这篇文章主要介绍如何实现基于Impala平台打造交互查询系统,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
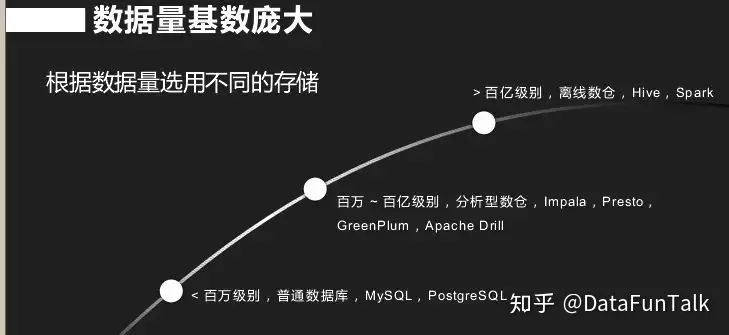
交互查询特点第一个就是数据量庞大,第二个关系模式相对比较复杂,依据你的设计不同,关系模式有很多种类。还有一个就是响应时间要求较高,对于对于绝大数要求查询返回时间在10秒以下;依据数据量的不同选择不同的存储,对于百万级数据采用MySQL,PostgreSQL,对于百万-百亿级别,传统数据库无法满足,采用分析性数据仓库实现Impala,Presto, Green Plum, Apache Drill;百亿级别以上很难做大数据分析,采用离线数据仓库,采用hive,spark。

对于BE系统很多实用宽表做,因为其维度很多,一个用户经过慢慢信息积累可能会有几百个维度,假如对一个50个维度进行过滤,利用宽表结合一些特殊数据结构如倒排就会很容易实现。Elastic Search, Solr是搜索引擎,Click House是俄罗斯开发的一个性能比较好的系统,但是join支持有限, Druid在广告平台用的比较多。还有一种是组合模型,如Elastic Search, Solr用的比较多,典型的有Green Plum,Presto,Impala。

接下来讲一下有哪些因素决定我们选择一个平台,首先是本身项目熟悉度,如果项目负责人对这个平台熟悉就会选择这个平台。如果对项目不熟悉,就会选择大厂背书,用大公司一样的应用。如果前两者都没有,那么就从性能和优缺点上来评价是否适应这个系统。
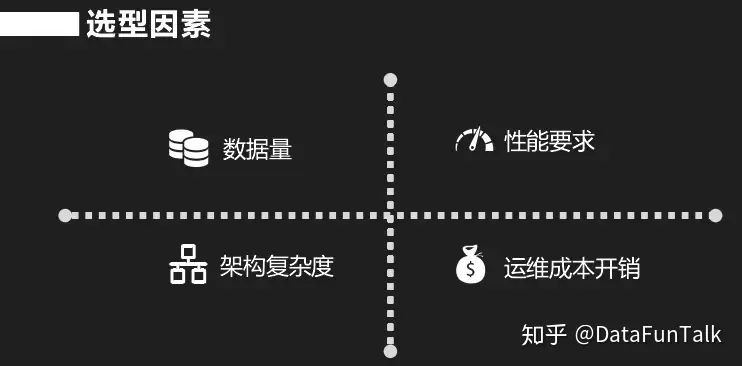
重点讲解第三点,首先是数据量,依据系统数据量容量,平台至少要达到我的最低性能指标。还有一个就是架构复杂度,一个系统最终要上线,要保证CLA,如果架构复杂,出问题就多;因此选择架构相对简单一点的。最后一个就是运维和开销,运维的成本很高,因此不可能去经常做改动;如果要改一个东西你需要熟悉一下这个平台,那么就会影响你的选型了。

接下来讲一下我们选型是如何做的,主要是考虑Impala、Presto、Greenplum。首先考虑的是数据源,我们的数据很多都是在HDFS上,所以Greenplum肯定是不适合,因为它整个是封闭的,是自己做的存储架构。社区环境、架构这三者都差不多,从架构上来说差异不大。性能方面Impala比Presto稍微好点。还有其他特性,如编程语言,C++运行比Java要快一点,因此更趋于选择C++写的平台。最后选择了Impala。

这三个都是MPP架构,Impala整个执行节点都是无状态的,因此down掉一个节点,再启动没有问题。Impala兼容hive存储,还有一些点如Apache顶级项目、成熟社区、多种数据源格式兼容、高效的查询性能都是我们考虑特有的选型因素。
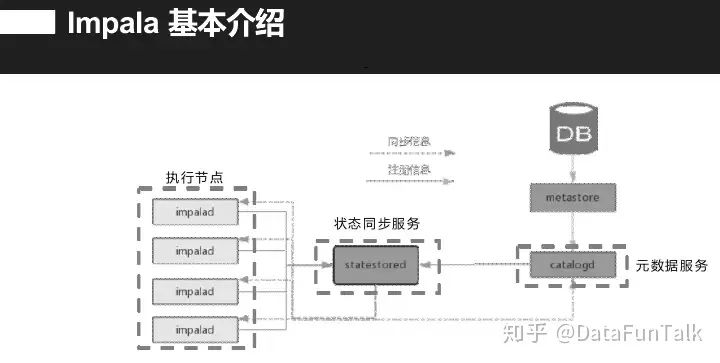
接下来讲一下Impala架构,其兼容多种数据源就是metastore直接对接各种DB,利用catalogd提供元数据服务。可以直接连DB也可以通过catalogd,一般是利用hive里的metastore获取数据。Impala高效的原因是其将原始数据缓存下来,catalogd启动会浏览缓存获取数据。它有一个statestored服务,是一个发布订阅服务,所有状态以及轮转都是在statestored服务中进行。左边是impala的执行节点,所有查询都是发完这些节点,节点执行后会下发到所有相关节点上去,整个impala是无状态的,所有的连接者都像是一个协调者。
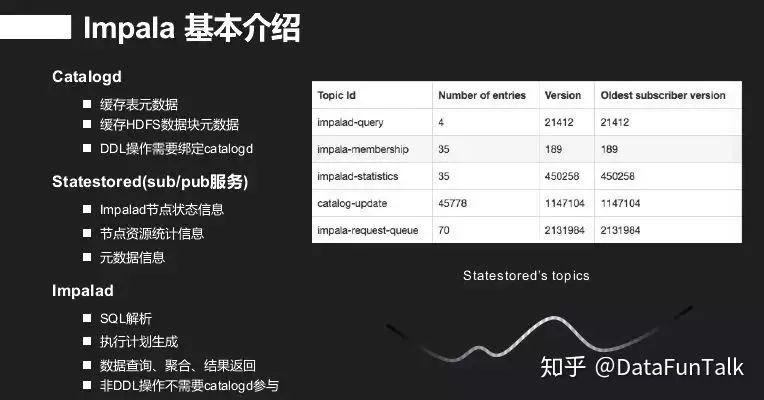
Catalogd是元数据服务,其主要的问题是你做select时,impala也会缓存一部分数据,它不会进入catalogd服务,但是做DDL操作会应用catalogd服务。Statestored(sub/pub )有很多topic,所有的impala节点去订阅这些topic上的相关消息,Statestored实际是在很多topic上做了一个消息订阅。Impala节点有SQL解析、执行计划生成,还有是数据查询、聚合、结果返回。
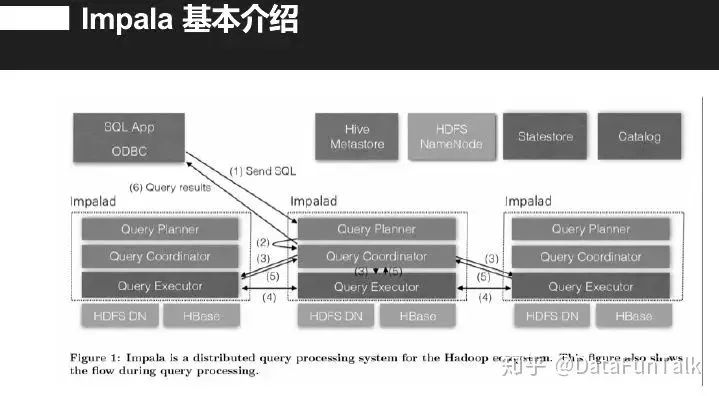
上图是一个查询进来,各个节点是一个怎么样的协调方式。如一个查询进入这个节点,这个节点就是Query Planner,负责生成执行计划,将计划向周边节点传输,最后将结果返回Query Planner,如果有聚合,先聚合然后返回总的Query Planner上,然后进行相关聚合将结果返回。
Impala性能优势有元数据缓存,而且impala会缓存HDFS上相应表数据在blog里的信息,因此查询时会有一个本地读,判断元数据是否在本地,通过本地转读方式,log才能连接数据。第二点并行计算,Query Planner生成执行计划将其发往周边节点,然后汇聚。第三个利用codegen技术,有些依据执行环境生成执行代码,会对性能提升很大。再一个就是很多算子下推,如果追求高性能不许实现算子下推,将存储层与计算层交互变得更小,在底层过滤而不是在计算层,这样对平台整体性能提升较大。
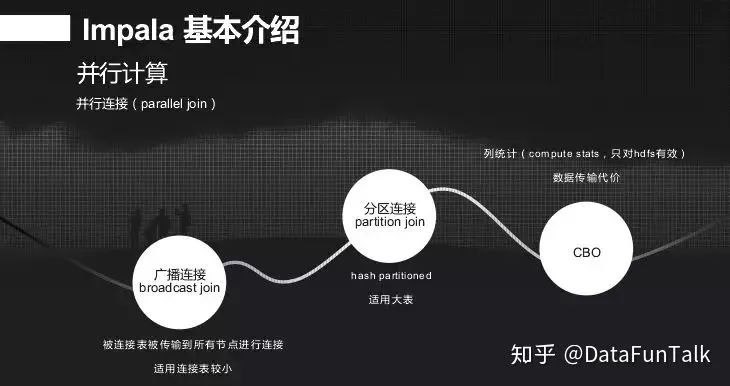
broadcast join在大表关联时,将小表缓存到所有节点上,然后返回数据做聚合。partition join应对两张表都是大数据表,如一个事件表积累上百亿数据,而用户有五亿,那么就不能通过broadcast join绑定到所有节点上,因此在每个节点做一些分区join操作然后在到上面去。还有一个CBO,目前来说还不是很准,有时会偏差很大。有并行计算就有并行聚合,数据生成前提前聚合,依据group by 的column 进行聚合的合并操作。

接下来介绍下impala支持哪些存储引擎,常用的有hdfs,还有kudu,为了解决HDFS和HBASE进行交互而产生的一个产品。Hbase主要是一个kb查询,但是如果有大量扫描时性能很差,而大批量扫描是HDFS的强项,但是做不了kb查询。Alluxio是一个文件记录换缓存,底层也可以对接HDFS,支持多级缓存。我们做Alluxio主要是应对热力数据,以前使用缓存解决这个问题。
如果要使用impala平台如何实现对接呢,首先它有整个授权和认证机制。认证可以对接kerberos、LDAP、Audit log,只有身份认证了才能访问系统。授权通过Apache Sentry,粒度有:database、table、column,权限:select、insert、all配置开启(authorization_policy_provider_class=org.apache.sentry.provider.file.Local G roup R esource A uthorization P rovider)。这些是你如果要上线必须要做的一些事情。

对于一个平台有很多用户在上面做一些任务,需要进行资源管理。目前采用Admission Control机制,他能保证每一个impala节点上都有直接用户配置,每一个队列可以设置资源总量,也可以设置每一个SQL的资源大小。这个配置是针对impala节点,如给一个用户设置300G,有100个节点,那么每个节点只分配2-3G,超过这个限额也是要被禁止的。资源隔离既要考虑总的也要考虑单独的,Impala节点是通过statestored的impalad-statistics topic项同步信息,由于statestored通过心跳与impalad 保持通信,这个资源信息实际上有些延迟;目前配置中,只有内存项有实际效果,vcore没有实现隔离,队列名配置如果与认证用户名相同,该用户提交的SQL自动分配到该队列。

Impala有个web端,虽然简单但很有用,整个问题解决、定位经常用到。每一个组件都会提供一个web端,分配相应的端口,基本信息有集群节点、Catalog信息、内存信息、Query信息。Web端能使此案节点内存消耗查看(每个对垒内存消耗、每个查询在该点内存消耗),该节点查询分析(查询分析、SQL诊断、异常查询终止),还有就是Metrics信息查看。上图是我们配的一些队列,每一个队列消耗资源情况等。用impala做join分析,将每个SQL中执行计划都具体化了,界面上的标签如query、summary、memory等都可以做SQL分析。

讲了impala的优点、特点、如何用,但是基于开源平台,也是有很多缺陷。第一个Catalogd&statestored服务单点,但是好在对查询不受影响,如果Catalogd挂掉,元数据更新就不会同步到整个impala节点。Statestored挂掉,对于更新也不会同步,只会保挂掉之前的信息。第二个就是web信息不持久,显示的信息都是存在历史信息中,如果impala重启后信息就会没有了。资源隔离不精准,还有就是底层存储不能区分用户,还有就是负载均衡,每一个impala都可以对接SQL,但是有100个impala如何接入不好解决,因此对impala实现haproxy。还有与hive元数据同步需要手动操作,impala是缓存元数据,通过HDFS操作是不会感知这种操作的。

有缺陷就有改进,首先基于ZK的load balance,因为impala是和hive绑在一起,hive的server是基于ZK,将你需要访问的impala的uri写入一个维度中去,hive原生就是基于ZK的多维节点访问。第二个就是管理服务器,因为impala页面的信息不会保存,利用管理服务器保存这些东西,排查时在管理服务器上查,不会因为你impala节点多而信息不保存。细粒度权限&代理,通过impala访问HDFS实现底层权限控制。Json格式,这个就是偏应用需求。兼容ranger权限管理,因为我们整个项目权限管理是基于ranger的。批量元数据刷新,也是实际应用中出现的问题,有时会一次改好几十个表,如果每次都刷新会很麻烦。元数据同步,改造hive和impala,每次hive改变,将改变写入中间层,impala去获取中间层实现同步。元数据过滤,数据量很庞大时,其实交互式查询很大一部分表是用不到的,而impala只对某一部分有需求,因此通过正则表达式过滤掉不必要的数据。对接ElasticSearch查询,将ES涉及的算子下推过去,如多维过滤查询,根据倒排属性比hash将数据聚合要快。
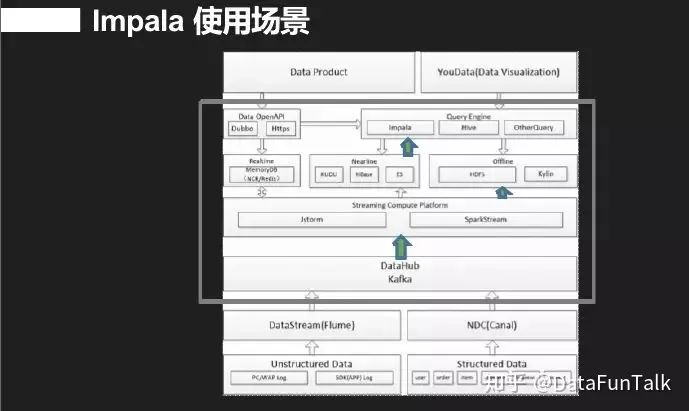
Impala应用场景介绍,上图是一个部门大数据平台架构,从kafka数据到HDFS,结构化到半结构化这是数据的接入。经过数据清洗,再接入到上层,上层应用了ES存储,最上面就直接用impala来进行查询,这基本就是分析系统的框架。
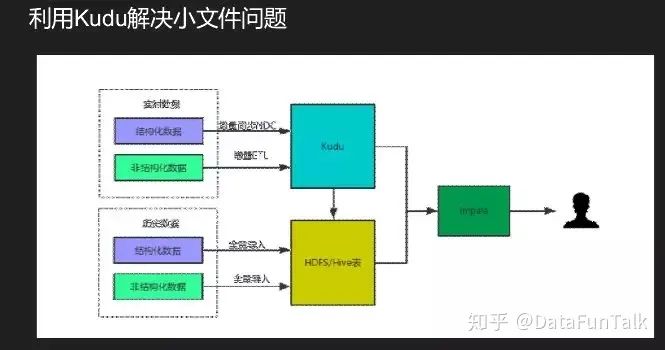
上面是我们的一个BI产品,叫有数。底层也对接了impala平台,这是一个数据分析报表平台,将图表与地图上的数据进行对接。将结构化数据或非结构化数据直接写入hive,然后通过impala去感知,实现元数据同步,用户直接通过impala去查询。需要考虑问题有元数据同步问题,ETL写入数据impala无感知,依赖元数据同步;数据实时性问题,避免大量小文件导致NN不稳定,每次写文件的batch不能太小。还有一个方案是利用kudu解决小文件问题,将实时数据往kudu里写,将kudu和hdfs实现联查,在impala上既能看到kudu的表也能看到hdfs的表。
以上是“如何实现基于Impala平台打造交互查询系统”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





