这篇文章主要讲解了“Java哈希表怎么理解”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Java哈希表怎么理解”吧!
Java 中对象的 hashCode 根据对象的地址来生成的,唯一不重复。为什么要重写hashcode跟equals
Hash表也称散列表,也有直接译作哈希表,Hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,它采用了函数映射的思想将记录的存储位置与记录的关键字关联起来,从而能够很快速地进行查找。
数组是方便查询不方便删除,链表是方便删除不方便查询。
1.Hash表的设计思想
对于一般的线性表,比如链表,如果要存储联系人信息:
张三 13980593357 李四 15828662334 王五 13409821234 张帅 13890583472
那么可能会设计一个结构体包含姓名,手机号码这些信息,然后把4个联系人的信息存到一张链表中。当要查找”李四 15828662334“这条记录是否在这张链表中或者想要得到李四的手机号码时,可能会从链表的头结点开始遍历,依次将每个结点中的姓名同”李四“进行比较,直到查找成功或者失败为止,这种做法的时间复杂度为O(n)。即使采用二叉排序树进行存储,也最多为O(logn)。假设能够通过”李四“这个信息直接获取到该记录在表中的存储位置,就能省掉中间关键字比较的这个环节,复杂度直接降到O(1)。Hash表就能够达到这样的效果。
Hash表采用一个映射函数 f : key —> address 将关键字映射到该记录在表中的存储位置,从而在想要查找该记录时,可以直接根据关键字和映射关系计算出该记录在表中的存储位置,通常情况下,这种映射关系称作为Hash函数,而通过Hash函数和关键字计算出来的存储位置(注意这里的存储位置只是表中的存储位置,并不是实际的物理地址)称作为Hash地址。比如上述例子中,假如联系人信息采用Hash表存储,则当想要找到“李四”的信息时,直接根据“李四”和Hash函数计算出Hash地址即可。下面讨论一下Hash表设计中的几个关键问题。
Hash函数设计的好坏直接影响到对Hash表的操作效率。下面举例说明:
假如对上述的联系人信息进行存储时,采用的Hash函数为:姓名的每个字的拼音开头大写字母的ASCII码之和。
因此address(张三)=ASCII(Z)+ASCII(S)=90+83=173;
address(李四)=ASCII(L)+ASCII(S)=76+83=159;
address(王五)=ASCII(W)+ASCII(W)=87+87=174;
address(张帅)=ASCII(Z)+ASCII(S)=90+83=173;
假如只有这4个联系人信息需要进行存储,这个Hash函数设计的很糟糕。首先,它浪费了大量的存储空间,假如采用char型数组存储联系人信息的话,则至少需要开辟174*12字节的空间,空间利用率只有4/174,不到5%;另外,根据Hash函数计算结果之后,address(张三)和address(李四)具有相同的地址,这种现象称作冲突,对于174个存储空间中只需要存储4条记录就发生了冲突,这样的Hash函数设计是很不合理的。所以在构造Hash函数时应尽量考虑关键字的分布特点来设计函数使得Hash地址随机均匀地分布在整个地址空间当中。通常有以下几种构造Hash函数的方法:
1)直接定址法
取关键字或者关键字的某个线性函数为Hash地址,即address(key)=a*key+b;如知道学生的学号从2000开始,最大为4000,则可以将address(key)=key-2000作为Hash地址。
2)平方取中法
对关键字进行平方运算,然后取结果的中间几位作为Hash地址。假如有以下关键字序列{421,423,436},平方之后的结果为{177241,178929,190096},那么可以取{72,89,00}作为Hash地址。
3)折叠法
将关键字拆分成几部分,然后将这几部分组合在一起,以特定的方式进行转化形成Hash地址。假如知道图书的ISBN号为8903-241-23,可以将address(key)=89+03+24+12+3作为Hash地址。
4)除留取余法
如果知道Hash表的最大长度为m,可以取不大于m的最大质数p,然后对关键字进行取余运算,address(key)=key%p。
在这里p的选取非常关键,p选择的好的话,能够最大程度地减少冲突,p一般取不大于m的最大质数。
Hash表大小的确定也非常关键,如果Hash表的空间远远大于最后实际存储的记录个数,则造成了很大的空间浪费,如果选取小了的话,则容易造成冲突。在实际情况中,一般需要根据最终记录存储个数和关键字的分布特点来确定Hash表的大小。还有一种情况时可能事先不知道最终需要存储的记录个数,则需要动态维护Hash表的容量,此时可能需要重新计算Hash地址。
在上述例子中,发生了冲突现象,因此需要办法来解决,否则记录无法进行正确的存储。通常情况下有2种解决办法:
1)开放定址法
即当一个关键字和另一个关键字发生冲突时,使用某种探测技术在Hash表中形成一个探测序列,然后沿着这个探测序列依次查找下去,当碰到一个空的单元时,则插入其中。比较常用的探测方法有线性探测法,比如有一组关键字{12,13,25,23,38,34,6,84,91},Hash表长为14,Hash函数为address(key)=key%11,当插入12,13,25时可以直接插入,而当插入23时,地址1被占用了,因此沿着地址1依次往下探测(探测步长可以根据情况而定),直到探测到地址4,发现为空,则将23插入其中。
2)链地址法
采用数组和链表相结合的办法,将Hash地址相同的记录存储在一张线性表中,而每张表的表头的序号即为计算得到的Hash地址。如上述例子中,采用链地址法形成的Hash表存储表示为:
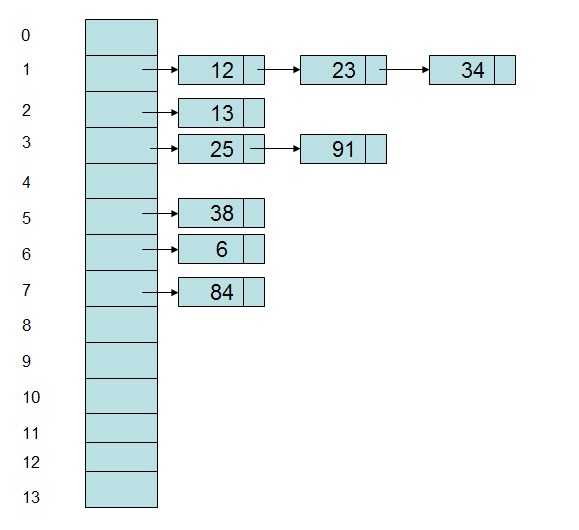
虽然能够采用一些办法去减少冲突,但是冲突是无法完全避免的。因此需要根据实际情况选取解决冲突的办法。
Hash表的平均查找长度包括查找成功时的平均查找长度和查找失败时的平均查找长度。
查找成功时的平均查找长度:表中每个元素查找成功时的比较次数之和/表中元素个数;
查找不成功时的平均查找长度:相当于在表中查找元素不成功时的平均比较次数,可以理解为向表中插入某个元素,该元素在每个位置都有可能,然后计算出在每个位置能够插入时需要比较的次数,再除以表长即为查找不成功时的平均查找长度。
下面举个例子:
有一组关键字{23,12,14,2,3,5},表长为14,Hash函数为key%11,解决冲突方式为开放定值法,则关键字在表中的存储如下:
| 地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 关键字 | 23 | 12 | 14 | 2 | 3 | 5 | ||||||||
| 比较次数 | 1 | 2 | 1 | 3 | 3 | 2 | ||||||||
| 备注 | 比较1次 | 比较1次移动1次 | 比较1次 | 比较1次移动2次 | 比较1次移动2次 | 比较1次移动1次 |
查找成功时的平均查找长度为 :(1+2+1+3+3+2)/6=11/6;
查找失败时的平均查找长度为(1+7+6+5+4+3+2+1+1+1+1+1+1+1)/14=38/14;
查找失败的长度重点理解下是需要比较的次数(为1 时说明就调用了hash函数一次,7说明计算了1次还可能会出现冲突6次)。就可以退出上述值了。
这里有一个概念
装填因子 = 表中的记录数 / 哈希表的长度,
如果装填因子越小,表明表中还有很多的空单元,则发生冲突的可能性越小;
而装填因子越大,则发生冲突的可能性就越大,在查找时所耗费的时间就越多。
因此,Hash表的平均查找长度和装填因子有关。有相关文献证明当装填因子在0.5左右的时候,Hash的性能能够达到最优。因此,一般情况下,装填因子取经验值0.5。
Hash表存在的优点显而易见,能够在常数级的时间复杂度上进行查找,并且插入数据和删除数据比较容易。但是它也有某些缺点,比如不支持排序,一般比用线性表存储需要更多的空间,并且记录的关键字不能重复。
/*Hash表,采用数组实现/
#include<stdio.h>
#define DataType int
#define M 30
typedef struct HashNode
{
DataType data; //存储值
int isNull; //标志该位置是否已被填充
}HashTable;
HashTable hashTable[M];
void initHashTable() //对hash表进行初始化
{
int i;
for(i = 0; i<M; i++)
{
hashTable[i].isNull = 1; //初始状态为空
}
}
int getHashAddress(DataType key) //Hash函数
{
return key % 29; //Hash函数为 key%29
}
int insert(DataType key) //向hash表中插入元素
{
int address = getHashAddress(key);
if(hashTable[address].isNull == 1) //没有发生冲突
{
hashTable[address].data = key;
hashTable[address].isNull = 0;
}
else //当发生冲突的时候
{
while(hashTable[address].isNull == 0 && address<M)
{
address++; //采用线性探测法,步长为1
}
if(address == M) //Hash表发生溢出
return -1;
hashTable[address].data = key;
hashTable[address].isNull = 0;
}
return 0;
}
int find(DataType key) //进行查找
{
int address = getHashAddress(key);
while( !(hashTable[address].isNull == 0 && hashTable[address].data == key && address<M))
{
address++;
}
if( address == M)
address = -1;
return address;
}
int main(int argc, char *argv[])
{
int key[]={123,456,7000,8,1,13,11,555,425,393,212,546,2,99,196};
int i;
initHashTable();
for(i = 0; i<15; i++)
{
insert(key[i]);
}
for(i = 0; i<15; i++)
{
int address;
address = find(key[i]);
printf("%d %d\n", key[i],address);
}
return 0;
}HashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,HashCode经常用于确定对象的存储地址(不是真实的物理地址!);
如果两个对象相同(物理地址一样), equals方法一定返回true,并且这两个对象的HashCode一定相同;
两个对象的HashCode相同,并不一定表示两个对象就相同,即equals()不一定为true,只能说明这两个对象在一个散列存储结构中(因为可能存在冲突,采用了拉链法解决了冲突)。
如果对象的equals方法被重写,那么对象的HashCode也尽量重写。
Java中的集合有两类,一类是List,再有一类是Set。前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。 equals方法可用于保证元素不重复,但如果每增加一个元素就检查一次,若集合中现在已经有1000个元素,那么第1001个元素加入集合时,就要调用1000次equals方法。这显然会大大降低效率。 于是,Java采用了哈希表的原理。
哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。这样一来,当集合要添加新的元素时,先调用这个元素的HashCode方法,就一下子能定位到它应该放置的物理位置上。
如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;
如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了;
不相同的话,也就是发生了Hash key相同导致冲突的情况,那么就在这个Hash key的地方产生一个链表,将所有产生相同HashCode的对象放到这个单链表上去,串在一起。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
从Object角度看,JVM每new一个Object,它都会将这个Object丢到一个Hash表中去,这样的话,下次做Object的比较或者取这个对象的时候(读取过程),它会根据对象的HashCode再从Hash表中取这个对象。这样做的目的是提高取对象的效率。若HashCode相同再去调用equal。Java底层获取hashCode的方法如下:
// 表示的是 JVM 根据某种策略 为这个Object对象分配的一个int类型的数值
public native int hashCode();比如Integer类型获得hashCode的方法如下:
public int hashCode() {
return value;
}String类型的hashCode获得方法如下:
public int hashCode() {
int h = hash;
if (h == 0) {
int off = offset;
char val[] = value;
int len = count;
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
hash = h;
}
return h;
}HashCode是用于查找使用的,而equals是用于比较两个对象是否相等的。
(1)例如内存中有这样的位置 :
0 1 2 3 4 5 6 7
而我有个类,这个类有个字段叫ID,我要把这个类存放在以上8个位置之一,如果不用HashCode而任意存放,那么当查找时就需要到这八个位置里挨个去找,或者用二分法一类的算法。 但以上问题如果用HashCode就会使效率提高很多。 定义我们的HashCode为ID%8,比如我们的ID为9,9除8的余数为1,那么我们就把该类存在1这个位置,如果ID是13,求得的余数是5,那么我们就把该类放在5这个位置。依此类推。
(2)如果两个类有相同的HashCode,例如9除以8和17除以8的余数都是1,也就是说,我们先通过 HashCode来判断两个类是否存放某个桶里,但这个桶里可能有很多类,那么我们就需要再通过equals在这个桶里找到我们要的类。
请看下面这个例子 :
public class HashTest {
private int i;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
public int hashCode() {
return i % 10;
}
public final static void main(String[] args) {
HashTest a = new HashTest();
HashTest b = new HashTest();
a.setI(1);
b.setI(1);
Set<HashTest> set = new HashSet<HashTest>();
set.add(a);
set.add(b);
System.out.println(a.hashCode() == b.hashCode());
System.out.println(a.equals(b));
System.out.println(set);
}
}
=====
true
false
[HashTest@1, HashTest@1]以上这个示例,我们只是重写了HashCode方法,从上面的结果可以看出,虽然两个对象的HashCode相等,但是实际上两个对象并不是相等,因为我们没有重写equals方法,那么就会调用Object默认的equals方法,显示这是两个不同的对象。
这里我们将生成的对象放到了HashSet中,而HashSet中只能够存放唯一的对象,也就是相同的(适用于equals方法来判断是否放入)的对象只会存放一个,但是这里实际上是两个对象ab都被放到了HashSet中,这样HashSet就失去了他本身的意义了。
下面我们继续重写equals方法:
public class HashTest {
private int i;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
public boolean equals(Object object) {
if (object == null) {
return false;
}
if (object == this) {
return true;
}
if (!(object instanceof HashTest)) {
return false;
}
HashTest other = (HashTest) object;
if (other.getI() == this.getI()) {
return true;
}
return false;
}
public int hashCode() {
return i % 10;
}
public final static void main(String[] args) {
HashTest a = new HashTest();
HashTest b = new HashTest();
a.setI(1);
b.setI(1);
Set<HashTest> set = new HashSet<HashTest>();
set.add(a);
set.add(b);
System.out.println(a.hashCode() == b.hashCode());
System.out.println(a.equals(b));
System.out.println(set);
}
}
=======
true
true
[HashTest@1]从结果我们可以看出,现在两个对象就完全相等了,HashSet中也只存放了一份对象。
感谢各位的阅读,以上就是“Java哈希表怎么理解”的内容了,经过本文的学习后,相信大家对Java哈希表怎么理解这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4511602/blog/4824947



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



