这篇文章主要介绍了MySQL InnoDB的select和update形成表级锁实例分析的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇MySQL InnoDB的select和update形成表级锁实例分析文章都会有所收获,下面我们一起来看看吧。
InnoDB 的细粒度行锁以及事务支持一度是 MySQL 最吸引人的特性之二。但是在多种情况下,InnoDB 的行级锁会变成表级锁。使用不当,给我们带来的危害极大!
如果 InnoDB 的查询没有命中索引,也将退化为表锁。InnoDB 的细粒度锁,是实现在索引记录上的。
InnoDB 的索引有两类。聚集索引(Clustered Index)与普通索引(Secondary Index)。
InnoDB 的每一个表都会有聚集索引。如果你没手动创建,InnoDB 也会默认的帮你创建聚集索引。
聚集索引以下面三种形式存在:
如果表定义了 PK,则 PK 就是聚集索引;
如果表没有定义 PK,则第一个非空 unique 列是聚集索引;
否则,InnoDB 会创建一个隐藏的 row-id 作为聚集索引。
我们知道索引的结构是 B+ 树,这里不展开 B+ 树的细节,先说几个结论:
在索引结构中,非叶子节点存储 key,叶子节点存储 value;
聚集索引,叶子节点存储行记录(row);
普通索引,叶子节点存储了 PK 的值。
由于上面我们说过的 InnoDB 的每一个表都会有聚集索引,索引结构中叶子节点存储 value,而聚集索引的叶子节点还会存储行记录(row)。所以,InnoDB 索引和记录是存储在一起的,而 MyISAM 的索引和记录是分开存储的。
所以,InnoDB 的普通索引,实际上会扫描两遍:第一遍,由普通索引找到 PK;第二遍,由PK找到行记录;
关于索引结构,我这里不展开去讲,后面我查询更多资料后,将给大家详细的讲讲 InnoDB/MyISAM 的索引结构,如果大家感兴趣的话。
下面我们通过一个例子来说明。假设存在一个下面结构的 InnoDB 表:
1 |
|
表中有四条记录:
1 2 3 4 |
|
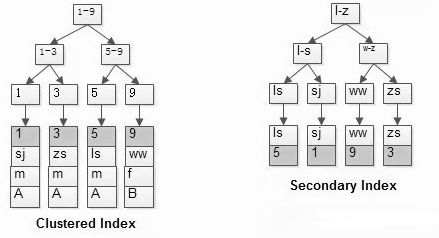
从上图中可以看到:
第一幅图,id PK的聚集索引,叶子存储了所有的行记录;
第二幅图,name上的普通索引,叶子存储了PK的值;
当执行查询 select * from t where name=’shenjian’; 语句时,会发生下面的过程:
会先在 name 普通索引上查询到PK=1;
再在聚集索引衫查询到(1,shenjian, m, A)的行记录;
再回到文章开头部分,我们说过“InnoDB 的查询没有命中索引,也将退化为表锁。InnoDB 的细粒度锁,是实现在索引记录上的。”由于这里的 name 并没有创建索引,所以它会变成表锁。至于时读锁和写锁,它们都是锁。InnoDB 的锁,与索引类型,事务的隔离级别相关。
关于“MySQL InnoDB的select和update形成表级锁实例分析”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“MySQL InnoDB的select和update形成表级锁实例分析”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3677838/blog/4828833



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



