这篇文章主要介绍python如何爬取美团1024家烤肉店数据,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
https://apimobile.meituan.com/group/v4/poi/pcsearch/30?uuid=你的&userid=-1&limit=32&offset=32&cateId=-1&q=%E7%83%A4%E8%82%89主要参数:
30:城市id(30代表深圳)
limit:每页店铺数量
offset:翻页参数(每增加32翻页一次)
q:关键字(本例为烤肉)
按上述接口爬取只能获得1024个店铺数据,为了获得更全面数据,还需找到areaId参数(子地区),然后遍历子地区,即可获得完整数据。限于篇幅,仅给出核心代码。
def get_meituan():
try:
for areaId in areaId_list:
for x in range(0, 2000, 32):
time.sleep(random.uniform(2,4)) #设置睡眠时间
print('正在提取areadId为%d的'%areaId,'第%d页'%int((x+32)/32)) #打印爬取进度
url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/30?uuid=你的&userid=-1&limit=32&offset={0}&cateId=-1&q=%E7%83%A4%E8%82%89&areaId={1}'.format(x,areaId)
print(url)
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie':'你的',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'Host': 'apimobile.meituan.com',
'Origin': 'https://sr.meituan.com',
'Referer': 'https://sr.meituan.com/s/%E7%83%A4%E8%82%89/'
}
response = requests.get(url, headers=headers)
print(response.status_code)短短几分钟就爬下了2万多个烤肉店信息,为了方便可视化分析,还需要对爬取的数据进行简单清洗。
导入数据并添加列名,用sample()方法随机抽取5个样本数据预览。
import pandas as pd
import numpy as np
df = pd.read_csv('/Users/wangjia/Documents/技术公号/公号项目/2.spider/美团/深圳烤肉1.csv',
names = ['店铺名称', '店铺地址', '人均消费', '店铺评分', '评论人数', '所在商圈', '图片链接','店铺类型','联系方式'])
df.sample(5)
df = df.drop_duplicates()由上文可知,仅联系方式字段含有缺失值,用文本填充。
df = df.fillna('暂无数据')通过店铺地址字段截取所属区县,另外,“南澳大”属于龙岗区,直接用replace()方法替换。
df['所属区县'] = df['店铺地址'].str[:3].str.replace('南澳大','龙岗区')根据美团评分方法,对店铺评分字段进行切分,获得评分类型列。
cut = lambda x : '一般' if x <= 3.5 else ('不错' if x <= 4.0 else('好' if x <= 4.5 else '很好'))
df['评分类型'] = df['店铺评分'].map(cut)查看基本统计量
df.describe()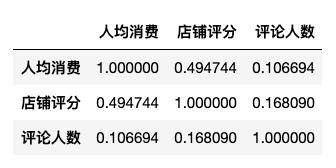
绘制回归图
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置加载的字体名
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
fig,axes=plt.subplots(2,1,figsize=(12,12))
sns.regplot(x='人均消费',y='店铺评分',data=df,color='r',marker='+',ax=axes[0])
sns.regplot(x='评论人数',y='店铺评分',data=df,color='g',marker='*',ax=axes[1])通过绘制回归图,我们发现人均消费与店铺评分具有正相关,评论人数和店铺评分具有正相关。这与我们的常识也较为接近。
本文数据可视化主要用到pyecharts库,它能轻松实现酷炫的图表效果。
深圳烤肉店主要分布在龙岗区、龙华区、南山区和福田区,盐田区和坪山区烤肉店较少。烤肉店的选址一个重要因素就是人流量,龙岗区和龙华区为深圳主要的生活居住区,而南山区和福田区为深圳的核心商业聚集地,巨大的需求为烤肉店的布局奠定了基础。
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType #引入主题
df1 = df.groupby('所属区县')['店铺名称'].count() #按所属区县分组,对店铺名称计数
df1 = df1.sort_values(ascending=False) #降序
regions = df1.index.to_list()
values = df1.to_list()
c = (
Map(init_opts=opts.InitOpts(theme = ThemeType.WONDERLAND)) #PURPLE_PASSION
.add(
"",
zip(regions, values),
maptype="深圳"
)
.set_global_opts(
title_opts=opts.TitleOpts(title="深圳烤肉店分布",subtitle="数据来源:美团",pos_top="-1%", pos_left = 'center' ),
visualmap_opts=opts.VisualMapOpts(max_=1000)
)
)
c.render_notebook()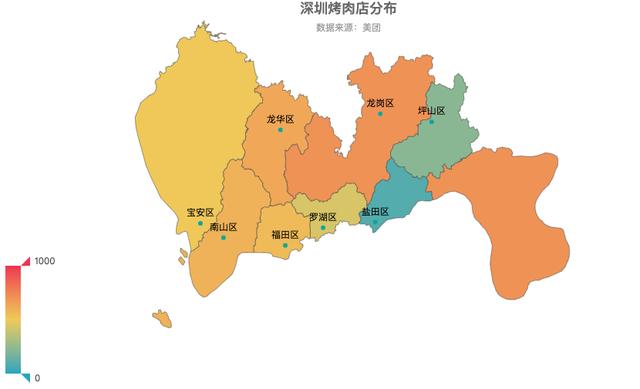
仅仅知道烤肉店行政区分布,对于烤肉店选址作用其实不大。于是,我们进一步细化到商圈,看看哪些商圈的烤肉店较多。在深圳所有商圈中,龙华区的民治和龙华、光明区的公明烤肉店数量都超过了150家。
df2 = df.groupby('所在商圈')['店铺名称'].count()
df2 = df2.sort_values(ascending=True)[-10:]
df2 = df2.round(2)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df2.index.to_list())
.add_yaxis("",df2.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="商圈烤肉店数量top10",subtitle="数据来源:美团",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()评分排行
烤肉店的评分在一定程度上反映了消费者对烤肉店的态度和看法。通过计算各个行政区烤肉店平均评分,我们发现,深圳烤肉店普遍评分不高,都在3分以下,且各地区评分差异不大。
df3 = df.groupby('所属区县')['店铺评分'].mean()
df3 = df3.sort_values(ascending=False)
df3 = df3.round(2)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df3.index.to_list())
.add_yaxis("",df3.to_list())
.set_global_opts(title_opts=opts.TitleOpts(title="各地区平均评分",subtitle="数据来源:美团",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16))
)
c.render_notebook()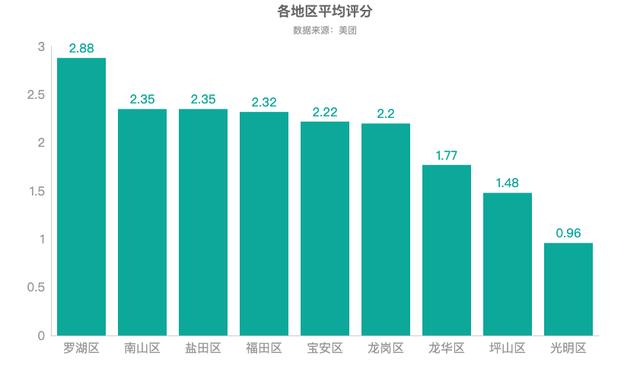
根据不同评分类型绘制饼图,我们发现深圳评分为“一般”的烤肉店数量占比高达73.9%。评分类型为“不错”的烤肉店仅占6.52%。烤肉店较低的评分意味着,作为市场的进入者,如果新开烤肉店能够提供较好的质量和服务,且获得消费者好评,将比较容易在众多烤肉店中脱颖而出。
df4 = df.groupby('评分类型')['店铺名称'].count()
df4 = df4.sort_values(ascending=False)
regions = df4.index.to_list()
values = df4.to_list()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add("", zip(regions,values))
.set_global_opts(title_opts=opts.TitleOpts(title="不同评分类型店铺数量",subtitle="数据来源:美团",pos_top="-1%",pos_left = 'center'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18))
)
c.render_notebook()我们继续将评分类型分析细化到深圳的各个行政区,罗湖区评分为“一般”的烤肉店占比相对低一些。其他地区占比都超过了一半。这进一步反映了深圳烤肉店评分的整体情况,排除了某个或某几个行政区评分异常值的影响。
h = pd.pivot_table(df,index=['评分类型'],values=['店铺名称'],
columns=['所属区县'],aggfunc=['count'])
k = h.droplevel([0,1],axis=1) #删除指定的索引/列级别
c = (
Polar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_schema(angleaxis_opts=opts.AngleAxisOpts(data=k.columns.tolist(), type_="category"))
.add("一般",h.values.tolist()[0], type_="bar", stack="stack0")
.add("不错",h.values.tolist()[1], type_="bar", stack="stack0")
.add("好", h.values.tolist()[2], type_="bar", stack="stack0")
.add("很好", h.values.tolist()[3], type_="bar", stack="stack0")
.set_global_opts(title_opts=opts.TitleOpts(title="不同地区评分情况",subtitle="数据来源:美团"))
)
c.render_notebook()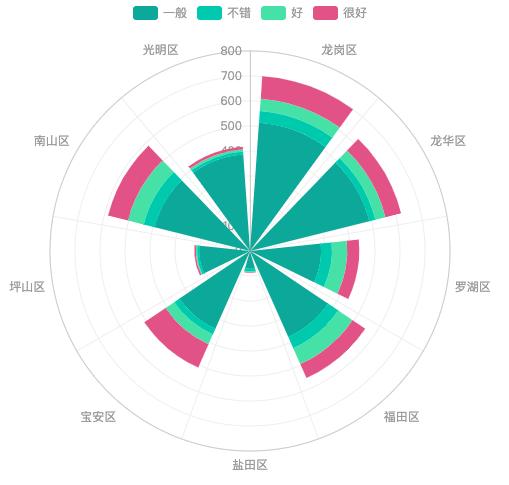
从深圳各行政区烤肉店人均消费来看,南山区和福田区人均消费较高,坪山区和光明区人均消费较低。在消费量一致的假设下,人均消费的多少取决于烤肉的价格。南山区和福田区高昂的开店成本以及消费者较强的消费能力,是烤肉人均消费较高的重要动因。
df5 = df.groupby('所属区县')['人均消费'].mean()
df5 = df5.sort_values(ascending=True)
df5 = df5.round(2)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df5.index.to_list())
.add_yaxis("",df5.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="各地区人均消费",subtitle="数据来源:美团",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()由上图可知,深圳各行政区烤肉人均消费普遍低于50元,那是不是意味着如果要开烤肉店的话,定价不能太高。为此,我们可以筛选出人均消费大于1000元的烤肉店,看下消费者的评价情况。由下表可知,虽然三家烤肉店定价很高,却获得了消费者较高的评价。因此,烤肉的定价还需根据你的市场定位来,如果定位高端人群,那么较高的价格消费者也是可以接受的。
df_1 = df[df['人均消费']>1000]
df_1[['店铺名称','人均消费','评分类型','所在商圈']]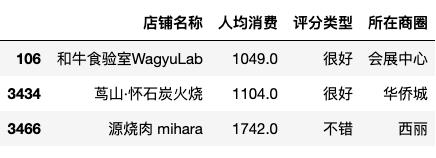
从深圳烤肉店店铺类型来看,烤串、烧烤和融合烤肉最多,韩式烤肉、日式烤肉等店铺相对更少一些。
df6 = df.groupby('店铺类型')['店铺名称'].count()
df6 = df6.sort_values(ascending=False)[:10]
df6 = df6.round(2)
regions = df6.index.to_list()
values = df6.to_list()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add("", zip(regions,values),radius=["40%", "75%"])
.set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型店铺数量",pos_top="-1%",pos_left = 'center'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}",font_size=18))
)
c.render_notebook()从评分来看,串串香、牛排和怀石料理的烤肉评分较高。另外,日式自助烤肉评分也排到了前十名,日式烤肉对肉要求比较高,日式肉类也会稍微腌制,但是总体以体现肉的鲜美为主。精致的日式烤肉,博得了众多深圳消费者的青睐。
df6 = df.groupby('店铺类型')['店铺评分'].mean()
df6 = df6.sort_values(ascending=True)
df6 = df6.round(2)
df6 = df6.tail(10)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df6.index.to_list())
.add_yaxis("",df6.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型评分",subtitle="数据来源:美团",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()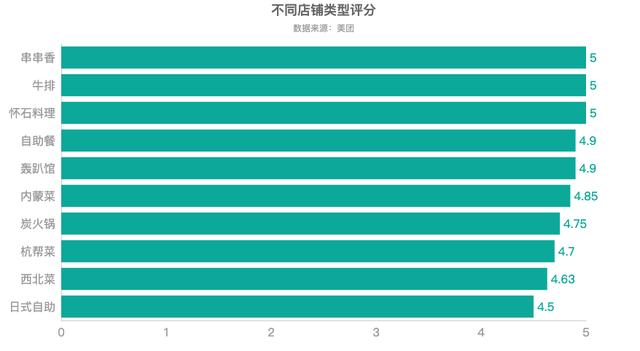
从评论人数来看,综合自助和韩式烤肉店评论人数均在10万左右,而评论人数在一定程度上反映了烤肉店的热度。不同的综合自助烤肉店一般价格和肉质差异较大,获得较多的评论也不足为奇。而韩式烤肉通常会对肉类进行腌制,口感偏重,也被深圳消费者广泛讨论。
df7 = df.groupby('店铺类型')['评论人数'].sum()
df7 = df7.sort_values(ascending=True)
df7 = df7.tail(10)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df7.index.to_list())
.add_yaxis("",df7.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型评论人数",subtitle="数据来源:美团",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()当然,开烤肉店除了要了解消费者的偏好以及竞争对手的优劣势,还一个重要步骤就是给自己开的烤肉店取名了。一个响亮的烤肉店名字,能够给消费者留下较深的记忆度,同时也能带来品牌效应。于是,J哥对深圳所有烤肉店名进行分词并绘制了词云图,发现除了烧烤、烤肉等字样,词频较高的还有音乐、木屋和炭火等。差异化市场定位,给烤肉搭配多样化的元素,在店名中凸显出来,不失为一个不错的选择。
import jieba
import stylecloud
from IPython.display import Image
# 定义分词函数
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open("./stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['', '']
for i in my_words:
jieba.add_word(i)
# 自定义停用词
my_stop_words = ['东北', '福田','公园','车公庙','梅林','购物']
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
# 绘制词云图
text1 = get_cut_words(content_series=df['店铺名称'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=1000,
collocations=False,
font_path='字酷堂清楷体.ttf',
icon_name='fas fa-shopping-bag',
size=653,
output_name='./烤肉.png')
Image(filename='./烤肉.png')
以上是“python如何爬取美团1024家烤肉店数据”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4848094/blog/4745937



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



