本篇内容主要讲解“压缩算法怎么在构建部署中的优化”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“压缩算法怎么在构建部署中的优化”吧!
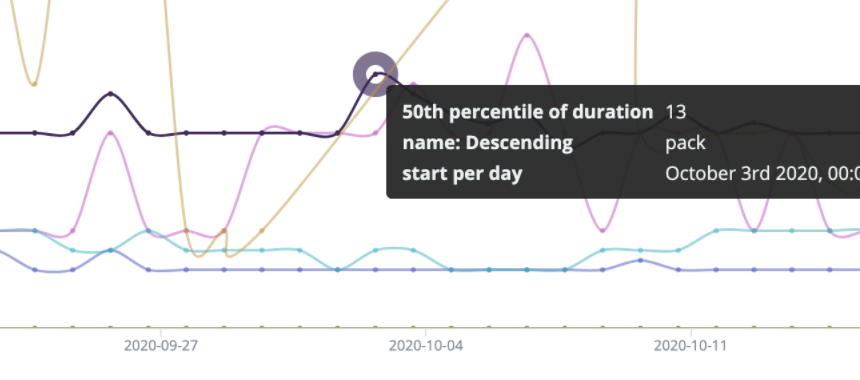
通常而言,服务发布平台的构建部署的流程(镜像部署除外)会经过构建(同步代码 -> 编译 -> 打包 -> 上传)、部署(下载包 -> 解压到目标机器 -> 重启服务)等步骤。以美团内部的发布平台 Plus 为例,最近我们发现一些发布项在构建产物打包压缩的过程中耗时比较久。如下图所示的 pack 步骤,一共消耗了1分23秒。

而在平常为用户解答运维问题的时候我们也发现,很多用户会习惯将一些较大的机器学习或者 NLP 相关的数据放入到仓库中,这部分数据往往占据几百兆,甚至占据几个GB的磁盘空间,十分影响打包的速度。 Java 项目也是如此,由于 Java 服务框架繁多,依赖也多,通常这些服务打包后也要占据百兆级别的空间,耗时也会达到十多秒。下图是我们的 pack 步骤的中位数,基本上大部分的 Java 服务和 Node.js 服务都至少要消耗 13s 左右的时间来做压缩打包 。
pack 作为几乎所有需要部署的服务必需步骤,它目前的耗时基本上仅低于编译和构建镜像,因此,为了提高整体构建的效率,我们准备对 pack 打包压缩的步骤进行一轮优化工作。
发布项的包大小分析
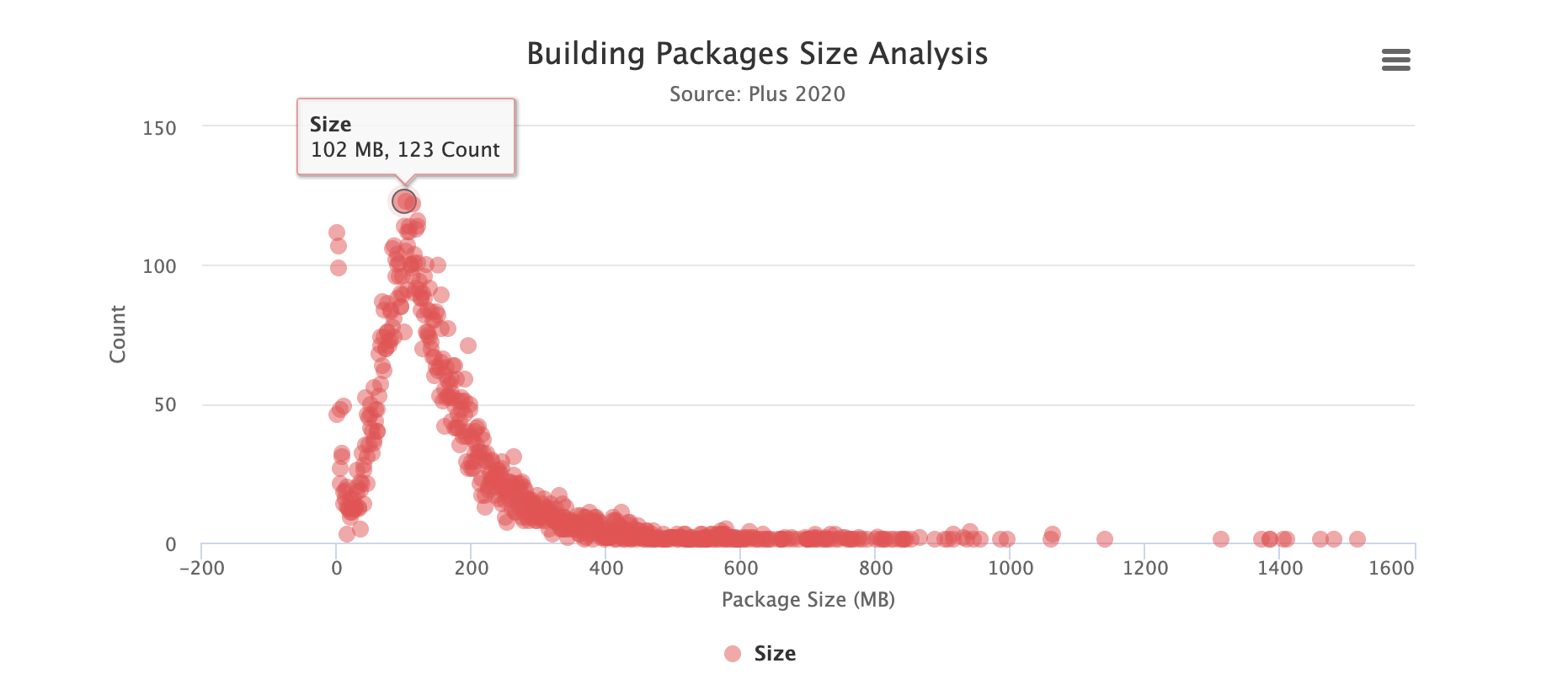
为了尽可能地模拟构建部署中的应用场景,我们将 2020 年的部分构建包数据进行了整理分析,其中压缩后的包大小如下图所示,钟形曲线说明了整体的包体积呈正态分布,并且有着较明显的长尾效应。压缩后体积主要在 200M 以内,压缩前的大小大致在 516.0MB 以内。
而 99%的服务压缩包大小会在 1GB 以内,而对于压缩步骤而言,其实越大的项目耗时越明显,优化的空间越大。因此,我们在针对性的方案对比测试中选择了 1GB 左右的构建包进行压缩测试,既能覆盖 99% 的场景,也可以看出压缩算法之间比较明显的提升。
这样选择的主要原因如下:
数据大的情况下计算结果会比小数据误差小很多。
能够覆盖绝大多数应用场景。
效果对比明显,可以看到是否有明显的提升。
备注:由于在相同压缩库相同压缩比等配置的情况下,Compression Speed 并没有明显变化,因此没有做其它包体积的批量测试和数据汇总。
本文中我们使用的测试项目为美团内部的较大型的 C++ 项目,其中文件类型除去 C++、Python、Shell 代码文件,还有 NLP、工具等二进制数据(不包括 .git 中存储的提交数据),数据类型比较全面。
目录大小为 1.2G,也可以比较清晰地对比出不同方案之间的差距。
gzip 是基于 DEFLATE 的算法,它是 LZ77 和 Huffman 编码 的结合。DEFLATE 的目的是为了取代 LZW 和其他受专利保护的数据压缩算法,因为这些算法在当时限制了压缩和其他流行的存档器的可用性(Wikipedia)。
我们通常使用 tar -czf 命令来进行打包并且压缩的操作,z 参数正是使用 gzip 的方式来进行压缩。DEFLATE 标准(RFC1951)是一个被广泛使用的无损数据压缩标准。它的压缩数据格式由一系列块构成,对应输入数据的块,每一块通过 LZ77 (基于字典压缩,就是将最高概率出现的字母以最短的编码表示)算法和 Huffman 编码进行压缩,LZ77 算法通过查找并替换重复的字符串来减小数据体积。
文件格式
一个 10 字节的报头,包含一个魔数 (1f 8b),压缩方法 (比如 08 用于 DEFLATE),1 字节的 header flags,4 字节的时间戳,compression flags 和操作系统 ID。
可选的额外 headers,包括原始文件名、注释字段、“extra” 字段和 header 的 CRC-32 校验码 lower half 。
DEFLATE 压缩主体。
8 字节的 footer,包含 CRC-32校验以及原始未压缩的数据。
我们可以看到 gzip 是主要基于 CRC 和 Huffman LZ77 的 DEFLATE 算法,这也是后面 ISA-L 库的优化目标。
Alakuijala 和 Szabadka 在 2013-2016 年完成了 Brotli 规范,该数据格式旨在进一步提高压缩比,它在优化网站速度上有大量应用。Brotli 规范的正式验证是由 Mark Adler 独立实现的。Brotli 是一个用于数据流压缩的数据格式规范,它使用了通用的 LZ77 无损压缩算法、Huffman 编码和二阶上下文建模(2nd order context modelling)的特定组合。大家可以参考这篇论文查看其实现原理。
因为语言本身的特性,基于上下文的建模方法 (Context Modeling)可以得到更好的压缩比,但由于它的性能问题很难普及。当前比较流行的突破算法有两种:
ANS:Zstd, lzfse
Context Modeling:Brotli, bz2
具体测试数据见下文。
Zstd 全称叫 Zstandard,是一个提供高压缩比的快速压缩算法,主要实现的编程语言为 C,是 Facebook 的 Yann Collet 于2016年发布的,Zstd 采用了有限状态熵(Finite State Entropy,缩写为FSE)编码器。该编码器是由Jarek Duda 基于ANS 理论开发的一种新型熵编码器,提供了非常强大的压缩速度/压缩率的折中方案(事实上也的确做到了“鱼”和“熊掌”兼得)。Zstd 在其最大压缩级别上提供的压缩比接近 lzma、lzham 和 ppmx,并且性能优于 lza 或 bzip2。Zstandard 达到了 Pareto frontier(资源分配最佳的理想状态),因为它解压缩速度快于任何其他当前可用的算法,但压缩比类似或更好。
对于小数据,它还特别提供一个载入预置词典的方法优化速度,词典可以通过对目标数据进行训练从而生成。
官方 Benchmark 数据对比
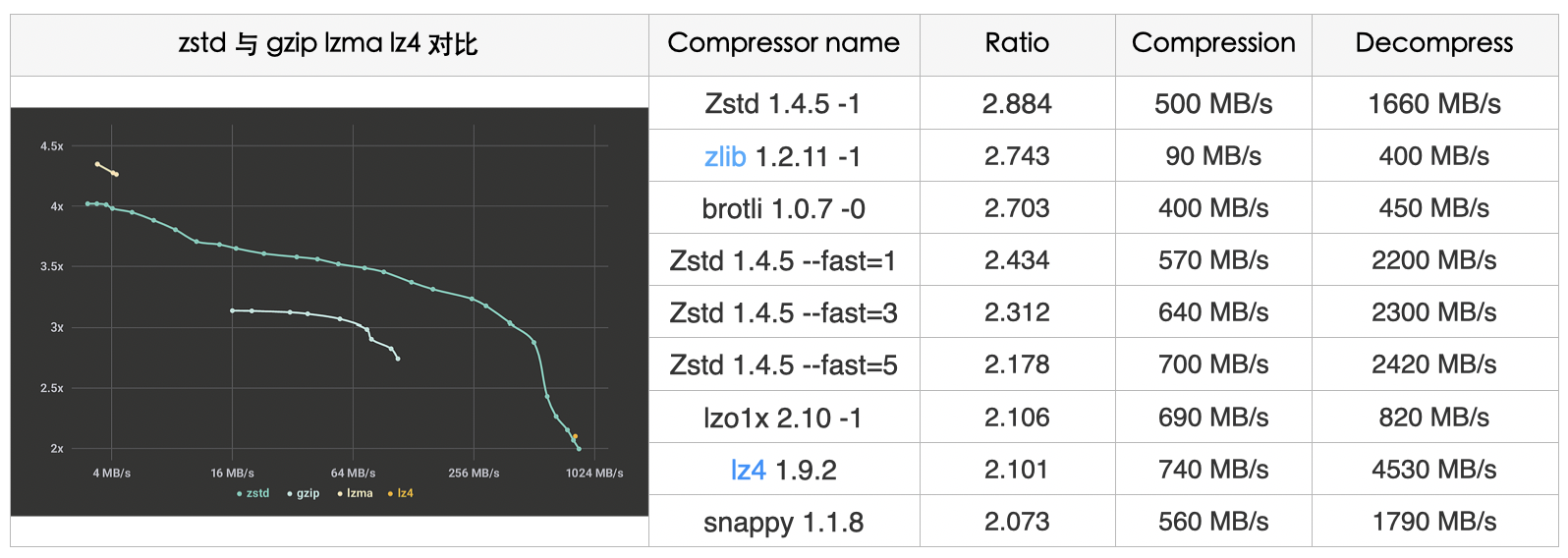
压缩级别可以通过 --fast 指定,提供更快的压缩和解压缩速度,相比级别 1 会导致压缩比率的一些损失,如上表所示。Zstd 可以用压缩速度换取更强的压缩比。它是可配置的小增量,在所有设置下,解压缩速度都保持不变,这是大多数 LZ 压缩算法(如 zlib 或 lzma)共享的特性。
我们采用 Zstd 默认的参数进行了测试,压缩时间 8.471s 仅为原来的 11.266%,提升了 88.733%。
解压时间 3.211 仅为原来的 29.83%,提升约为 70.169%。
同时压缩率也从 2.548 提升到了 2.621。
LZ4是一种无损压缩算法,每核提供大于 500 MB/s的压缩速度(大于0.15 Bytes/cycle)。它的特点是解码速度极快,每核速度为多 GB/s( 约1 Bytes/cycle )。
从上面的 Zstd 的 Benchmark 对比中,我们看到了 LZ4 算法效果十分出众,因此我们也对 LZ4 进行了对比,LZ4 更加侧重压缩解压速度,尤其是解压缩的速度,压缩比并不是它的强项,它默认支持 1-9 的压缩参数,我们分别进行了测试。
LZ4 使用默认参数压缩速度十分优秀,比 Zstd 快很多,但是压缩比并不高,比 Zstd 压缩后多了 206 MB,足足多了 46%,这就意味着更多的数据传输时间和磁盘空间占用。即使是最大的压缩比也并不高,仅仅从 1.79 提升到了 2.11,但是耗时却从 5s 提升到了 51s。通过对比,LZ4 的确在压缩率上并不是最优秀的方案,在 2.x 级别压缩率上基本上时间优势荡然无存,而且还有一点,就是 LZ4 目前官方并没有对多核 CPU 并行压缩的支持,所以在后续的对比中,LZ4 丧失了压缩解压缩速度的优势。
Pigz 的作者 Mark Adler,同时也是 Info-ZIP 的 zip 和 unzip、GNU 的 gzip 和 zlib 压缩库的共同作者,并且是 PNG 图像格式开发工作的参与者。
Pigz 是 gzip 的并行实现的缩写,它主要思想就是利用多个处理器和核。它将输入分成 128 KB 的块,每个块都被并行压缩。每个块的单个校验值也是并行计算的。它的实现直接使用了 zlib 和 pthread 库,比较易读,而且重要的是兼容 gzip 的格式。Pigz 使用一个线程(主线程)进行解压缩,但可以创建另外三个线程进行读、写和检查计算,所以在某些情况下可以加速解压缩。
一些博客在 i7 4790K 这样的家用 PC 平台中测试 Pigz 的压缩性能时,并没有十分高的速度,但在我们真机验证的数据中提升要明显很多。通过测试,它的压缩时间执行速度只用了 1.768s,充分发挥了我们平台物理机的性能,User 时间(CPU 时间之和)一共使用了 1m30.569s,这和前面的使用 gzip 单线程的方式速度几乎是一个级别。压缩率 2.5488 和正常使用 tar -czf 几乎相差不多。
ISA-L 是一套在 IA 架构上加速算法执行的开源函数库,目的在于解决存储系统的计算需求。 ISA-L 使用的是 BSD-3-Clause License ,因此在商业上同样可以使用。
使用过 SPDK(Storage Performance Development Kit )或者 DPDK(Data Plane Development Kit)应该也听说过 ISA-L ,前者使用了 ISA-L 的 CRC 部分,后者使用了它的压缩优化。ISA-L 通过使用高效的 SIMD (Single Instruction, Multiple Data)指令和专用指令,最大化的利用 CPU 的微架构来加速存储算法的计算过程。ISA-L底层函数都是使用手工汇编代码编写,并在很多细节上做了调优(现在经常要考虑 ARM 平台,本文中所提及的部分指令在该平台支持度不高甚至是不支持)。
ISA-L 对压缩算法主要做了 CRC、DEFLATE 和 Huffman 编码的优化实现,官方的数据指出 ISA-L 相比 zlib-1 有 5 倍的速度提升。
举例来说,不少底层的存储开源软件实现的 CRC 都使用了查表法,代码中存储或者生成了一个 CRC value 的表格,然后计算过程中查询值,ISA-L 的汇编代码中包含了无进位乘法指令 PCLMULQDQ 对两个64位数做无进位乘法,最大化 intel PCLMULQDQ 指令的吞吐量来优化 CRC 的性能。更好的情况是 CPU 支持 AVX-512,就可以使用 VPCLMULQDQ(PCLMULQDQ 在 EVEX 编码的 512 bit 版本实现)等其它优化指令集(查看是否支持的方式见“附录”)。

备注:截图来自 crc32_ieee_by16_10.asm
使用
ISA-L 实现的压缩优化级别支持 [0,3],3 为压缩比最大的版本,综合考虑我们采用了最大的压缩比,虽然压缩比 2.346 略低于 gzip 不过影响不大。在 2019 年 6 月发布的 v2.27 版本里,ISA-L 加了多线程的 Feature,因此在后续的测试中,我们采用了多线程并发的参数,效果提升比较显著。
由于我们构建机器的系统为 Centos7 需要自行编译 ISA-L 的依赖,比如 nasm 等库,所以在安装配置上会比较复杂,ISA-L 支持多种优化参数比如,IGZIP_HIST_SIZE(压缩过程中加大滑动窗口),LONGER_HUFFTABLES,更大的 Huffman 编码表,这些编译参数也会对库有很大提升。
压缩时间
real 0m1.372s
user 0m5.512s
sys 0m1.791s测试后的效果相当惊人,是目前对比方案中最为快速的,时间上节省了 98.09%。
由于和 gzip 格式兼容,因此同样可以使用 tar -xf 命令进行解压,后续的解压缩测试过程中,我们使用的仍然是 ISA-L 提供的解压方式。
通过 Pigz 的测试,我们就在想,是否 Zstd 这样优秀的算法也可以支持并行呢,在官方的 Repo 中,我们十分惊喜地发现了一个“宝藏”。
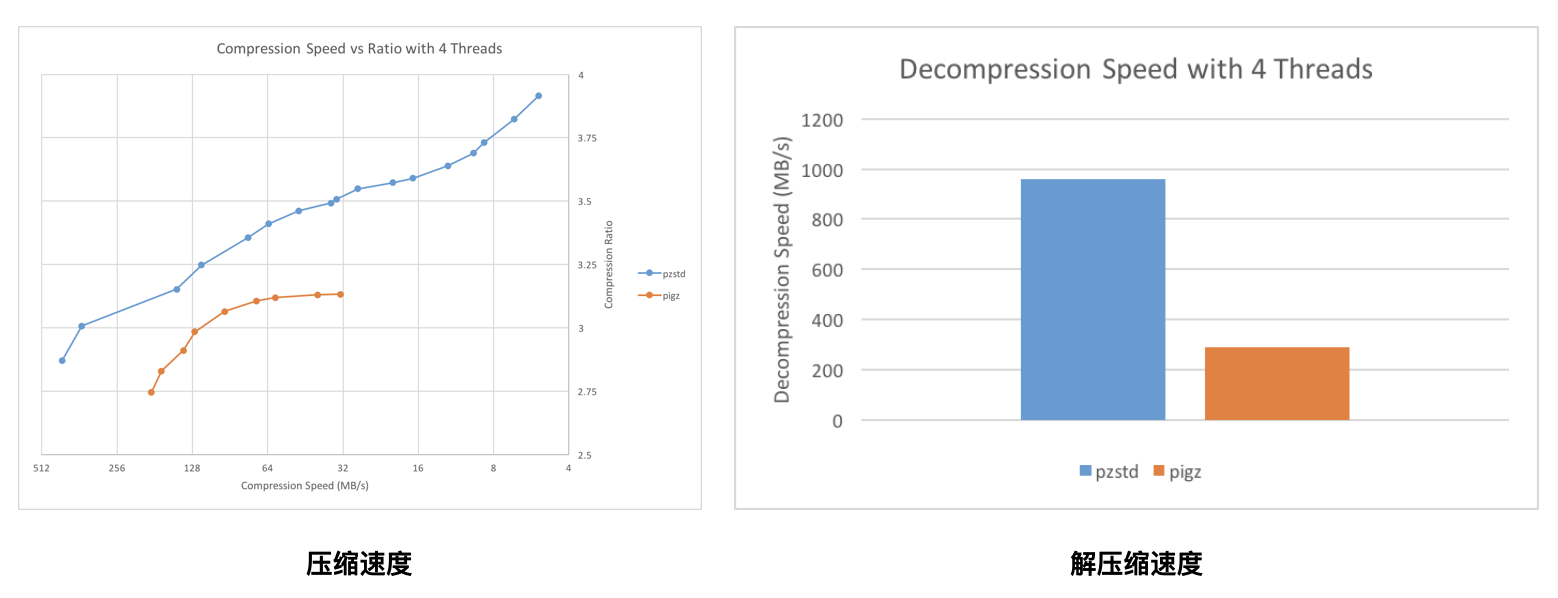
Pzstd 是 C++11 实现的并行版本的 Zstandard (Zstd 也在这之后加入了多线程的支持),类似于 Pigz 的工具。 它提供了与 Zstandard 格式兼容的压缩和解压缩功能,可以利用多个 CPU 核心。 它将输入分成相等大小的块,并将每个块独立压缩为 Zstandard 帧。 然后将这些帧连接在一起以产生最终的压缩输出。 Pzstd 同样支持文件的并行解压缩。 解压缩使用 Zstandard 压缩的文件时,PZstandard 在一个线程中执行 IO,而在另一个线程中进行解压缩。
下图是和 Pigz 的压缩和解压缩速度对比,来自官方 Github 仓库(机器配置为:Intel Core i7 @ 3.1 GHz, 4 threads),效果比 Pigz 还要出色,具体对比数据见下文:
Middle-out Compression 最初是在美剧中提到的一个概念,不过现在已经有了一个真正的实现 middle-out,该算法目前小范围应用在压缩时序数据中,由于缺乏成熟地理论支撑以及数据对比,没有正式进入方案的对标。
备注:Pied Piper 是美剧《硅谷》 中虚拟出来的公司和算法。

本文中调研所提及的对比方案,都是统一在构建集群中的机器中进行测试,由于构建系统 在线上的机器集群配置高度统一(包括硬件平台和系统版本),所以兼容性表现和测试数据也高度吻合。
实际上,部分官方的测试机器的配置和美团构建平台的物理机配置并不一致,场景可能也有区别,上面引用的测试结果中所使用的CPU以及平台架构和编译环境和我们所用的也有些出入,而且大多数还是家用的硬件比如 i7-4790K 或者 i9-9900K,这也是需要使用构建平台的物理机和具体的构建包压缩场景来进行测试的原因,因为这样才能得出最接近我们使用场景的数据。
几个方案的数据对比如下表格(在本文中的时间数据选择是通过多次运行后,选择结果的中位数):

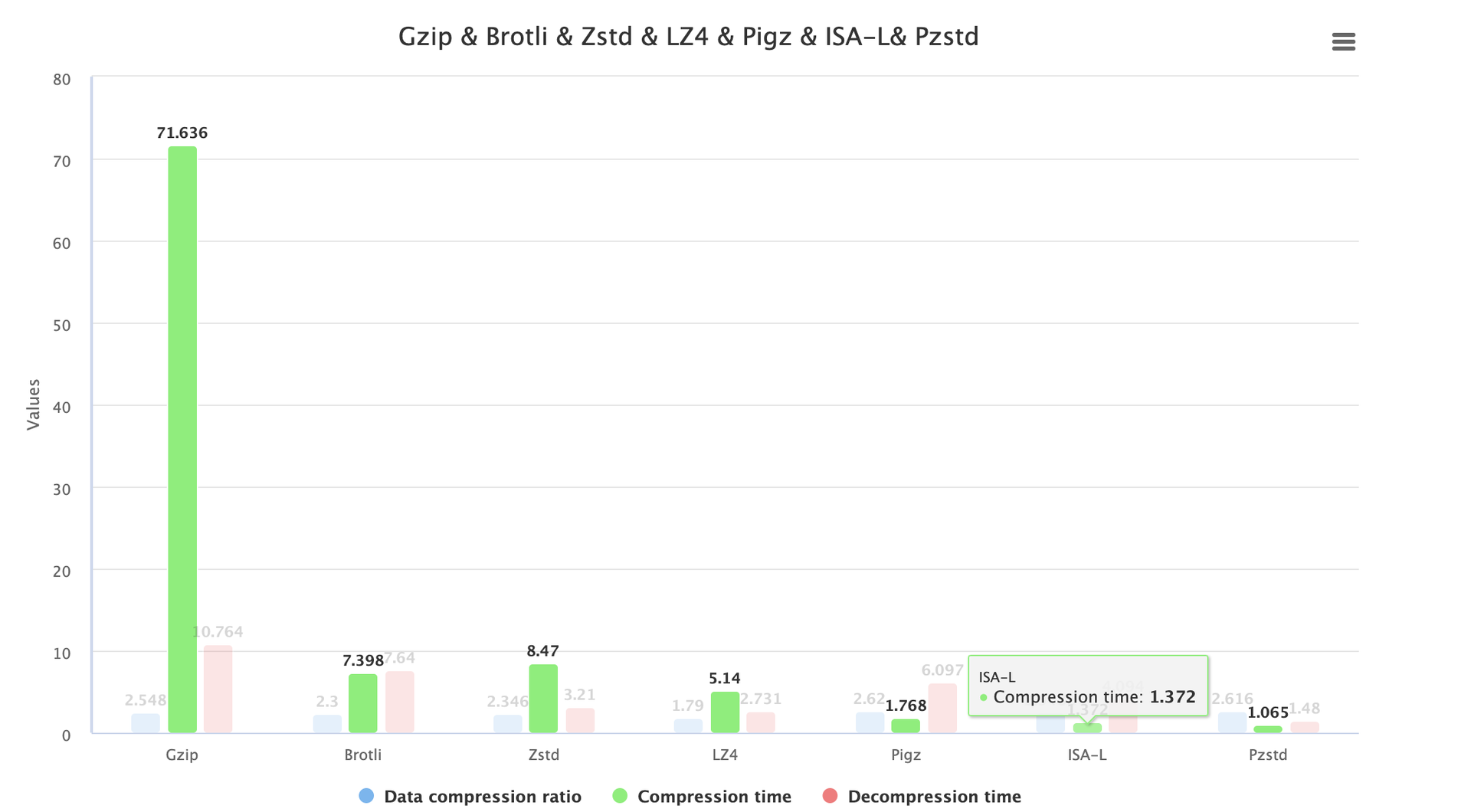
压缩时间对比
从整个构建后的压缩构建包的时间可视化图中可以看出,最初版本的 gzip 压缩相当耗时,而采取 Pzstd 是最快速的方案,ISA-L 稍慢,Pigz 略微慢一点,这三者都可以达到从 1m11s 到 1s 左右的优化,最快可以节省 98.51% 的压缩时间。
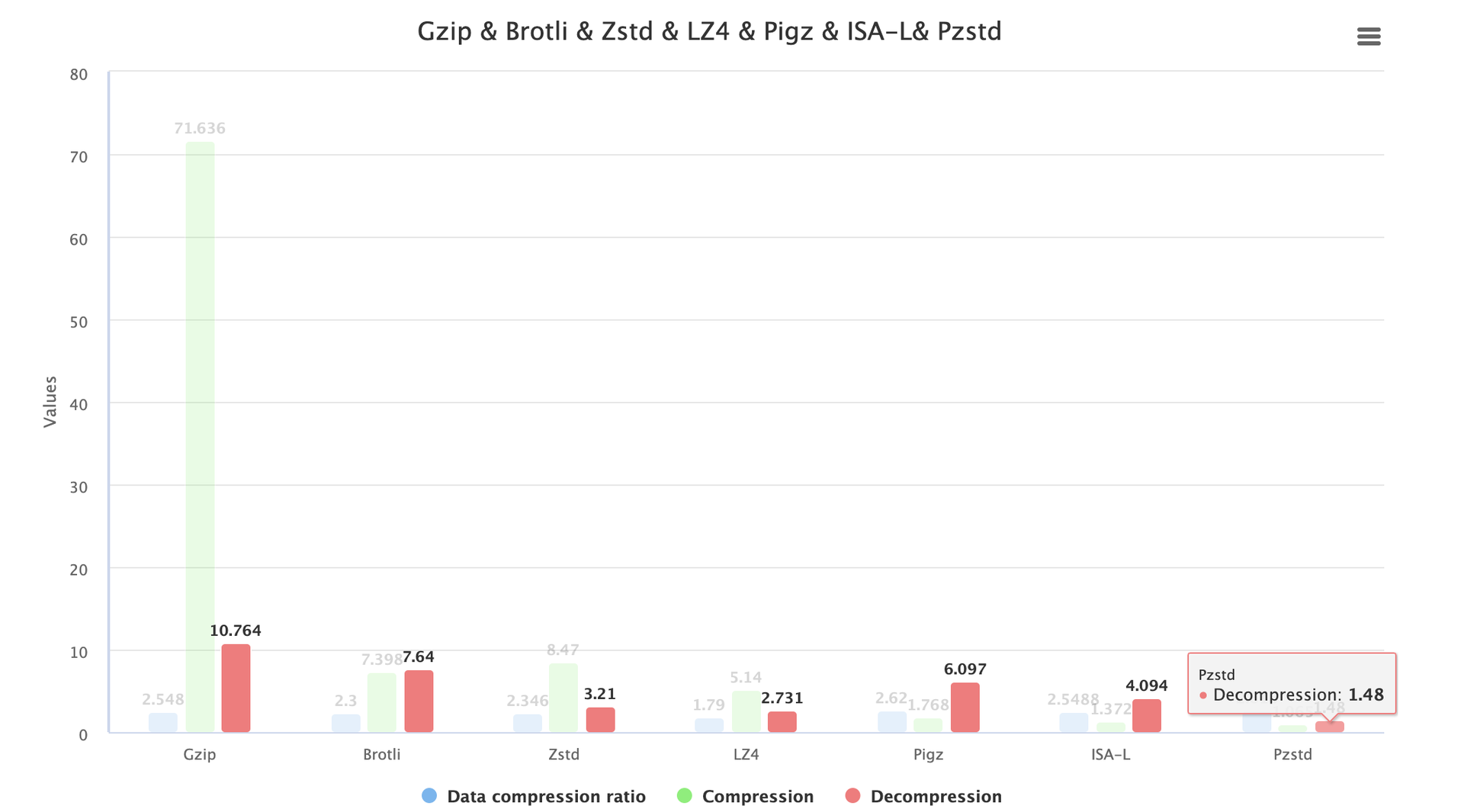
解压缩时间对比
解压缩的时间上并没有像压缩效率相差很多,在 GB 级别的项目中压缩比 2.5-2.6 范围内时,时间都在 11s 以内。而且为了最大兼容已有的实现和保持稳定性,解压方案优先考虑兼容 gzip 格式的策略,这样对部署目标机器的侵入性最小,即可以使用 tar -xf 解压的方案优先。
而在后面的方案实施中,由于部署需要稳定可靠的环境,所以我们暂时没有对部署机器做环境改造。
下面的时间对比是分别使用各自的解压方案的对比:
Pzstd 解压速度最快,相比 Gzip 节省了 86.241% 的时间。
Zstd 算法的解压缩效率其次,大约可以节省 70.169% 的解压时间。
ISA-L 可节省 61.9658% 的时间。
Pigz 可节省 43.357% 的解压时间。
Brotli 解压可以节省 29.02% 的时间。
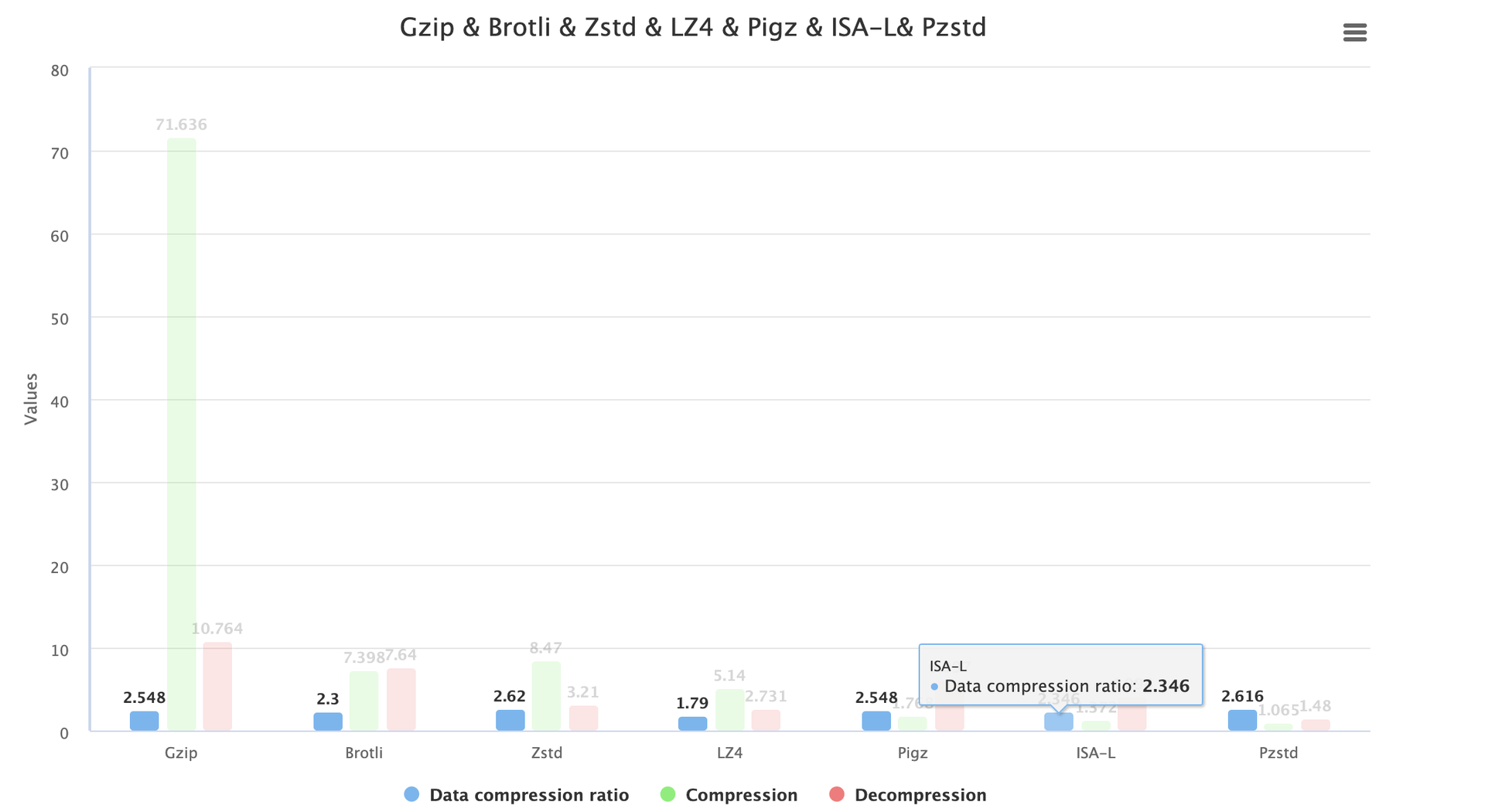
压缩比的对比
压缩比的对比中 Zstd 和 Pzstd 有一些优势,其中 Brotli 和 LZ4 由于支持的参数限制,比较难测试同级别压缩比下的速度,因此选择了压缩比稍低的参数,但是效率仍然距离 Pigz 和 Pzstd 存在一些差距。
而 ISA-L 的实现在压缩比上有一些牺牲,不过并没有差距很大。
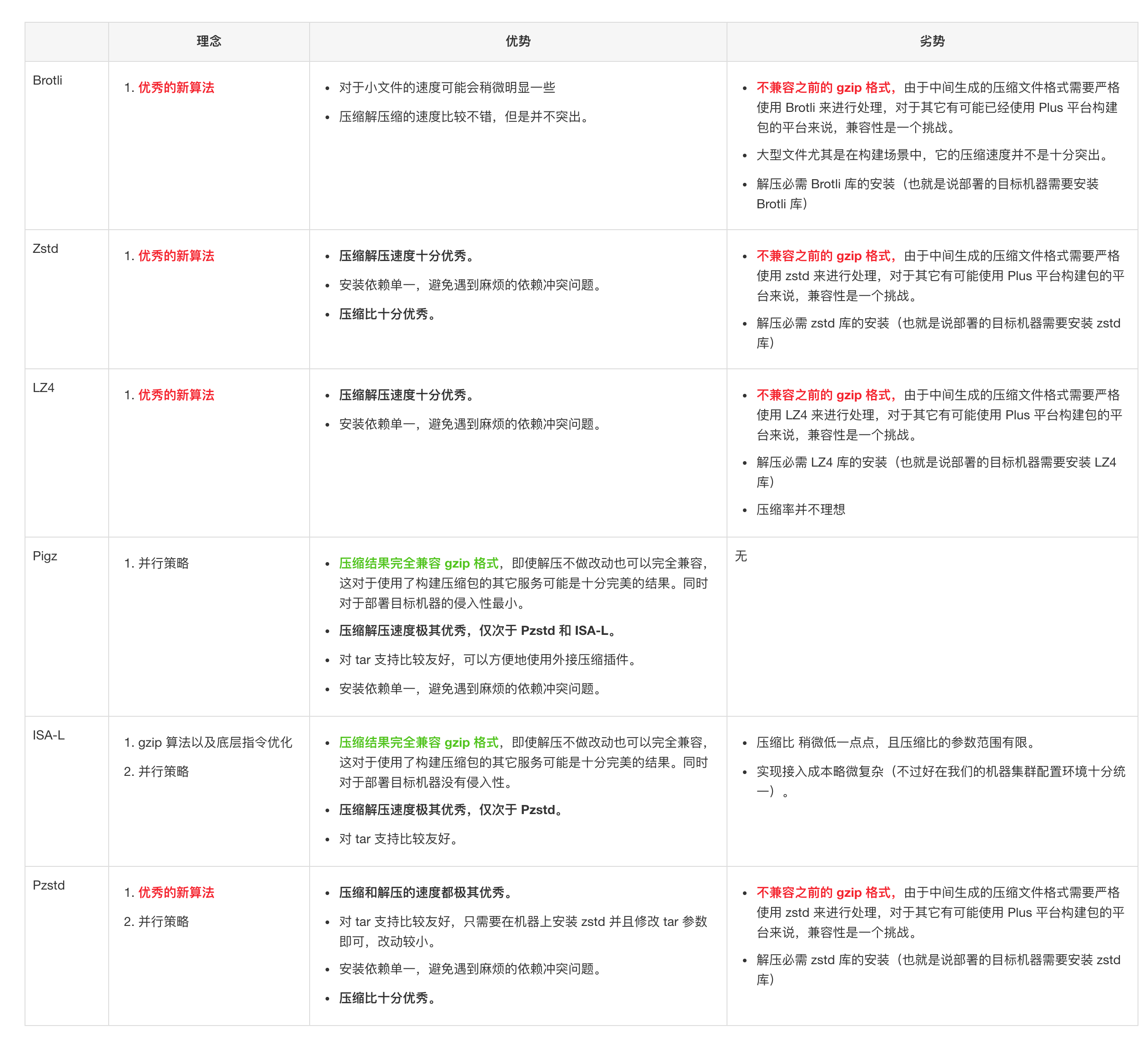
优劣分析总结
在本文开始阶段,我们介绍了构建部署流程,因此我们此次优化的目标时间大致计算公式如下:
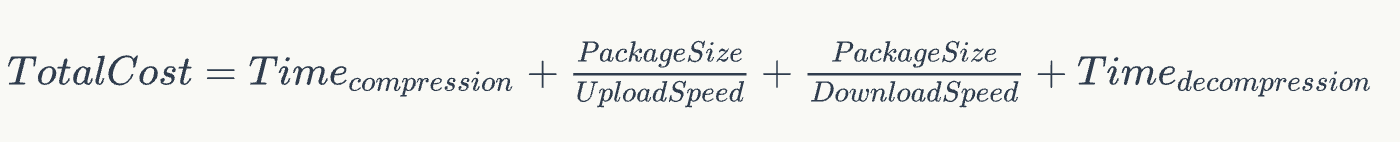
在测试案例对比中,时间耗时的顺序为 Pzstd < ISA-L < Pigz < LZ4 < Zstd < Brotli < Gzip (排名越靠前越好),其中压缩和解压缩的时间在整体的耗时上占比较大,因此备选策略为 Pzstd、ISA-L、Pigz。
当然,这其中还存在磁盘空间的成本优化问题,即压缩比可能对磁盘空间产生优化,但是对构建的耗时会产生负优化,不过由于目前时间维度是我们优化的主要目标,比磁盘成本和上传带宽成本要重要,因此压缩比采用了较为普遍或者默认最优的压缩比方案,即在 2.3 - 2.6 范围内。不过在一些内存型数据库等存储介质成本较为高的场景中,也许要综合多个方面需要更多考量,请大家知悉。
比较于 gzip,新算法都具有想当不错的速度,但是由于压缩格式的向前不兼容,加上需要客户端(部署目标机器)的支持,可能方案实施周期会较长。
而对于部署来说,可能收益并不是十分明显,反而加重了一些维护和运维成本,所以我们暂时没有把 Pzstd 的方案放到较高的优先级。
选型的策略主要有基于如下原则:
整体耗时优化提升最大,这也是整体优化方案的出发点。
保证最大兼容性,为了让接入构建平台的业务和平台减少改动成本,需要保持方案的兼容性(优先考虑最大兼容的策略,即兼容 gzip 的方案优先)。
保证部署目标机器环境的稳定和可靠,选择对部署机器侵入最小的方案,这样无需安装客户端或者库。
压缩场景在真机模拟测试中完全契合美团构建平台的场景,即在我们现有的物理机平台和目标压缩场景中对比数据效果良好。
其实本问题更全面的评分角度有很多维度,比如对象存储的磁盘成本、带宽成本、任务耗时,甚至是机器成本,不过为了简化整体方案的选型,我们省略了一些计算,同时压缩比的对比选择上也选择了各自官方推荐的范围。
综合以上几点,决定一期采取 ISA-L 的方式加速,可以最稳定并且较高速地提升构建平台的效率,未来可能会实现 Pzstd 的方案,下面的数据为一期的结果。
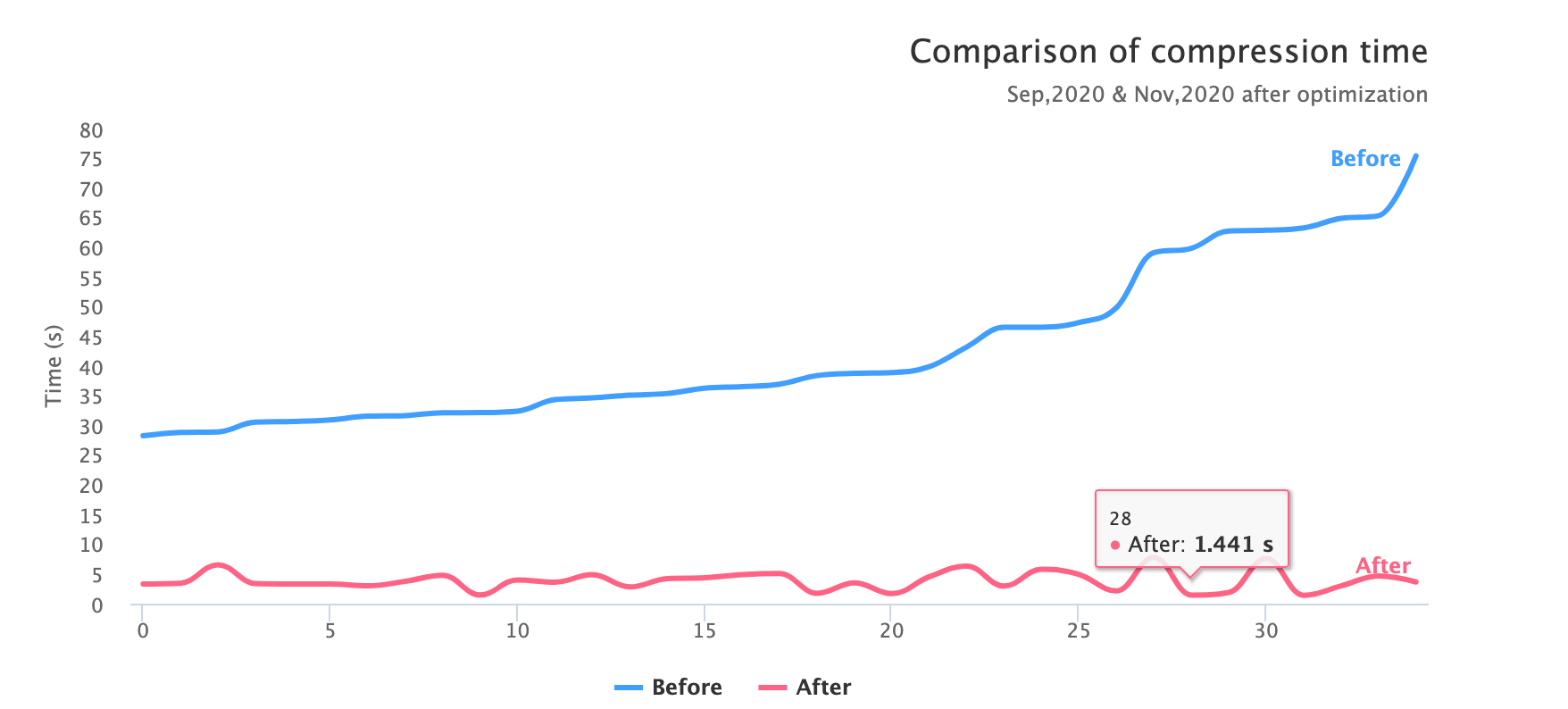
为了方便结果的展示,我们过滤出了部分打包时间较长的发布项展示出来(这些耗时很久的项目往往十分影响用户的使用体验,而且总体的占比在 10% 左右),这部分任务优化的时间从 27s 到 72s 不等,过去越是项目大的项目压缩时间越长,如今压缩时间都可以稳定在 10s 以内,而且是在我们的机器同时执行多个任务的情况下。
而后我们将优化前的 Pack 步骤(压缩+上传)部分打点数据,以及优化后的部分打点数据做了汇总,得出了平均的优化效果对比,数据如下:
在我们之前的一个构建包的统计中,多数的构建包压缩后在 100MB 左右,压缩前大概是在 250MB,按照 gzip 算法的压缩速度的确会在 10s 左右的级别。
由于构建的物理机可能同时运行多个任务,所以实际压缩效果会比测试中稍微耗时多一点。

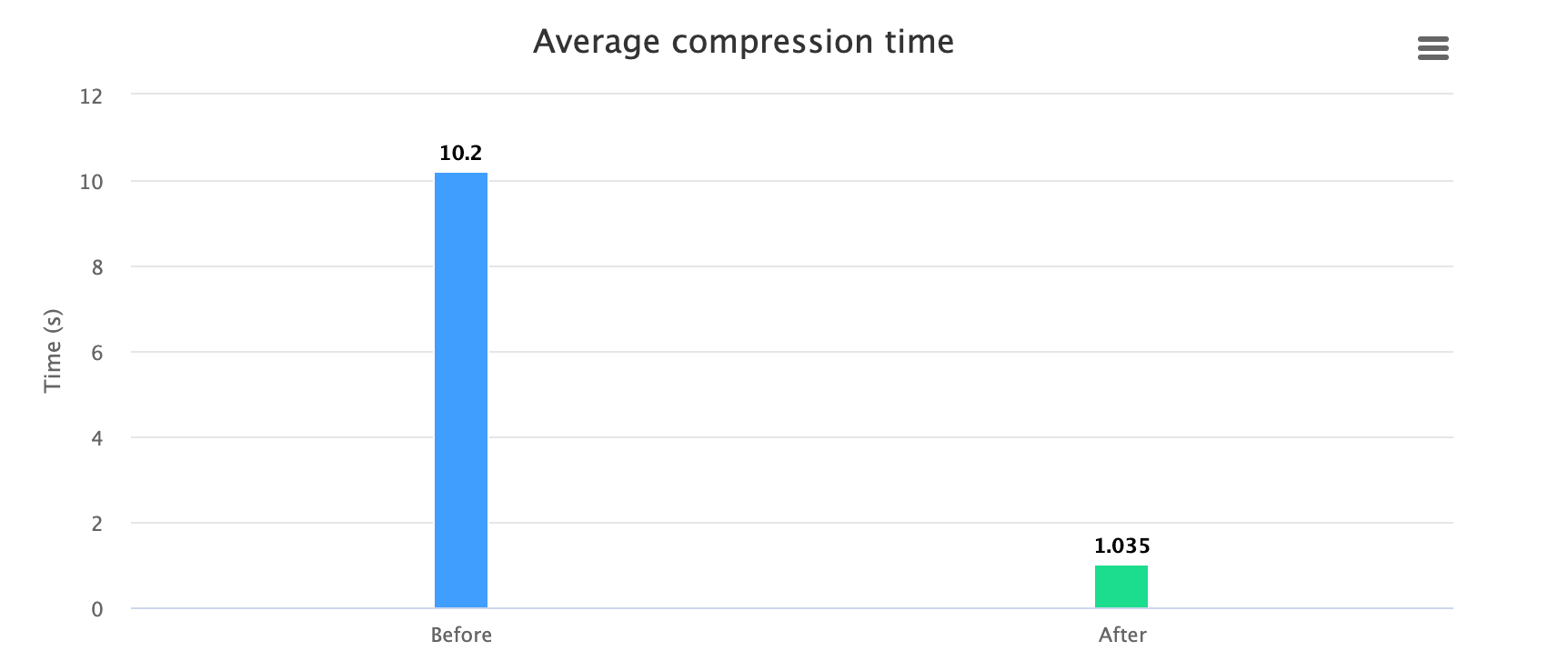
压缩平均节省了 90% 的时间。
到此,相信大家对“压缩算法怎么在构建部署中的优化”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/meituantech/blog/4890269



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



