这篇文章主要介绍“lucene4.7高亮功能怎么实现”,在日常操作中,相信很多人在lucene4.7高亮功能怎么实现问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”lucene4.7高亮功能怎么实现”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
高亮功能一直都是全文检索的一项非常优秀的模块,在一个标准的搜索引擎中,高亮的返回命中结果,几乎是必不可少的一项需求,因为通过高亮,我们可以在我们的搜索界面上快速标记出用户的检索关键词,从而减少了用户自己寻找想要的结果,在一定程度上大大提高了用户的体验性和友好度。
首先还是喜欢老生常谈的来补充下高亮需要的熟悉的基本知识,当然如果你只是需要实现效果,而不关注它的底层API,那么可以忽略此部分,不过还是要友好的提示一下,如果使用过程中出了点小问题,不会API,可是不容易解决的,除非你愿意各种google。
要使用高亮,首先就得从索引时开始,因为需要高亮的字段,需要准确的获取位置信息,以及一些偏移量,如果信息不准确,那么可能在结果中,就会出现一些莫名其妙的错位,反映到网页上就是标注了不该标注的字,没有标注该标的内容,所以这一点还是需要注意一下,在索引的时候,我们需要使用项向量记录各个token的位置信息,这很简单,代码如下:
FieldType type=new FieldType(TextField.TYPE_STORED);
type.setStoreTermVectorOffsets(true);//记录相对增量
type.setStoreTermVectorPositions(true);//记录位置信息
type.setStoreTermVectors(true);//存储向量信息
type.freeze();//阻止改动信息
Field field=new Field("字段名", "值", type);//示例简单说下,TextField的2个枚举变量的意思
| 变量名 | 释义 |
| TYPE_NOT_STORED | 索引,分词,不存储 |
| TYPE_STORED | 索引,分词,存储 |
由此看来,需要进行高亮的内容,是一定要存储的,可能有一些比较大的文本,会比较占索引空间,从而影响检索性能,当然我们也可以使用外部存储,关系型数据库,nosql什么的都可以,此时,高亮可能就需要做另一些处理了。
下面我们来看下,高亮的需要用到的一些基本的类
| 类 | 释义 |
| SimpleHTMLFormatter | 常用的格式化Html标签器,提供一个构造函数传入高亮颜色标签,默认使用黑色 |
| TokenSources | 提供静态方法,支持从数据源中获取TokenStream,进行token处理 |
| Highlighter | 负责获取匹配上的高亮片段 |
| QueryScorer | 对命中结果进行评分操作 |
| Fragmenter | 将原始字符串拆分成独立的片段 |
| NullFragmenter | 对较短的域进行整体高亮 |
| FastVectorHighlighter | 基于快速高亮 |
| Encoder | 提供一些实现类,对html文本操作,如,去掉一些特殊匹配符号<,> and so on,及一些其他的非ASCII特殊字符。 |
下面我们先来看下散仙的几条测试数据内容:
id:1 name: 中国是一个伟大的国家,我们中国人都是好样的哈哈,中国永远是强大的 content: 你好人民 id:2 name: 我们有一个家它的名字是中国 content: 中国的大地,富饶 id:3 name: 我们的中国,我们的大地都是人民的希望的 content: 如果不在片段中生成一些字段的话 id:4 name: 2014年此时此刻你在做什么的啊 content: 哈哈锄禾日当午 id:5 name: 当你孤单时你会想起谁,你想不想找个人来陪 content: 我永远不孤单啊
1,测试普通高亮的核心代码:
String filed="name";
QueryParser query=new QueryParser(Version.LUCENE_44, filed, new IKAnalyzer(false));
Query q=query.parse("伟大的中国");//测试字段
TopDocs top=searcher.search(q, 100);
QueryScorer score=new QueryScorer(q, filed);//传入评分
SimpleHTMLFormatter fors=new SimpleHTMLFormatter("<span style=\"color:red;\">", "</span>");//定制高亮标签
Highlighter highlighter=new Highlighter(fors,score);//高亮分析器
// highlighter.setMaxDocCharsToAnalyze(1);//设置高亮处理的字符个数
for(ScoreDoc sd:top.scoreDocs){
Document doc=searcher.doc(sd.doc);
String name=doc.get(filed);
TokenStream token=TokenSources.getAnyTokenStream(searcher.getIndexReader(), sd.doc, filed, new IKAnalyzer(true));//获取tokenstream
Fragmenter fragment=new SimpleSpanFragmenter(score);
highlighter.setTextFragmenter(fragment);
String str=highlighter.getBestFragment(token, name);//获取高亮的片段,可以对其数量进行限制
System.out.println("高亮的片段 =====>"+str);
}输出结果如下
高亮的片段 =====>中国是一个<span >伟大</span><span >的</span>国家,我们中国人都是好样<span >的</span>哈哈,<span >中国</span>永远是强大<span >的</span> 高亮的片段 =====>我们<span >的</span><span >中国</span>,我们<span >的</span>大地都是人民<span >的</span>希望<span >的</span> 高亮的片段 =====>我们有一个家它<span >的</span>名字是<span >中国</span>
2,快速高亮,FastVectorHighlighter,这个类可能会消耗更多的存储空间,来换取更好的性能,当然除了性能上提升外,它还有一个非常炫的功能,支持多种颜色标记,高亮关键字,除此之外还支持Ngram的域,以及智能合并相邻高亮短语.
我们来看下散仙快速高亮的3条测试数据:
id:2 name: 中国(China),位于东亚,是一个以华夏文明为主体、中华文化为基础,以汉族为主要种族的统一多民族国家,通用汉语。中国疆域内的各个民族统称为中华民族,龙是中华民族的象征。 content: 中国是世界四大文明古国之一,有着悠久的历史,距今约5000年前,以中原地区为中心开始出现聚落组织进而成国家和朝代,后历经多次演变和朝代更迭,持续时间较长的朝代有夏、商、周、汉、晋、唐、宋、元、明、清等 id:1 name: 中国的自古以来就是一个非常伟大的民族 content: 中国是一个世界人口大国,拥有13亿多的人口. id:3 name: 没有根的野草,飘忽的命运 content: 谁像你当我宝,什么也做到,旧爱数足一块布,在这一刻写句号,只想跟你终老.
核心代码如下:
Query q=query.parse("伟大的中华民族");
TopDocs top=searcher.search(q, 100);
//QueryScorer score=new QueryScorer(q, filed);
//SimpleHTMLFormatter fors=new SimpleHTMLFormatter("<span style=\"color:red;\">", "</span>");//定制高亮标签
//Highlighter highlighter=new Highlighter(fors,score);//高亮分析器
//FastVectorHighlighter fastHighlighter=new FastVectorHighlighter();
FragListBuilder fragListBuilder=new SimpleFragListBuilder();
//注意下面的构造函数里,使用的是颜色数组,用来支持多种颜色高亮
FragmentsBuilder fragmentsBuilder= new ScoreOrderFragmentsBuilder(BaseFragmentsBuilder.COLORED_PRE_TAGS,BaseFragmentsBuilder.COLORED_POST_TAGS);
FastVectorHighlighter fastHighlighter2=new FastVectorHighlighter(true, true, fragListBuilder, fragmentsBuilder);
FieldQuery querys=fastHighlighter2.getFieldQuery(q);//reader是传入的流
// highlighter.setMaxDocCharsToAnalyze(1);//设置高亮处理的字符个数
for(ScoreDoc sd:top.scoreDocs){
String snippt=fastHighlighter2.getBestFragment(querys, reader, sd.doc,filed,300);
if(snippt!=null){
System.out.println("高亮的片段是:"+snippt);
}
}结果如下,注意有多种颜色标识:
高亮的片段是:中国<b >的</b>自古以来就是一个非常<b >伟大</b><b >的</b>民族 高亮的片段是:中国(China),位于东亚,是一个以华夏文明为主体、中华文化为基础,以汉族为主要种族<b >的</b>统一多民族国家,通用汉语。中国疆域内<b >的</b>各个民族统称为<b >中华民族</b>,龙是<b >中华民族</b><b >的</b>象征。 高亮的片段是:没有根<b >的</b>野草,飘忽<b >的</b>命运
3.下面来着重说一下,高亮的第三种方式,前台高亮,散仙在上文曾提过,基于高亮的字段,必须的存储,否则无法实现高亮标注,当然这种说法,只是对于后台高亮而言的,那么对于大文本情况下,存储到索引里是非常浪费空间的,而且还有可能会影响到检索速度,所以就提出了,第三种方式。
在前台进行高亮,然后大文本字段,可以存储在外部其他的数据源里面,需要标记时,可以直接根据ID,或者某个字段,读取数据然后通过JS正则在前端替换检索的关键词即可,在这之前需要做的一步就是,使用ajax把检索的关键词,传入后台进行分词,然后将结果返回前台,进行对分词后的数据,进行匹配替换,再加上颜色标记,就可以在前台实现高亮了,这也是前台高亮的实现原理,这种做法,在某些业务场景下,可以大大减少服务器压力,通过客户端减压,以及不用再存储一些向量信息,从而对系统的性能的提高,也是有很大帮助的。
下面给出一个前台高亮的截图,注意用的是快速高亮的索引。
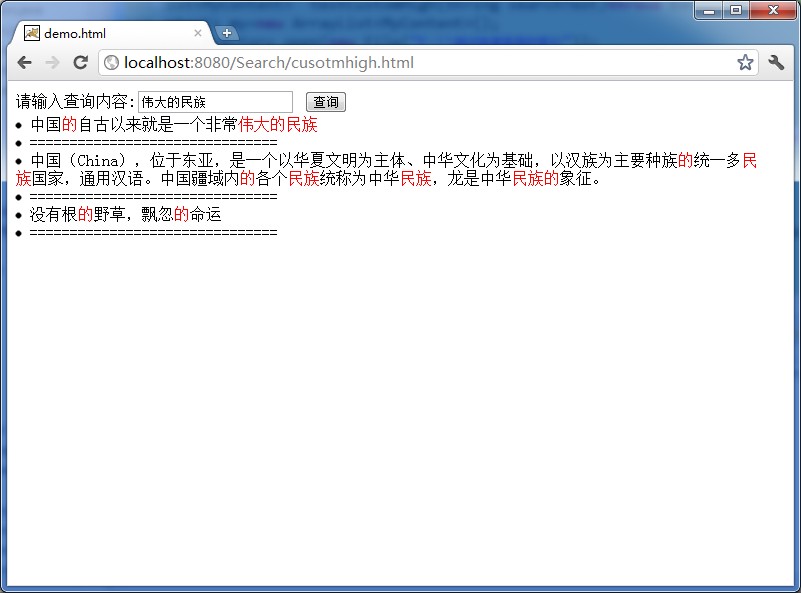
附上前台高亮的核心代码
$.ajax({
type :"post",
url: "getContent",
data:"str="+str,
dataType:"json",
async:false,
success:function(msg){
// alert(msg);
$("#div").empty();
$.each(msg, function(i, n) {
var temp="";
for(var i=0;i<shu.length;i++){
if(shu[i]!=""){
n.name=n.name.replace(new RegExp(shu[i],'g'), "<span style=\"color:red;\">"+shu[i]+"</span>");
}
}
$("#div").append("[*]"+n.name+"
");
$("#div").append("[*]===============================
")
});
}
});到此,关于“lucene4.7高亮功能怎么实现”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





