今天就跟大家聊聊有关如何理解kubernetes中的api多版本机制实现,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
在web开发中随着版本的更新迭代,通常要在系统中维护多个版本的api,多个版本的api在数据结构上往往也各不相同,今天就来一起学习下kubernetes中的Scheme机制是如何解决这个问题的,如何借助HTTP请求里面的数据进行反序列化操作
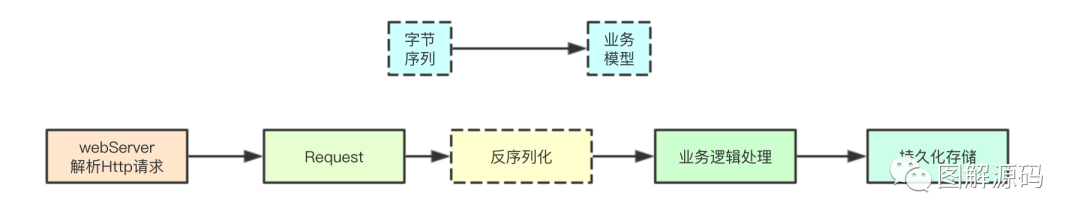 通常首先是webServer先进行Http协议的处理,然后解析成基础的webServer内部的一个Http请求对象, 通常该对象持有对应请求的请求头和底层对应的字节序列(从socket流中读取)接着首先会通常根据对应的编码格式来进行反序列化,完成从字节序列到当前接口的业务模型的映射, 然后在交给业务逻辑处理,从而最终进行持久化存储, 本文的重点也就在反序列化部分
通常首先是webServer先进行Http协议的处理,然后解析成基础的webServer内部的一个Http请求对象, 通常该对象持有对应请求的请求头和底层对应的字节序列(从socket流中读取)接着首先会通常根据对应的编码格式来进行反序列化,完成从字节序列到当前接口的业务模型的映射, 然后在交给业务逻辑处理,从而最终进行持久化存储, 本文的重点也就在反序列化部分
/api/{version}/{resource}/{action}上面是一个基础的web url通常我们都会为每个版本注册一个对应的URL, 其中会包含很关键的两个信息即version与resource,通过这两个信息,通常我们就可以知道这可能是某个资源的那个版本, 如果我们把后面的action也包裹进来,我们通常就可以知道对应的资源的那个具体操作
 在微服务流行的今天我们通常会为按照业务功能来进行微服务的切分,本质上一个微服务可能就是实现某个具体业务场景的功能集合,比如用户系统通常会包含用户的所有相关操作,在kubernetes中也有类似的概念就是所谓的Group
在微服务流行的今天我们通常会为按照业务功能来进行微服务的切分,本质上一个微服务可能就是实现某个具体业务场景的功能集合,比如用户系统通常会包含用户的所有相关操作,在kubernetes中也有类似的概念就是所谓的Group
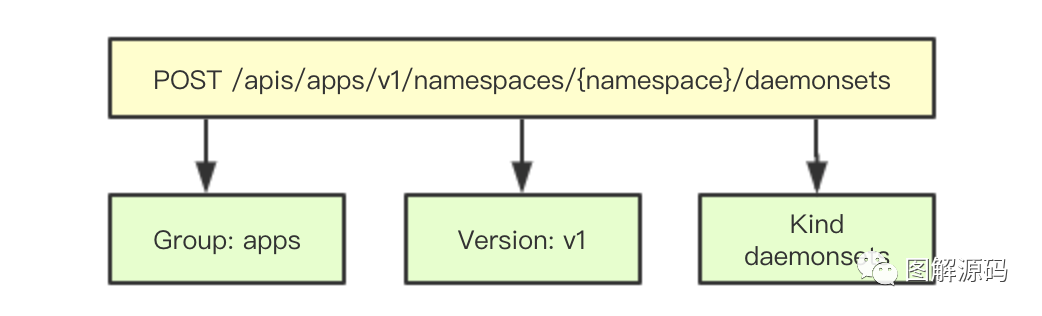
POST /apis/batch/v1beta1/namespaces/{namespace}/cronjobsPOST /apis/apps/v1/namespaces/{namespace}/daemonsets我们来看一个实例这是一个创建daemonsets和cronjobs的url, 如果按照Group、resource、version来进行拆分可以拆成如下:batch、v1beta1、cronjobs和apps、v1、daemonsets,也就是大家尝试的GroupVersionKind,其中kind对应的就是resource
 我们通过url里面获取到资源的GroupVersionKind信息,如何将其映射为一个具体的类型呢?这貌似就很简单了结合反射和map来进行就可以了,我们通过url获取到对应想的GVK信息,然后在通过我们的映射表,就知道对应的模型是哪个,接下来就只需要进行转换就行了
我们通过url里面获取到资源的GroupVersionKind信息,如何将其映射为一个具体的类型呢?这貌似就很简单了结合反射和map来进行就可以了,我们通过url获取到对应想的GVK信息,然后在通过我们的映射表,就知道对应的模型是哪个,接下来就只需要进行转换就行了
gvkToType map[schema.GroupVersionKind]reflect.Type那如何将对应的Http里面的数据流反序列化成内部的一个对象呢,别忘记了是Http协议, 肯定就是header头里面的信息了,我们通过header头里面的序列化就可以知道对应的编码格式,只需要调用对应格式的解码就可以完成了
Content-Type: "application/json"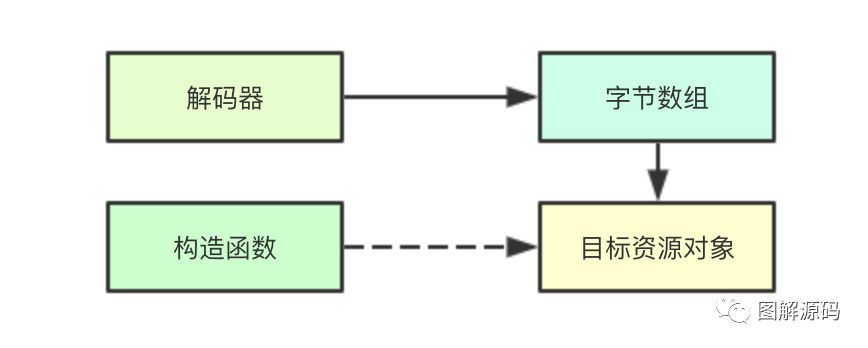 如果要将json格式的字节数组进行解码通常要进行如下操作,我们需要传入一个目标对象的指针,然后由json将对应的字节数据解析到目标对象中,我们也需要这样一个对象,用于存储反序列化的结果
如果要将json格式的字节数组进行解码通常要进行如下操作,我们需要传入一个目标对象的指针,然后由json将对应的字节数据解析到目标对象中,我们也需要这样一个对象,用于存储反序列化的结果
func Unmarshal(data []byte, v interface{}) error {}那只要我再提供一个当前版本对应的对象构造函数是不是就可以呢?答案是的
func() Object{ return 目标对象 },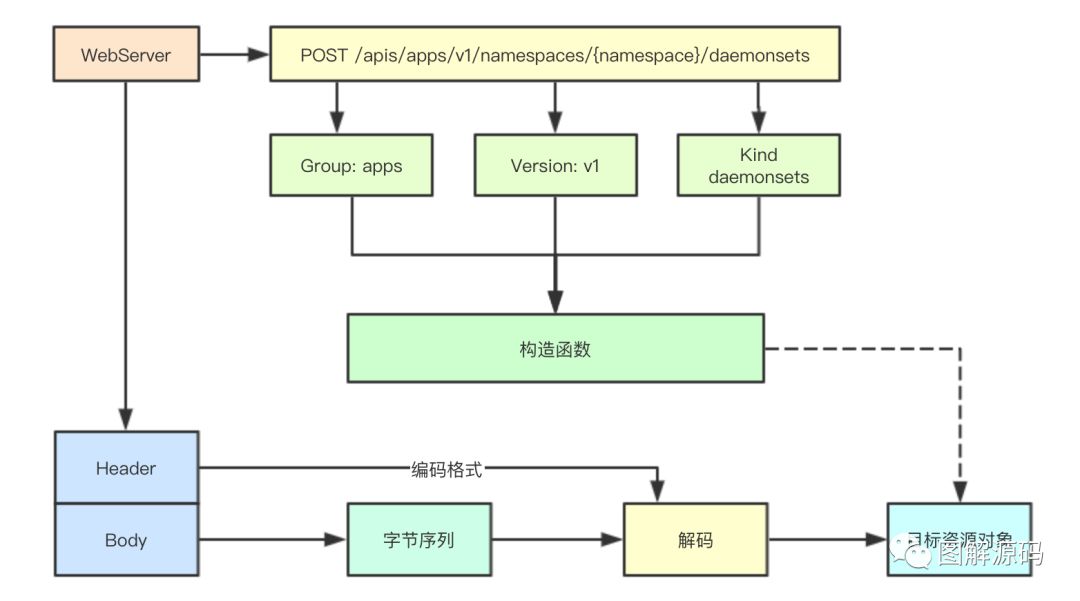 首先在进行url注册的时候,我们构造出对应url映射的资源的版本信息即GroupVersionKind,后续的很多操作我们可以通过对应的版本映射获取对应的目标操作或者对象,然后再通过Header里面的字段获取对应的解码器,并将Body里面的字节序列进行解码到目标对象,就可以实现多版本资源的映射和反序列化操作了。
首先在进行url注册的时候,我们构造出对应url映射的资源的版本信息即GroupVersionKind,后续的很多操作我们可以通过对应的版本映射获取对应的目标操作或者对象,然后再通过Header里面的字段获取对应的解码器,并将Body里面的字节序列进行解码到目标对象,就可以实现多版本资源的映射和反序列化操作了。
看完上述内容,你们对如何理解kubernetes中的api多版本机制实现有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4131034/blog/4723897



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



