本篇内容主要讲解“如何理解LinkedList源码”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何理解LinkedList源码”吧!
LinkedList类图如下:
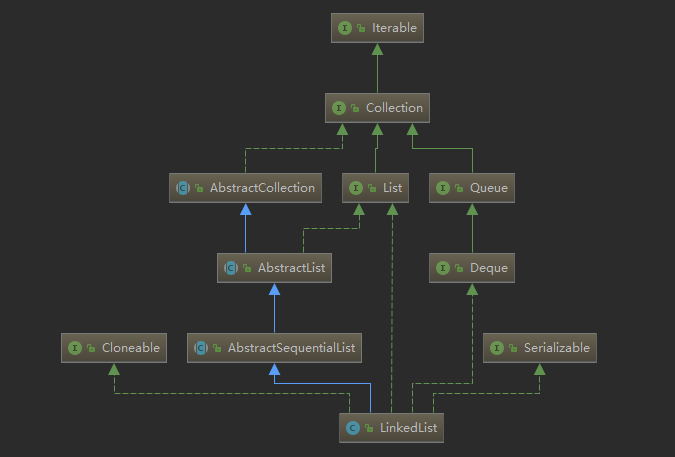
LinkedList底层是由双向链表实现的。链表好比火车,每节车厢包含了车厢和连接下一节车厢的连接点。而双向链表的每个节点不仅有指向下一个节点的指针,还有指向上一个节点的指针。 在LinkedList源码中有一个Node静态类,源码如下:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}一个Node节点包含三个部分,分别是
item:数据
next:下一个节点的指针
prev:上一个节点的指针
LinkedList的主要变量如下:
// 集合中的元素数量
transient int size = 0;
/**
* 首节点的指针.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* 尾结点的指针.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;LinkedList支持想任意节点位置添加元素,不仅提供了集合常用的add()方法,还提供了addFirst()和addLast(),add()方法默认调用addLast()方法,也就是默认是往链表尾部插入元素的。
add()方法源码:
public boolean add(E e) {
linkLast(e);
return true;
}linkLast()源码如下:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}我们来画张图演示一下如何给链表尾部插入元素:
假如链表中没有元素
对应源码中的if语句,如果没有元素则新增的这个节点为链表中唯一的一个元素,既是首节点,又是尾结点,前一个元素的指针和后一个元素的指针都是null。这里注意head节点不是第一个节点,head节点只是标识了这个链表的地址。

假如链表中有元素
对应源码中else语句。先将新增的元素当成Last节点,然后将原来的Last节点的next指向新节点。
else
l.next = newNode;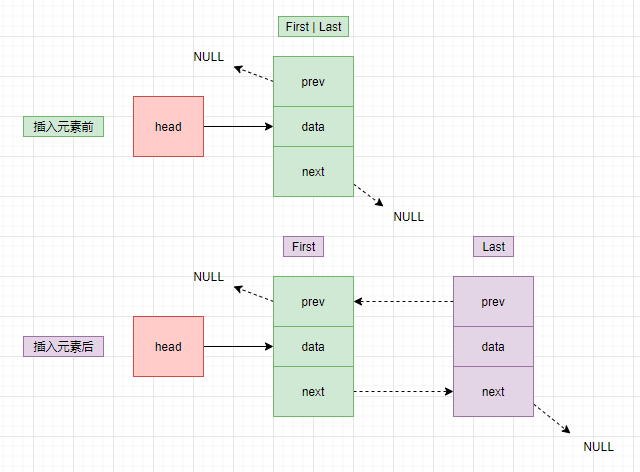
一图胜前言,画个图是不是什么都明白了。
linkFirst()源码如下:
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}还是根据上面的图来解读一下源码,先将第一个节点赋值给中间变量f,将新节点newNode赋值给first节点。如果链表没有元素,则Last节点和First节点都是新插入的节点newNode,否则,将原来的First节点的头指针指向新节点。
LinkedList提供的删除方法有根据索引和元素删除,除此之外还提供删除第一个元素和最后一个元素的方法,这里我们只分析一下根据索引删除的方法。
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}checkElementIndex(index)方法就是用来判断传输的索引值是否合法,不合法则抛出数组越界异常。重点来看一下unlink(node(index))方法是如何删除元素的。
node(index)方法源码:
node(index)方法就是根据索引获取该索引位置的节点
Node<E> node(int index) {
// assert isElementIndex(index);
// 如果指定下标 < 一半元素数量,则从首结点开始遍历
// 否则,从尾结点开始遍历
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}unlink(Node<E> x)源码如下:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}画张图分析一下删除是如何进行的:

假设删除的是第一个元素:则它的prev==NULL,我们需要将他的后一个元素(图中的second)作为第一个元素
假设删除的是最后一个元素,则它的next==null,我们需要将他的前一个元素(途中的second)作为最后一个元素
如果是中间的任意元素,则需要将它的前一个元素的next指针指向它的后一个元素,同时将它的后一个元素的prev指针指向它的前一个元素。
到此,相信大家对“如何理解LinkedList源码”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4021330/blog/4815564



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



