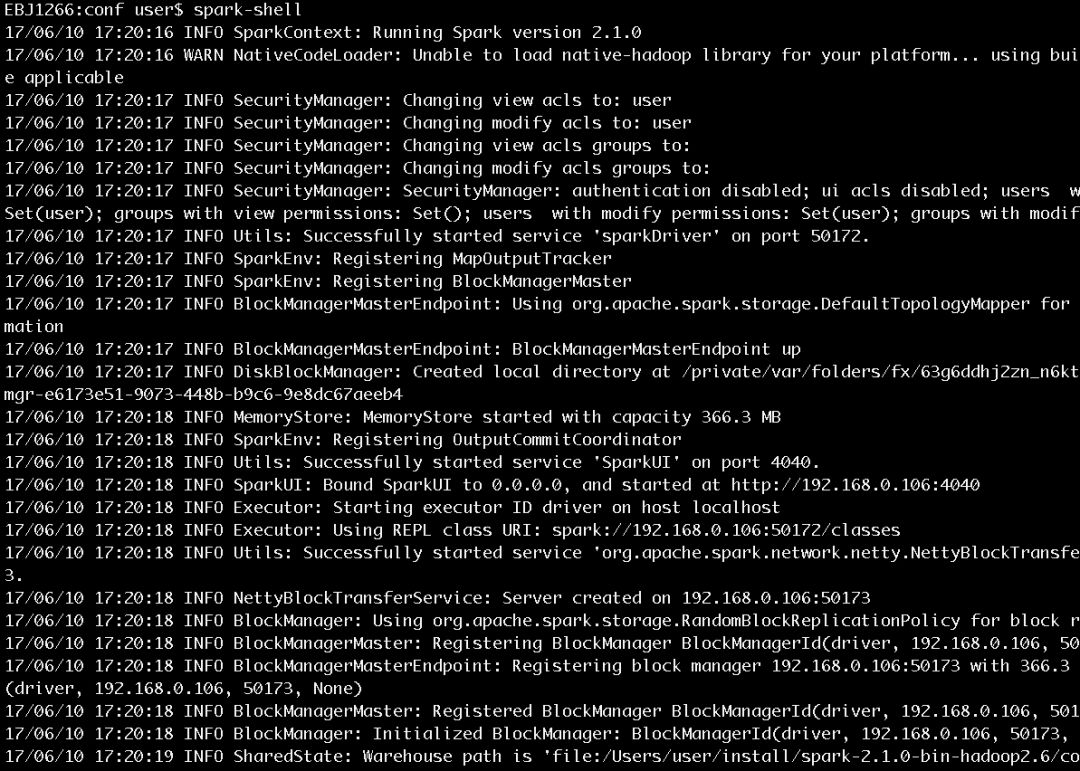
еӣҫ2 SparkеҗҜеҠЁиҝҮзЁӢжү“еҚ°зҡ„йғЁеҲҶдҝЎжҒҜ
д»Һеӣҫ2еұ•зӨәзҡ„еҗҜеҠЁж—Ҙеҝ—дёӯжҲ‘们еҸҜд»ҘзңӢеҲ°SecurityManagerгҖҒSparkEnvгҖҒBlockManagerMasterEndpointгҖҒDiskBlockManagerгҖҒMemoryStoreгҖҒSparkUIгҖҒExecutorгҖҒNettyBlockTransferServiceгҖҒBlockManagerгҖҒBlockManagerMasterзӯүдҝЎжҒҜгҖӮе®ғ们жҳҜеҒҡд»Җд№Ҳзҡ„пјҹеҲҡеҲҡжҺҘи§ҰSparkзҡ„иҜ»иҖ…еҸӘйңҖиҰҒзҹҘйҒ“иҝҷдәӣдҝЎжҒҜеҚіеҸҜпјҢе…·дҪ“еҶ…е®№е°ҶеңЁеҗҺиҫ№зҡ„еҚҡж–Үз»ҷеҮәгҖӮ
жү§иЎҢword count
иҝҷдёҖиҠӮпјҢжҲ‘们йҖҡиҝҮword countиҝҷдёӘиҖізҶҹиғҪиҜҰзҡ„дҫӢеӯҗжқҘж„ҹеҸ—дёӢSparkд»»еҠЎзҡ„жү§иЎҢиҝҮзЁӢгҖӮеҗҜеҠЁspark-shellеҗҺпјҢдјҡжү“ејҖScalaе‘Ҫд»ӨиЎҢпјҢ然еҗҺжҢүз…§д»ҘдёӢжӯҘйӘӨиҫ“е…Ҙи„ҡжң¬пјҡ
жӯҘйӘӨ1
иҫ“е…Ҙval lines =sc.textFile("../README.md", 2)пјҢд»ҘSparkе®үиЈ…зӣ®еҪ•дёӢзҡ„README.mdж–Ү件зҡ„еҶ…е®№дҪңдёәword countдҫӢеӯҗзҡ„ж•°жҚ®жәҗпјҢжү§иЎҢз»“жһңеҰӮеӣҫ3жүҖзӨәгҖӮ
еӣҫ3 жӯҘйӘӨ1жү§иЎҢз»“жһң
еӣҫ3е‘ҠиҜүжҲ‘们linesзҡ„е®һйҷ…зұ»еһӢжҳҜMapPartitionsRDDгҖӮ
жӯҘйӘӨ2
textFileж–№жі•еҜ№ж–Үжң¬ж–Ү件жҳҜйҖҗиЎҢиҜ»еҸ–зҡ„пјҢжҲ‘们йңҖиҰҒиҫ“е…Ҙval words =lines.flatMap(line => line.split(" "))пјҢе°ҶжҜҸиЎҢж–Үжң¬жҢүз…§з©әж јеҲҶйҡ”д»Ҙеҫ—еҲ°жҜҸдёӘеҚ•иҜҚпјҢжү§иЎҢз»“жһңеҰӮеӣҫ4жүҖзӨәгҖӮ

еӣҫ4 жӯҘйӘӨ2жү§иЎҢз»“жһң
еӣҫ4е‘ҠиҜүжҲ‘们linesеңЁз»ҸиҝҮflatMapж–№жі•зҡ„иҪ¬жҚўеҗҺеҫ—еҲ°зҡ„wordsзҡ„е®һйҷ…зұ»еһӢд№ҹжҳҜMapPartitionsRDDгҖӮ
жӯҘйӘӨ3
еҜ№дәҺеҫ—еҲ°зҡ„жҜҸдёӘеҚ•иҜҚпјҢйҖҡиҝҮиҫ“е…Ҙval ones = words.map(w => (w,1))пјҢе°ҶжҜҸдёӘеҚ•иҜҚзҡ„и®Ўж•°еҲқе§ӢеҢ–дёә1пјҢжү§иЎҢз»“жһңеҰӮеӣҫ5жүҖзӨәгҖӮ
еӣҫ5 жӯҘйӘӨ3жү§иЎҢз»“жһң
еӣҫ5е‘ҠиҜүжҲ‘们wordsеңЁз»ҸиҝҮmapж–№жі•зҡ„иҪ¬жҚўеҗҺеҫ—еҲ°зҡ„onesзҡ„е®һйҷ…зұ»еһӢд№ҹжҳҜMapPartitionsRDDгҖӮ
жӯҘйӘӨ4
иҫ“е…Ҙval counts = ones.reduceByKey(_ + _)пјҢеҜ№еҚ•иҜҚиҝӣиЎҢи®Ўж•°еҖјзҡ„иҒҡеҗҲпјҢжү§иЎҢз»“жһңеҰӮеӣҫ6жүҖзӨәгҖӮ

еӣҫ6 жӯҘйӘӨ4жү§иЎҢз»“жһң
еӣҫ6е‘ҠиҜүжҲ‘们onesеңЁз»ҸиҝҮreduceByKeyж–№жі•зҡ„иҪ¬жҚўеҗҺеҫ—еҲ°зҡ„countsзҡ„е®һйҷ…зұ»еһӢжҳҜShuffledRDDгҖӮ
жӯҘйӘӨ5
иҫ“е…Ҙcounts.foreach(println)пјҢе°ҶжҜҸдёӘеҚ•иҜҚзҡ„и®Ўж•°еҖјжү“еҚ°еҮәжқҘпјҢдҪңдёҡзҡ„жү§иЎҢиҝҮзЁӢеҰӮеӣҫ7е’Ңеӣҫ8жүҖзӨәгҖӮдҪңдёҡзҡ„иҫ“еҮәз»“жһңеҰӮеӣҫ9жүҖзӨәгҖӮ
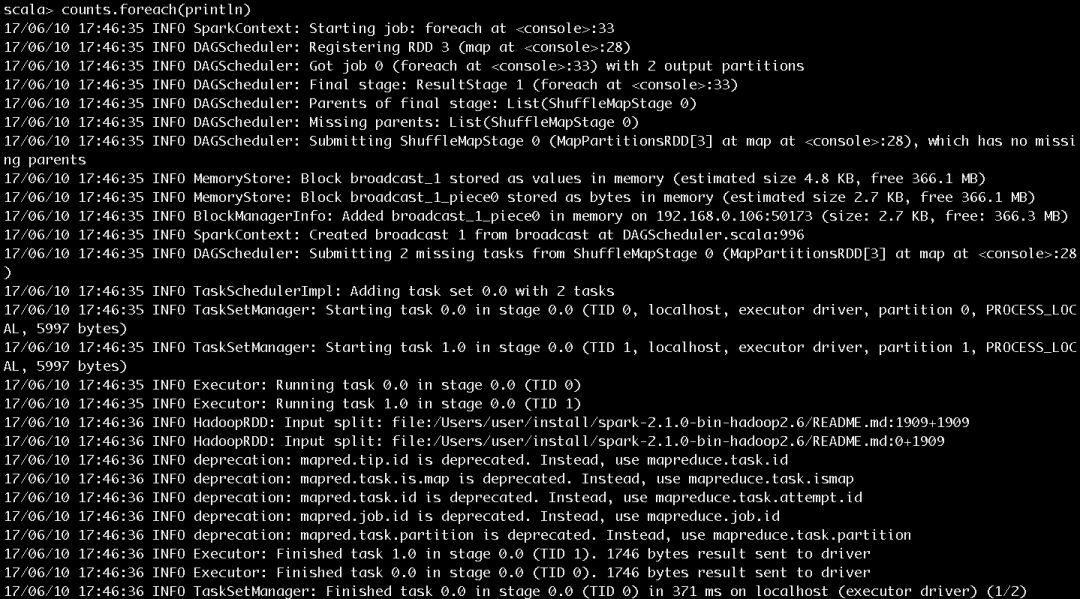
еӣҫ7 жӯҘйӘӨ5жү§иЎҢиҝҮзЁӢ第дёҖйғЁеҲҶ
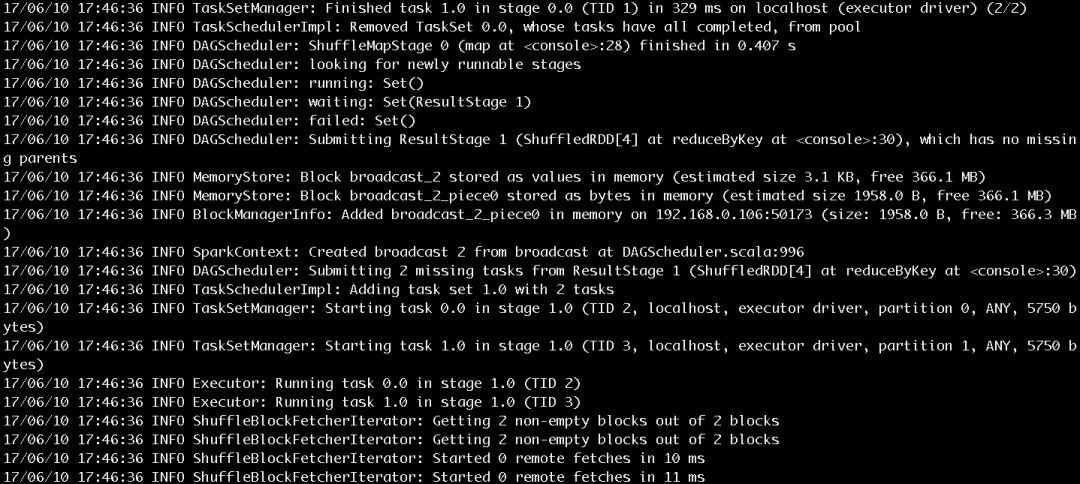
еӣҫ8 жӯҘйӘӨ5жү§иЎҢиҝҮзЁӢ第дәҢйғЁеҲҶ
еӣҫ7е’Ңеӣҫ8еұ•зӨәдәҶеҫҲеӨҡдҪңдёҡжҸҗдәӨгҖҒжү§иЎҢзҡ„дҝЎжҒҜпјҢиҝҷйҮҢжҢ‘йҖүе…ій”®зҡ„еҶ…е®№иҝӣиЎҢд»Ӣз»Қпјҡ
SparkContextдёәжҸҗдәӨзҡ„Jobз”ҹжҲҗзҡ„IDжҳҜ0гҖӮ
дёҖе…ұжңүеӣӣдёӘRDDпјҢиў«еҲ’еҲҶдёәResultStageе’ҢShuffleMapStageгҖӮShuffleMapStageзҡ„IDдёә0пјҢе°қиҜ•еҸ·дёә0гҖӮResultStageзҡ„IDдёә1пјҢе°қиҜ•еҸ·д№ҹдёә0гҖӮеңЁSparkдёӯпјҢеҰӮжһңStageжІЎжңүжү§иЎҢе®ҢжҲҗпјҢе°ұдјҡиҝӣиЎҢеӨҡж¬ЎйҮҚиҜ•гҖӮStageж— и®әжҳҜйҰ–ж¬Ўжү§иЎҢиҝҳжҳҜйҮҚиҜ•йғҪиў«и§ҶдёәжҳҜдёҖж¬ЎStageе°қиҜ•пјҲStage AttemptпјүпјҢжҜҸж¬ЎAttemptйғҪжңүдёҖдёӘе”ҜдёҖзҡ„е°қиҜ•еҸ·пјҲAttemptNumberпјүгҖӮ
з”ұдәҺJobжңүдёӨдёӘеҲҶеҢәпјҢжүҖд»ҘShuffleMapStageе’ҢResultStageйғҪжңүдёӨдёӘTaskиў«жҸҗдәӨгҖӮжҜҸдёӘTaskд№ҹдјҡжңүеӨҡж¬Ўе°қиҜ•пјҢеӣ иҖҢд№ҹжңүеұһдәҺTaskзҡ„е°қиҜ•еҸ·гҖӮд»ҺеӣҫдёӯзңӢеҮәShuffleMapStageдёӯзҡ„дёӨдёӘTaskе’ҢResultStageдёӯзҡ„дёӨдёӘTaskзҡ„е°қиҜ•еҸ·д№ҹйғҪжҳҜ0гҖӮ
HadoopRDDеҲҷз”ЁдәҺиҜ»еҸ–ж–Ү件еҶ…е®№гҖӮ
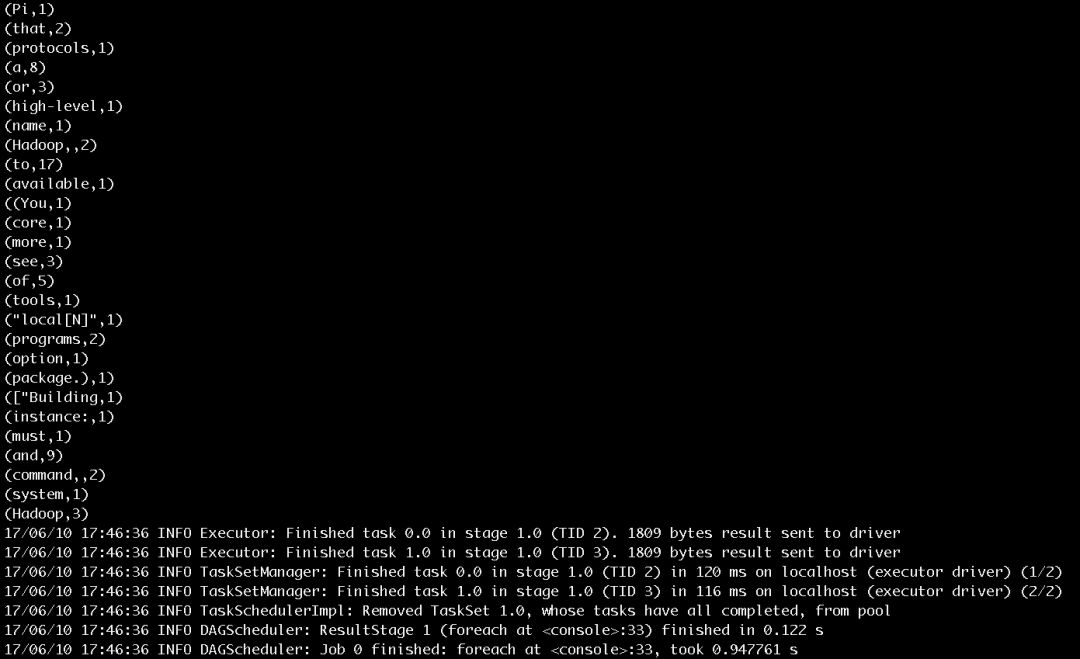
еӣҫ9 жӯҘйӘӨ5иҫ“еҮәз»“жһң
еӣҫ9еұ•зӨәдәҶеҚ•иҜҚи®Ўж•°зҡ„иҫ“еҮәз»“жһңе’ҢжңҖеҗҺжү“еҚ°зҡ„д»»еҠЎз»“жқҹзҡ„ж—Ҙеҝ—дҝЎжҒҜгҖӮ
вҖңSpark2.1.0жҖҺд№Ҳз”ЁвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





