这篇文章主要讲解了“什么是SafePoint与Stop The World”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“什么是SafePoint与Stop The World”吧!
在分析线上 JVM 性能问题的时候,我们可能会碰到下面这些场景:
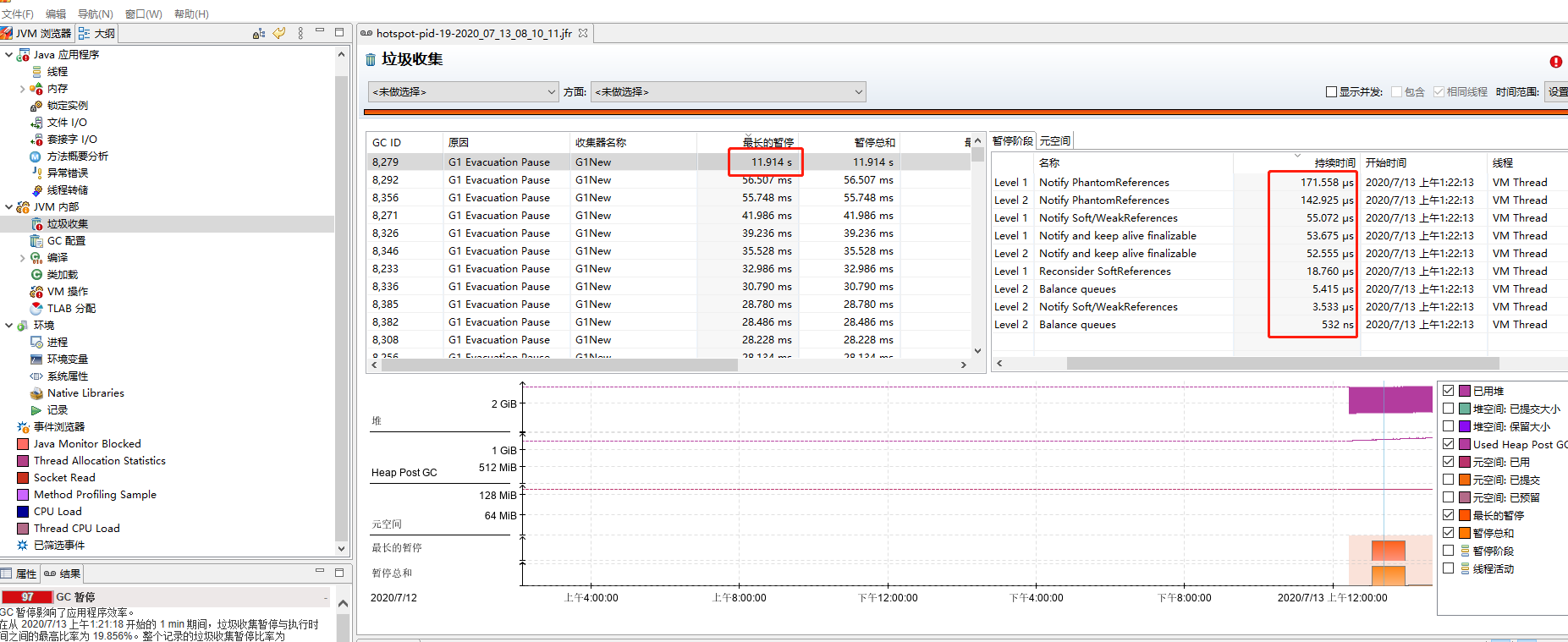
1.GC 本身没有花多长时间,但是 JVM 暂停了很久,例如下面:
2.JVM 没有 GC,但是程序暂停了很久,而且这种情况时不时就出现。
这些问题一般和 SafePoint 还有 Stop the World 有关。
我们先来设想下如下场景:
当需要 GC 时,需要知道哪些对象还被使用,或者已经不被使用可以回收了,这样就需要每个线程的对象使用情况。
对于偏向锁(Biased Lock),在高并发时想要解除偏置,需要线程状态还有获取锁的线程的精确信息。
对方法进行即时编译优化(OSR栈上替换),或者反优化(bailout栈上反优化),这需要线程究竟运行到方法的哪里的信息。
对于这些操作,都需要线程的各种信息,例如寄存器中到底有啥,堆使用信息以及栈方法代码信息等等等等,并且做这些操作的时候,线程需要暂停,等到这些操作完成,否则会有并发问题。这就需要 SafePoint。
Safepoint 可以理解成是在代码执行过程中的一些特殊位置,当线程执行到这些位置的时候,线程可以暂停。在 SafePoint 保存了其他位置没有的一些当前线程的运行信息,供其他线程读取。这些信息包括:线程上下文的任何信息,例如对象或者非对象的内部指针等等。我们一般这么理解 SafePoint,就是线程只有运行到了 SafePoint 的位置,他的一切状态信息,才是确定的,也只有这个时候,才知道这个线程用了哪些内存,没有用哪些;并且,只有线程处于 SafePoint 位置,这时候对 JVM 的堆栈信息进行修改,例如回收某一部分不用的内存,线程才会感知到,之后继续运行,每个线程都有一份自己的内存使用快照,这时候其他线程对于内存使用的修改,线程就不知道了,只有再进行到 SafePoint 的时候,才会感知。
所以,GC 一定需要所有线程同时进入 SafePoint,并停留在那里,等待 GC 处理完内存,再让所有线程继续执。像这种**所有线程进入 SafePoint **等待的情况,就是 Stop the world(此时,突然想起承太郎的:食堂泼辣酱,the world!!!)。
在 SafePoint 位置保存了线程上下文中的任何东西,包括对象,指向对象或非对象的内部指针,在线程处于 SafePoint 的时候,对这些信息进行修改,线程才能感知到。所以,只有线程处于 SafePoint 的时候,才能针对线程使用的内存进行 GC,以及改变正在执行的代码,例如 OSR (On Stack Replacement,栈上替换现有代码为JIT优化过的代码)或者 Bailout(栈上替换JIT过优化代码为去优化的代码)。并且,还有一个重要的 Java 线程特性也是基于 SafePoint 实现的,那就是 Thread.interrupt(),线程只有运行到 SafePoint 才知道是否 interrupted。
为啥需要 Stop The World,有时候我们需要全局所有线程进入 SafePoint 这样才能统计出那些内存还可以回收用于 GC,,以及回收不再使用的代码清理 CodeCache,以及执行某些 Java instrument 命令或者 JDK 工具,例如 jstack 打印堆栈就需要 Stop the world 获取当前所有线程快照。
可以这么理解,SafePoint 可以插入到代码的某些位置,每个线程运行到 SafePoint 代码时,主动去检查是否需要进入 SafePoint,这个主动检查的过程,被称为 Polling
理论上,可以在每条 Java 编译后的字节码的边界,都放一个检查 Safepoint 的机器命令。线程执行到这里的时候,会执行 Polling 询问 JVM 是否需要进入 SafePoint,这个询问是会有性能损耗的,所以 JIT 会优化尽量减少 SafePoint。
经过 JIT 编译优化的代码,会在所有方法的返回之前,以及所有非counted loop的循环(无界循环)回跳之前放置一个 SafePoint,为了防止发生 GC 需要 Stop the world 时,该线程一直不能暂停,但是对于明确有界循环,为了减少 SafePoint,是不会在回跳之前放置一个 SafePoint,也就是:
for (int i = 0; i < 100000000; i++) {
...
}里面是不会放置 SafePoint 的,这也导致了后面会提到的一些性能优化的问题。注意,仅针对 int 有界循环,例如里面的 int i 换成 long i 就还是会有 SafePoint;
SafePoint 实现相关源代码: safepoint.cpp
可以看出,针对 SafePoint,线程有 5 种情况;假设现在有一个操作触发了某个 VM 线程所有线程需要进入 SafePoint(例如现在需要 GC),如果其他线程现在:
运行字节码:运行字节码时,解释器会看线程是否被标记为 poll armed,如果是,VM 线程调用 SafepointSynchronize::block(JavaThread *thread)进行 block。
运行 native 代码:当运行 native 代码时,VM 线程略过这个线程,但是给这个线程设置 poll armed,让它在执行完 native 代码之后,它会检查是否 poll armed,如果还需要停在 SafePoint,则直接 block。
运行 JIT 编译好的代码:由于运行的是编译好的机器码,直接查看本地 local polling page 是否为脏,如果为脏则需要 block。这个特性是在 Java 10 引入的 JEP 312: Thread-Local Handshakes 之后,才是只用检查本地 local polling page 是否为脏就可以了。
处于 BLOCK 状态:在需要所有线程需要进入 SafePoint 的操作完成之前,不许离开 BLOCK 状态
处于线程切换状态或者处于 VM 运行状态:会一直轮询线程状态直到线程处于阻塞状态(线程肯定会变成上面说的那四种状态,变成哪个都会 block 住)。
定时进入 SafePoint:每经过-XX:GuaranteedSafepointInterval 配置的时间,都会让所有线程进入 Safepoint,一旦所有线程都进入,立刻从 Safepoint 恢复。这个定时主要是为了一些没必要立刻 Stop the world 的任务执行,可以设置-XX:GuaranteedSafepointInterval=0关闭这个定时,我推荐是关闭。
由于 jstack,jmap 和 jstat 等命令,也就是 Signal Dispatcher 线程要处理的大部分命令,都会导致 Stop the world:这种命令都需要采集堆栈信息,所以需要所有线程进入 Safepoint 并暂停。
偏向锁取消(这个不一定会引发整体的 Stop the world,参考JEP 312: Thread-Local Handshakes):Java 认为,锁大部分情况是没有竞争的(某个同步块大多数情况都不会出现多线程同时竞争锁),所以可以通过偏向来提高性能。即在无竞争时,之前获得锁的线程再次获得锁时,会判断是否偏向锁指向我,那么该线程将不用再次获得锁,直接就可以进入同步块。但是高并发的情况下,偏向锁会经常失效,导致需要取消偏向锁,取消偏向锁的时候,需要 Stop the world,因为要获取每个线程使用锁的状态以及运行状态。
Java Instrument 导致的 Agent 加载以及类的重定义:由于涉及到类重定义,需要修改栈上和这个类相关的信息,所以需要 Stop the world
Java Code Cache相关:当发生 JIT 编译优化或者去优化,需要 OSR 或者 Bailout 或者清理代码缓存的时候,由于需要读取线程执行的方法以及改变线程执行的方法,所以需要 Stop the world
GC:这个由于需要每个线程的对象使用信息,以及回收一些对象,释放某些堆内存或者直接内存,所以需要 Stop the world
JFR 的一些事件:如果开启了 JFR 的 OldObject 采集,这个是定时采集一些存活时间比较久的对象,所以需要 Stop the world。同时,JFR 在 dump 的时候,由于每个线程都有一个 JFR 事件的 buffer,需要将 buffer 中的事件采集出来,所以需要 Stop the world。
其他的事件,不经常遇到,可以参考源码 vmOperations.hpp
#define VM_OPS_DO(template) \
template(None) \
template(Cleanup) \
template(ThreadDump) \
template(PrintThreads) \
template(FindDeadlocks) \
template(ClearICs) \
template(ForceSafepoint) \
template(ForceAsyncSafepoint) \
template(DeoptimizeFrame) \
template(DeoptimizeAll) \
template(ZombieAll) \
template(Verify) \
template(PrintJNI) \
template(HeapDumper) \
template(DeoptimizeTheWorld) \
template(CollectForMetadataAllocation) \
template(GC_HeapInspection) \
template(GenCollectFull) \
template(GenCollectFullConcurrent) \
template(GenCollectForAllocation) \
template(ParallelGCFailedAllocation) \
template(ParallelGCSystemGC) \
template(G1CollectForAllocation) \
template(G1CollectFull) \
template(G1Concurrent) \
template(G1TryInitiateConcMark) \
template(ZMarkStart) \
template(ZMarkEnd) \
template(ZRelocateStart) \
template(ZVerify) \
template(HandshakeOneThread) \
template(HandshakeAllThreads) \
template(HandshakeFallback) \
template(EnableBiasedLocking) \
template(BulkRevokeBias) \
template(PopulateDumpSharedSpace) \
template(JNIFunctionTableCopier) \
template(RedefineClasses) \
template(UpdateForPopTopFrame) \
template(SetFramePop) \
template(GetObjectMonitorUsage) \
template(GetAllStackTraces) \
template(GetThreadListStackTraces) \
template(GetFrameCount) \
template(GetFrameLocation) \
template(ChangeBreakpoints) \
template(GetOrSetLocal) \
template(GetCurrentLocation) \
template(ChangeSingleStep) \
template(HeapWalkOperation) \
template(HeapIterateOperation) \
template(ReportJavaOutOfMemory) \
template(JFRCheckpoint) \
template(ShenandoahFullGC) \
template(ShenandoahInitMark) \
template(ShenandoahFinalMarkStartEvac) \
template(ShenandoahInitUpdateRefs) \
template(ShenandoahFinalUpdateRefs) \
template(ShenandoahDegeneratedGC) \
template(Exit) \
template(LinuxDllLoad) \
template(RotateGCLog) \
template(WhiteBoxOperation) \
template(JVMCIResizeCounters) \
template(ClassLoaderStatsOperation) \
template(ClassLoaderHierarchyOperation) \
template(DumpHashtable) \
template(DumpTouchedMethods) \
template(PrintCompileQueue) \
template(PrintClassHierarchy) \
template(ThreadSuspend) \
template(ThreadsSuspendJVMTI) \
template(ICBufferFull) \
template(ScavengeMonitors) \
template(PrintMetadata) \
template(GTestExecuteAtSafepoint) \
template(JFROldObject) \Stop the world 阶段可以简单分为(这段时间内,JVM 都是出于所有线程进入 Safepoint 就 block 的状态):
某个操作,需要 Stop the world(就是上面提到的哪些情况下会让所有线程进入 SafePoint, 即发生 Stop the world 的那些操作)
向 Signal Dispatcher 这个 JVM 守护线程发起 Safepoint 同步信号并交给对应的模块执行。
对应的模块,采集所有线程信息,并对每个线程根据状态做不同的操作以及标记(根据之前源代码那一块的描述,有5种情况)
所有线程都进入 Safepoint 并 block。
做需要发起 Stop the world 的操作。
操作完成,所有线程从 Safepoint 恢复。
基于这些阶段,导致 Stop the world 时间过长的原因有:
阶段 4 耗时过长,即等待所有线程中的某些线程进入 Safepoint 的时间过长,这个很可能和有 大有界循环与JIT优化 有关,也很可能是 OpenJDK 11 引入的获取调用堆栈的类StackWalker的使用导致的,也可能是系统 CPU 资源问题或者是系统内存脏页过多或者发生 swap 导致的。
阶段 5 耗时过长,需要看看是哪些操作导致的,例如偏向锁撤销过多, GC时间过长等等,需要想办法减少这些操作消耗的时间,或者直接关闭这些事件(例如关闭偏向锁,关闭 JFR 的 OldObjectSample 事件采集)减少进入,这个和本篇内容无关,这里不赘述。
阶段2,阶段3耗时过长,由于 Signal Dispatcher 是单线程的,可以看看当时 Signal Dispatcher 这个线程在干什么,可能是 Signal Dispatcher 做其他操作导致的。也可能是系统 CPU 资源问题或者是系统内存脏页过多或者发生 swap 导致的。
已知:只有线程执行到 Safepoint 代码才会知道Thread.intterupted()的最新状态 ,而不是线程的本地缓存。
我们来看下面一段代码:
static int algorithm(int n) {
int bestSoFar = 0;
for (int i=0; i<n; ++i) {
if (Thread.interrupted()) {
System.out.println("broken by interrupted");
break;
}
//增加pow计算,增加计算量,防止循环执行不超过1s就结束了
bestSoFar = (int) Math.pow(i, 0.3);
}
return bestSoFar;
}
public static void main(String[] args) throws InterruptedException {
Runnable task = () -> {
Instant start = Instant.now();
int bestSoFar = algorithm(1000000000);
double durationInMillis = Duration.between(start, Instant.now()).toMillis();
System.out.println("after "+durationInMillis+" ms, the result is "+bestSoFar);
};
//延迟1ms之后interrupt
Thread t = new Thread(task);
t.start();
Thread.sleep(1);
t.interrupt();
//延迟10ms之后interrupt
t = new Thread(task);
t.start();
Thread.sleep(10);
t.interrupt();
//延迟100ms之后interrupt
t = new Thread(task);
t.start();
Thread.sleep(100);
t.interrupt();
//延迟1s之后interrupt
//这时候 algorithm 里面的for循环调用次数应该足够了,会发生代码即时编译优化并 OSR
t = new Thread(task);
t.start();
Thread.sleep(1000);
//发现线程这次不会对 interrupt 有反应了
t.interrupt();
}之后利用 JVM 参数 -Xlog:jit+compilation=debug:file=jit_compile%t.log:uptime,level,tags:filecount=10,filesize=100M 打印 JIT 编译日志到另一个文件,便于观察。最后控制台输出:
broken by interrupted
broken by interrupted
after 10.0 ms, the result is 27
after 1.0 ms, the result is 10
broken by interrupted
after 99.0 ms, the result is 69
after 29114.0 ms, the result is 501可以看出,最后一次循环直接运行结束了,并没有看到线程已经 interrupted 了。并且 JIT 编译日志可以看到,在最后一线程执行循环的时候发生了发生代码即时编译优化并 OSR:
[0.782s][debug][jit,compilation] 460 % 3 com.test.TypeTest::algorithm @ 4 (44 bytes)
[0.784s][debug][jit,compilation] 468 3 com.test.TypeTest::algorithm (44 bytes)
[0.794s][debug][jit,compilation] 486 % 4 com.test.TypeTest::algorithm @ 4 (44 bytes)
[0.797s][debug][jit,compilation] 460 % 3 com.test.TypeTest::algorithm @ 4 (44 bytes) made not entrant
[0.799s][debug][jit,compilation] 503 4 com.test.TypeTest::algorithm (44 bytes)3 还有 4 表示编译级别,% 表示是 OSR 栈上替换方法,也就是 for 循环还在执行的时候,进行了执行代码的机器码替换。在这之后,线程就看不到线程已经 interrupted 了,这说明,** JIT 优化后的代码,for 循环里面的 Safepoint 会被拿掉**。
这样带来的问题,也显而易见了,当需要 Stop the world 的时候,所有线程都会等着这个循环执行完,因为这个线程只有执行完这个大循环,才能进入 Safepoint。
那么,如何优化呢?
第一种方式是修改代码,将 for int 的循环变成 for long 类型:
for (long i=0; i<n; ++i) {
if (Thread.interrupted()) {
System.out.println("broken by interrupted");
break;
}
//增加pow计算,增加计算量,防止循环执行不超过1s就结束了
bestSoFar = (int) Math.pow(i, 0.3);
}第二种是通过-XX:+UseCountedLoopSafepoints参数,让 JIT 优化代码的时候,不会拿掉有界循环里面的 SafePoint
用这两种方式其中一种之后的控制台输出:
broken by interrupted
broken by interrupted
after 0.0 ms, the result is 0
after 10.0 ms, the result is 29
broken by interrupted
after 100.0 ms, the result is 73
broken by interrupted
after 998.0 ms, the result is 170目前,在 OpenJDK 11 版本,主要有两种 SafePoint 相关的日志。一种基本上只在开发时使用,另一种可以在线上使用持续采集。
第一个是-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1,这个会定时采集,但是采集的时候会触发所有线程进入 Safepoint,所以,线程一般不打开(之前我们对于定时让所有线程进入 Safepoint 都要关闭,这个就更不可能打开了)。并且,在 Java 12 中已经被移除,并且接下来的日志配置基本上可以替代这个,所以这里我们就不赘述这个了。
另外是通过-Xlog:safepoint=trace:stdout:utctime,level,tags,对于 OpenJDK 的日志配置,可以参考我的另一篇文章详细解析配置的格式,这里我们直接用。
我们这里配置了所有的 safepoint 相关的 JVM 日志都输出到控制台,一次 Stop the world 的时候,就会像下面这样输出:
[2020-07-14T07:08:26.197+0000][debug][safepoint] Safepoint synchronization initiated. (112 threads)
[2020-07-14T07:08:26.197+0000][info ][safepoint] Application time: 12.4565068 seconds
[2020-07-14T07:08:26.197+0000][trace][safepoint] Setting thread local yield flag for threads
[2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c7c494b30 [0x61dc] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0
[2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c7c497f30 [0x4ff8] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0
......省略一些处于 _at_poll_safepoint 的线程
[2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c10c010b0 [0x5878] State: _call_back _has_called_back 0 _at_poll_safepoint 0
[2020-07-14T07:08:26.348+0000][trace][safepoint] Thread: 0x0000022c10bfe560 [0x5038] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0
[2020-07-14T07:08:26.197+0000][debug][safepoint] Waiting for 1 thread(s) to block
[2020-07-14T07:08:29.348+0000][info ][safepoint] Entering safepoint region: G1CollectForAllocation
[2020-07-14T07:08:29.350+0000][info ][safepoint] Leaving safepoint region
[2020-07-14T07:08:29.350+0000][info ][safepoint] Total time for which application threads were stopped: 3.1499371 seconds, Stopping threads took: 3.1467255 seconds首先,阶段 1 会打印日志,这个是 debug 级别的,代表要开始全局所有线程 Safepoint 了,这时候,JVM 就开始无法响应请求了,也就是 Stop the world 开始:
[2020-07-14T07:08:29.347+0000][debug][safepoint] Safepoint synchronization initiated. (112 threads)阶段 2 不会打印日志,阶段 3 会打印:
[2020-07-14T07:08:26.197+0000][info ][safepoint] Application time: 12.4565068 seconds
[2020-07-14T07:08:26.197+0000][trace][safepoint] Setting thread local yield flag for threads
[2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c7c494b30 [0x61dc] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0
[2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c7c497f30 [0x4ff8] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0
......省略一些处于 _at_poll_safepoint 的线程
[2020-07-14T07:08:26.197+0000][trace][safepoint] Thread: 0x0000022c10c010b0 [0x5878] State: _call_back _has_called_back 0 _at_poll_safepoint 0
[2020-07-14T07:08:26.348+0000][trace][safepoint] Thread: 0x0000022c10bfe560 [0x5038] State: _at_safepoint _has_called_back 0 _at_poll_safepoint 0
[2020-07-14T07:08:26.197+0000][debug][safepoint] Waiting for 1 thread(s) to blockApplication time: 12.4565068 seconds 代表上次全局 Safepoint 与这次 Safepoint 间隔了多长时间。后面 trace 的日志表示每个线程的状态,其中没有处于 Safepoint 的只有一个:
Thread: 0x0000022c10c010b0 [0x5878] State: _call_back _has_called_back 0 _at_poll_safepoint 0这里有详细的线程号,可以通过 jstack 知道这个线程是干啥的。
最后的Waiting for 1 thread(s) to block也代表到底需要等待几个线程走到 Safepoint。
阶段 4 执行完,开始阶段 5 的时候,会打印:
[2020-07-14T07:08:29.348+0000][info ][safepoint] Entering safepoint region: G1CollectForAllocation阶段 5 执行完之后,会打印:
[2020-07-14T07:08:29.350+0000][info ][safepoint] Leaving safepoint region最后阶段 6 开始的时候,会打印:
[2020-07-14T07:08:29.350+0000][info ][safepoint] Total time for which application threads were stopped: 3.1499371 seconds, Stopping threads took: 3.1467255 secondsTotal time for which application threads were stopped是这次阶段1到阶段6开始,一共过了多长时间,也就是 Stop the world 多长时间。后面的Stopping threads took是这次等待线程走进 Safepoint 过了多长时间,一般除了 阶段 5 执行触发 Stop the world 以外,都是由于 等待线程走进 Safepoint 时间长。这是就要看 trace 的线程哪些没有处于 Safepoint,看他们干了什么,是否有大循环,或者是使用了StackWalker这个类.
JFR 相关的配置以及说明以及如何通过 JFR 分析 SafePoint 相关事件,可以参考我的另一个系列JFR全解系列
常见的 SafePoint 调优参数以及讲解
建议关闭定时让所有线程进入 Safepoint
对于微服务高并发应用,没必要定时进入 Safepoint,所以关闭 -XX:+UnlockDiagnosticVMOptions -XX:GuaranteedSafepointInterval=0
建议取消偏向锁
在高并发应用中,偏向锁并不能带来性能提升,反而因为偏向锁取消带来了很多没必要的某些线程进入Safepoint 或者 Stop the world。所以建议关闭:-XX:-UseBiasedLocking
建议打开循环内添加 Safepoint 参数
防止大循环 JIT 编译导致内部 Safepoint 被优化省略,导致进入 SafePoint 时间变长:-XX:+UseCountedLoopSafepoints
建议打开 debug 级别的 safepoint 日志(和第五个选一个)
debug 级别虽然看不到每次是哪些线程需要等待进入 Safepoint,但是整体每阶段耗时已经很清楚了。如果是 trace 级别,每次都能看到是那些线程,但是这样每次进入 safepoint 时间就会增加几毫秒。
-Xlog:safepoint=debug:file=safepoint.log:utctime,level,tags:filecount=50,filesize=100M建议打开 JFR 关于 safepoint 的采集(和第四个选一个)
修改,或者新建 jfc 文件:
<event name="jdk.SafepointBegin">
<setting name="enabled">true</setting>
<setting name="threshold">10 ms</setting>
</event>
<event name="jdk.SafepointStateSynchronization">
<setting name="enabled">true</setting>
<setting name="threshold">10 ms</setting>
</event>
<event name="jdk.SafepointWaitBlocked">
<setting name="enabled">true</setting>
<setting name="threshold">10 ms</setting>
</event>
<event name="jdk.SafepointCleanup">
<setting name="enabled">true</setting>
<setting name="threshold">10 ms</setting>
</event>
<event name="jdk.SafepointCleanupTask">
<setting name="enabled">true</setting>
<setting name="threshold">10 ms</setting>
</event>
<event name="jdk.SafepointEnd">
<setting name="enabled">true</setting>
<setting name="threshold">10 ms</setting>
</event>
<event name="jdk.ExecuteVMOperation">
<setting name="enabled">true</setting>
<setting name="threshold">10 ms</setting>
</event>感谢各位的阅读,以上就是“什么是SafePoint与Stop The World”的内容了,经过本文的学习后,相信大家对什么是SafePoint与Stop The World这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3611782/blog/4886034



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



